文本三剑客之grep的用法
- 2020 年 9 月 6 日
- 筆記
第1章 正则表达式
1.1 正则表达式的介绍
正则是用来过滤文件内容
为处理大量文本|字符串而定义的一套规则和方法。
以行为单位出来,一次处理一行。
1.2 为什么使用正则表达式
1)linux运维工作 大量过滤(找东西)日志工作。化繁为简。
2)简单,高效,易用。
3)正则表达式高级工具:三剑客 都支持。
1.3 正则表达式与通配符的比较
1)正则表达式应用非常广泛,存在于各种语言中,php perl python grep sed awk 支持。ls* 通配符。
2)但现在学的是Linux中的正则表达式,最常应用正则表达式的命令是grep(egrep)、sed、awk–>正则表达式通常只有awk、sed、grep能使用
3)正则表达式和通配符有本质区别.
4)通配符例子 ls file *.log filef.log grep “e*” e ee eeee ef
正则表达式用来找:【文件】内容,文本,字符串。高级货,三剑客。
通配符用来找什么:文件名(*.txt),或找文件,普通命令都支持。
5)不需要思考的判断方法:在三剑客awk、sed、grep egrep 都是正则,其他都是通配符。
6)区分通配符和正则表达式最简单的方法:
文件[目录]名–>通配符—–>ls *.txt
文件内容(字符串,文本,【文件】内容)–>正则表达式 grep “oldboy” oldboy.txt
7)通配符和正则表达式都有“ *”、“ ?”、“ []”,但是通配符的这些符号都能自身代表任意字符,而正则表达式的这些符号只能代表这些符号前面的字符。
1.4 正则的分类:
基础正则表达式 (BRE basic regular expression)
扩展正则表达式 (ERE extended regular expression)
注意:
中英文
[root@oldboyedu-lnb ~]# # ‘’ “” () 。 * …… ¥ | {} 【.
[root@oldboyedu-lnb ~]# '' "" () . * ^ $ | {} []
grep的别名 –color 在centos7.X 系统默认存在的
在centos6.X 系统是不存在的
在centos6.x过滤内容的时候 不会显示颜色 如何处理:
vim /etc/profile alias grep='grep --color' 使用grep命令来测试正则表达式: grep ' ' file
第2章 grep的用法
2.1 什么是grep、egrep和fgrep
-
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
-
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
-
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
-
egrep = grep -E:扩展的正则表达式 (除了< , > , \b 使用其他正则都可以去掉\)
-
fgrep=grep -F:不支持正则表达式,可以过滤普通的字符串
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行 模式:
选项:
--color=auto: 对匹配到的文本着色显示` -v: 显示不被pattern匹配到的行` -i: 忽略字符大小写 -n:显示匹配的行号
-c: 统计匹配的行数` -o: 仅显示匹配到的字符串 -q: 静默模式,不输出任何信息 -A #: after, 后#行 -B #: before, 前#行 -C #:context, 前后各#行 -e:实现多个选项间的逻辑or关系 grep –e cat -e dog file -w:匹配整个单词``-E:使用ERE -F:相当于fgrep,不支持正则表达式 -f file: 根据模式文件处理
grep实战演练:
例一
将磁盘利用率进行倒序排序:

例二
过滤root后的一行
[root@centos7 ~]# cat /etc/passwd | grep -nA1 root 1:root:x:0:0:root:/root:/bin/bash 2-bin:x:1:1:bin:/bin:/sbin/nologin -- 10:operator:x:11:0:operator:/root:/sbin/nologin 11-games:x:12:100:games:/usr/games:/sbin/nologin You have new mail in /var/spool/mail/root
过滤root的前一行
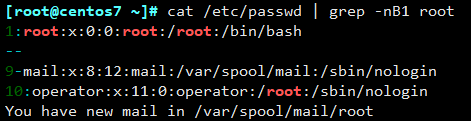
例三
过滤root的前后一行

例四
正则^
^ # 以什么开头 把以什么开头的行查找出来
查找oldboy.txt文本中以m开头的行 打印出来
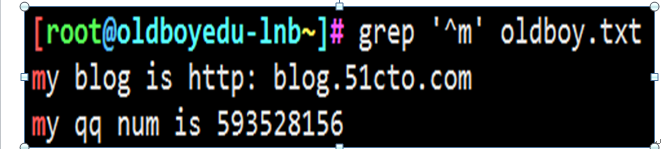
例五:正则$
$ #以什么什么结尾 把以什么结尾的行的内容输出
查找oldboy.txt中以m$结尾的行
PS: cat-A在文件的结尾处加一个结尾标志符$符号
[root@oldboyedu-lnb ~]# cat -A oldboy.txt I am lizhenya teacher!$ I teach linux.$
例6
过滤oldboy.txt中所有的空格
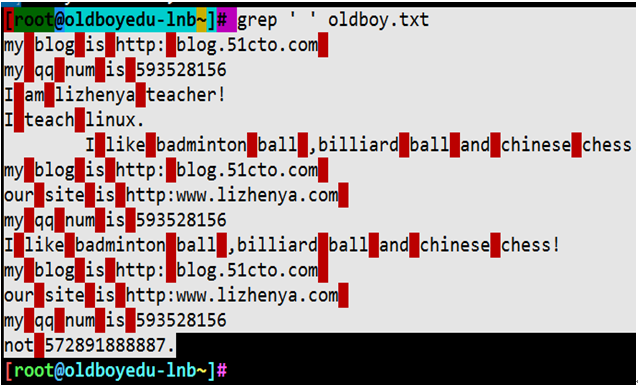
例7:过滤空行

例8
使用grep的单引号和双引号
单引号 看到什么就会过滤什么内容

例9
显示行号

例10
匹配任意单个字符 不匹配空行 匹配空格
[root@oldboyedu-lnb ~]# grep '.' oldboy.txt I am lizhenya teacher! I teach linux.
grep -o 显示grep的匹配过程
[root@oldboyedu-lnb ~]# grep '...' oldboy.txt -o I a m l izh
例11
查找以. 结尾的行

[root@oldboyedu-lnb ~]# tr "\n" "\t" < oldboy.txt
例12
* 前一个字符出现了0次或者0次以上
grep ‘8*’ oldboy.txt -o
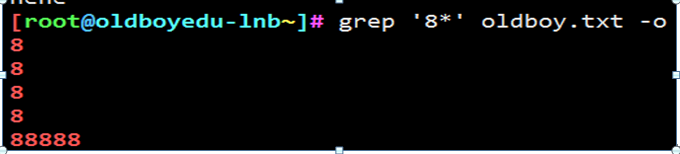
例13
.*组合使用 表示所有任何符号 显示包含空行 类似于通配符的*
特点: 贪婪匹配 有多少匹配多少
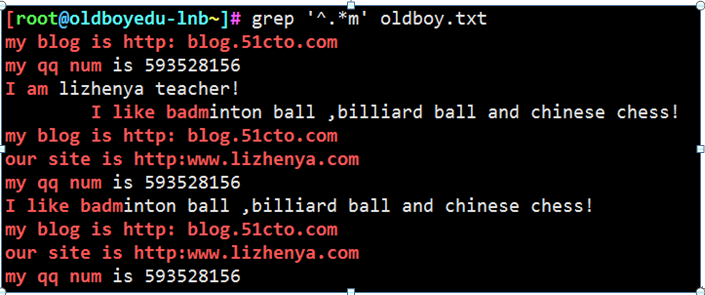
例14
以m.*结尾的行 贪婪匹配
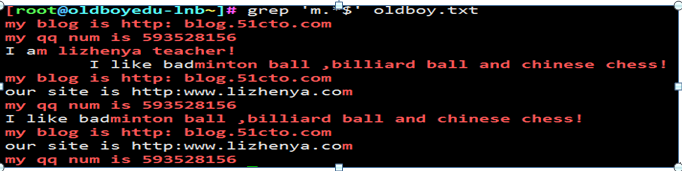
例15
正则表达式第一坑:* 如果没有过滤到内容 会显示所有的内容
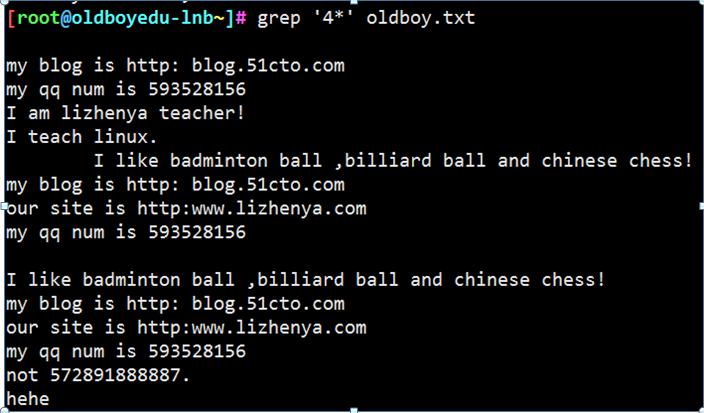
正则表达式第二坑: .* 贪婪匹配 尽可能的去匹配 相当于通配符的*
正则表达式第三坑: 神奇的[] 在中括号里的符号 大部分没有特殊的含义 写什么找什么 相当于转译符\
正则表达式第四坑 第一个尖号代表取反,第二个尖号代表自身符号,$代表本身含义
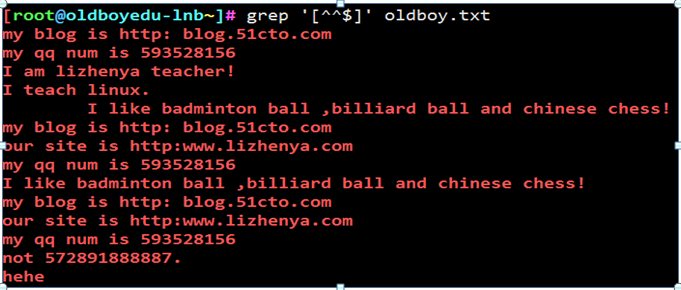
例16
第五个正则: []
[abc] 相当于是一个符号 每次匹配1个字符 找出包含a或b或c
查找oldboy.txt 中的[abc] 内容
查找[a] [b] [c]
匹配文件中包含a或b或c的行
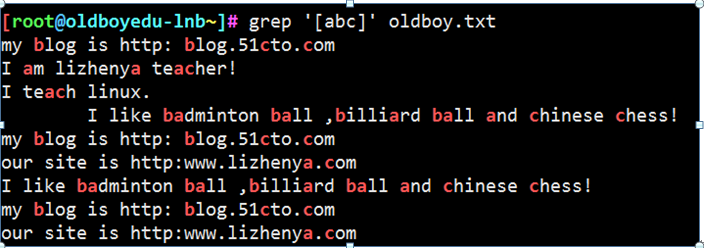
使用序列的方式查找文件内容
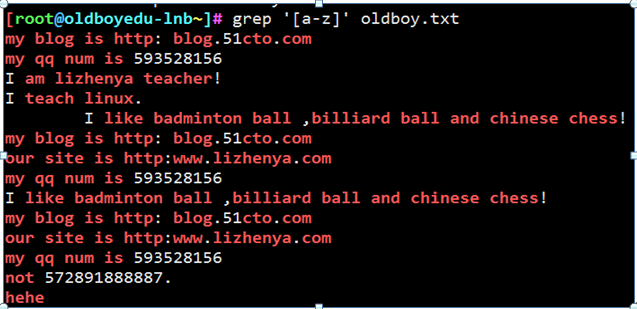
例17
匹配a-z A-Z的行

例18
grep的参数-i 不区分大小写进行过滤文件内容
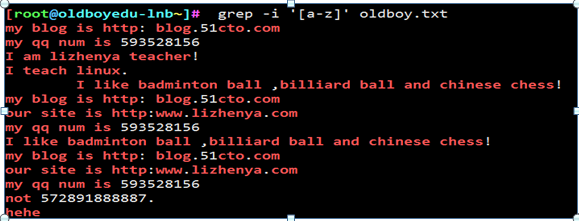
例19
匹配0-9的行 0 1 2 3 4 … 9

例20
过滤文件中的大小字母 和包含数字0-9的行
grep ‘[a-z A-Z 0-9] ’ oldboy..txt 等于grep ‘[a-Z0-9]’ oldboy.txt
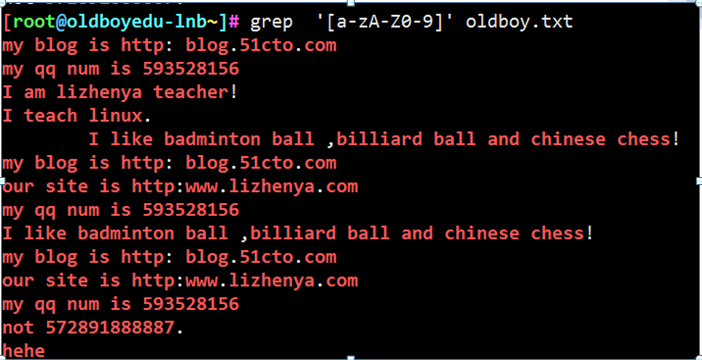
PS:通配符中的[]中也可以写多个条件 了解

例21
[]中的特殊符号 都相当于脱掉了马甲 本来的含义
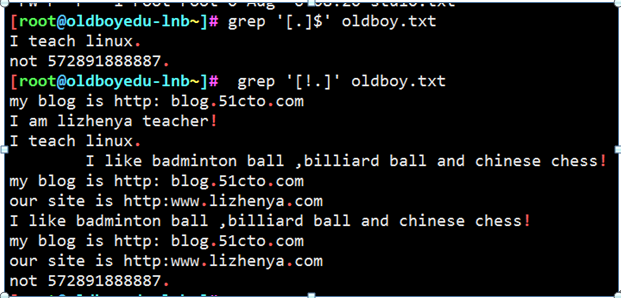
例22
查找\或者.结尾的行

例23
查找以任意单个字符加一个! 结尾的行

扩展正则
语法格式: grep 支持普通的正则表达式
egrep支持扩展的正则表达式 或者 grep -E
egrep =grep -E
^ [^ ] [^abc] 取反 排除a 排除b 排除c 中括号默认不匹配空行
. 匹配任意单个字符 [] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z] [^] 匹配指定范围外的任意单个字符 [:alnum:] 字母和数字 [:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] 小写字母 [:upper:] 大写字母 [:blank:] 空白字符(空格和制表符) [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广) [:cntrl:] 不可打印的控制字符(退格、删除、警铃...) [:digit:] 十进制数字 [:xdigit:]十六进制数字 [:graph:] 可打印的非空白字符 [:print:] 可打印字符 [:punct:] 标点符号
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧 $ 行尾锚定,用于模式的最右侧 ^PATTERN$ 用于模式匹配整行 ^$ 空行 ^[[:space:]]*$ 空白行 \< 或 \b 词首锚定,用于单词模式的左侧 \> 或 \b 词尾锚定,用于单词模式的右侧
扩展正则表达式:
(
1)字符匹配:
- . 任意单个字符
- [ ] 指定范围的字符
- [^] 不在指定范围的字符
- 次数匹配:
- \* :匹配前面字符任意次
- ? : 0 或1次
- \+ :1 次或多次
- {m} :匹配m次 次
- {m,n} :至少m ,至多n次
(2)位置锚定:
- ^ : 行首
- $ : 行尾
- \<, \b : 语首
- \>, \b : 语尾
- 分组:()
- 后向引用:\1, \2, ...
- 或者:
a|b a或b
C|cat C或cat
(C|c)at Cat或cat
(3)总结
除了\<, \b : 语首、\>, \b : 语尾;使用其他正则都可以去掉\。
显示基名

显示目录名:两次的grep为了处理两次/

1. 显示除a或b或c的所有字符
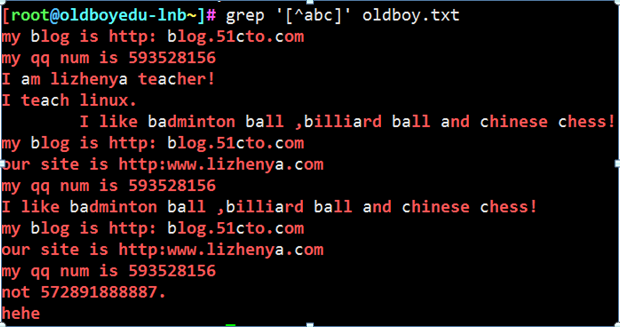
2.过滤文件中不包含^或$的行 第一个^是取反 第二个是普通符号

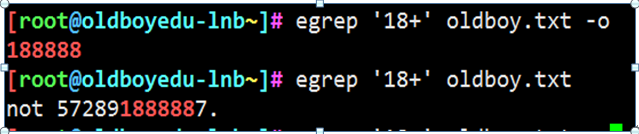
第一个扩展正则: + 前一个字符连续出现1次或1次以上
取出包含18 8连续出现1次或1次以上的行
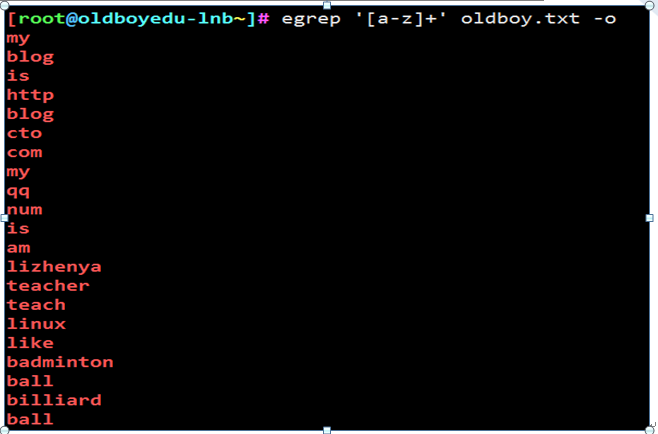
取出连续出现的字母
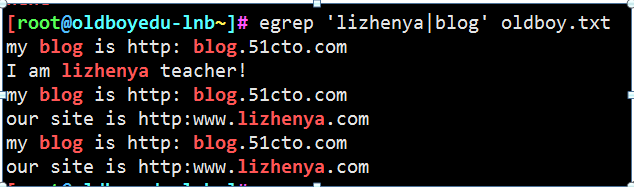
第二个扩展正则: |或者
取出包含 lizhenya和blog的行
排除文件中的#和空行 /etc/selinux/config
[root@oldboyedu-lnb ~]# egrep -v '#|^$' /etc/selinux/config SELINUX=disabled SELINUXTYPE=targeted
第三个扩展正则: {}
方法一: {n,m}前一个字符至少连续出现n次 最多出现m次
示例1: 8出现最少1次最多两次
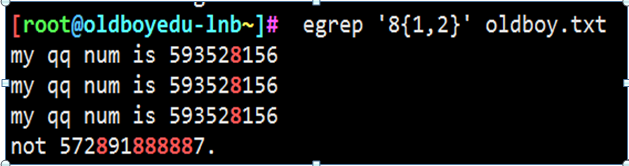
8出现最少2次最多3次

方法二: 8{3} 最多显示多少次
示例1: 8最多显示2次(只匹配两次)

第四个扩展正则: ()
()表示一个整体 反向引用/后向引用(sed 使用)
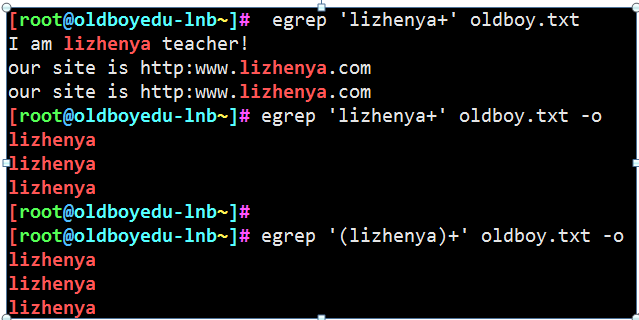
正确的写法

错误的写法: 包含lizheny或者qa的行

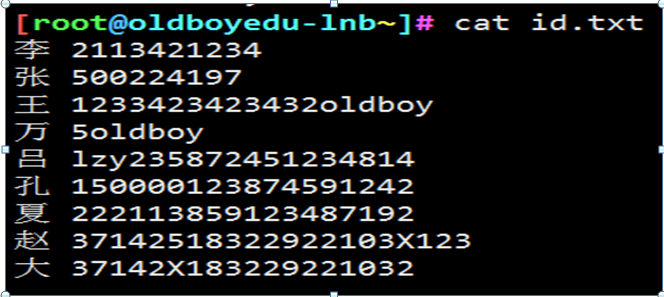
取出正确的身份证号码
[]{}
问题1
[root@oldboy~]#
孔 150000123874591242
夏 222113859123487192
赵 37142518322922103X
大 37142X183229221032

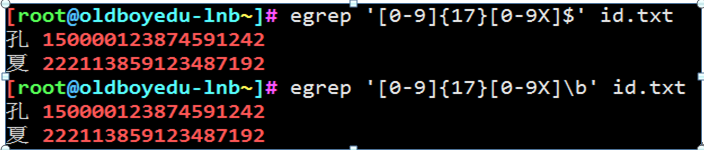
问题2:查找18位身份证号码对应的人
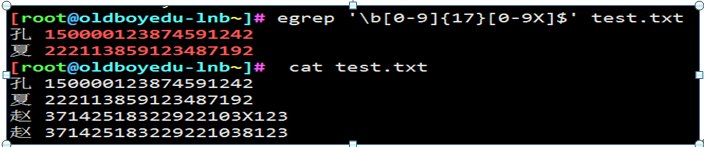
问题3: 只查找3714开头的身份证号码
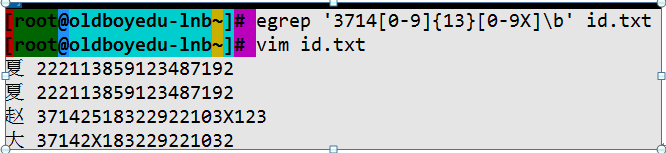
查找3714开头的身份证号码
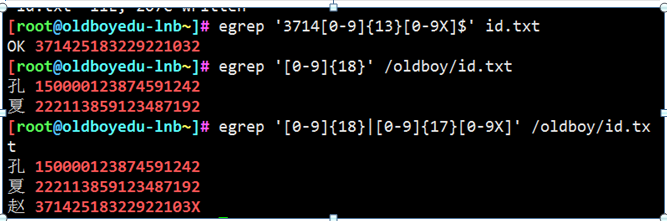
使用正则获取当前系统的IP地址
[root@oldboyedu-lnb ~]# ifconfig eth0|head -n2
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
[root@oldboyedu-lnb ~]# ifconfig eth0|head -n2|tail -1
inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
[root@oldboyedu-lnb ~]# ifconfig eth0|grep inet
inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe7d:ce prefixlen 64 scopeid 0x20<link>
[root@oldboyedu-lnb ~]# ifconfig eth0|grep '\binet\b'
inet 10.0.0.200 netmask 255.255.255.0 broadcast 10.0.0.255
方法一: [root@oldboyedu-lnb ~]# ifconfig eth0|grep '\binet\b'|egrep '[0-9.]+' -o
10.0.0.200
255.255.255.0
10.0.0.255
方法二:[root@oldboyedu-lnb ~]# ifconfig eth0|grep '\binet\b'|egrep '[0-9]+.[0-9]+.[0-9]+.[0-9]+' -o
10.0.0.200
255.255.255.0
10.0.0.255
[root@oldboyedu-lnb ~]# ifconfig eth0|grep '\binet\b'|egrep '([0-9]{1,3}.){3}[0-9]+' -o
10.0.0.200
255.255.255.0
10.0.0.255


