Elasticsearch数据迁移与集群容灾
- 2019 年 10 月 29 日
- 筆記
本文讨论如何跨集群迁移ES数据以及如何实现ES的同城跨机房容灾和异地容灾。
跨集群数据迁移
在ES的生产实践中,往往会遇到以下问题:
- 一个运行了较长时间的ES集群,因为物理设备老化,需要把数据迁移到一个使用新机器搭建的ES集群中
- 业务计划上云,要把自建的ES集群数据迁移到云厂商的ES集群中
根据业务需求,存在以下场景:
- 迁移过程中,旧的集群可以暂时停止服务或者暂停写入,数据全部迁移到新的集群中后,业务切换到新的集群进行读取和写入
- 迁移过程中,旧集群不能停止写入,业务不能停服
如果是第一种场景,数据迁移过程中可以停止写入,可以采用诸如elasticsearch-dump、logstash、reindex、snapshot等方式进行数据迁移。实际上这几种工具大体上可以分为两类:
- scroll query + bulk: 批量读取旧集群的数据然后再批量写入新集群,elasticsearch-dump、logstash、reindex都是采用这种方式
- snapshot: 直接把旧集群的底层的文件进行备份,在新的集群中恢复出来,相比较scroll query + bulk的方式,snapshot的方式迁移速度最快。
如果是第二种场景,数据迁移过程中旧集群不能停止写入,需要根据实际的业务场景解决数据一致性的问题:
- 如果业务不是直接写ES, 而是把数据写入到了中间件,比如业务->kafka->logstash->es的架构,此时可以直接采用双写的策略,旧集群不停止读写,新的集群也直接写入,然后迁移旧集群的数据到新集群中去,等数据追平之后,新的集群再提供读服务;
- 如果业务是直接写ES, 并且会进行删除doc操作;此时可以使用ES官方在6.5版本之后的CCR(跨集群复制)功能,把旧集群作为Leader, 新集群作为Follower, 旧集群不停止读写,新集群从旧集群中follow新写入的数据;另一方面使用第三方工具把存量的旧集群中的数据迁移到新集群中,存量数据迁移完毕后,业务再切换到新的集群进行读写。
数据迁移时可以停止旧集群的写入
下面介绍一下在旧集群可以停止写入的情况下进行数据迁移的几种工具的用法。
elasticsearch-dump
elasticsearch-dump是一款开源的ES数据迁移工具,github地址: https://github.com/taskrabbit/elasticsearch-dump
1 安装elasticsearch-dump
elasticsearch-dump使用node.js开发,可使用npm包管理工具直接安装:
npm install elasticdump -g
2 主要参数说明
--input: 源地址,可为ES集群URL、文件或stdin,可指定索引,格式为:{protocol}://{host}:{port}/{index} --input-index: 源ES集群中的索引 --output: 目标地址,可为ES集群地址URL、文件或stdout,可指定索引,格式为:{protocol}://{host}:{port}/{index} --output-index: 目标ES集群的索引 --type: 迁移类型,默认为data,表明只迁移数据,可选settings, analyzer, data, mapping, alias
3 迁移单个索引
以下操作通过elasticdump命令将集群172.16.0.39中的companydatabase索引迁移至集群172.16.0.20。注意第一条命令先将索引的settings先迁移,如果直接迁移mapping或者data将失去原有集群中索引的配置信息如分片数量和副本数量等,当然也可以直接在目标集群中将索引创建完毕后再同步mapping与data
elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=settings elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=mapping elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=data
4 迁移所有索引:以下操作通过elasticdump命令将将集群x.x.x.1中的所有索引迁移至集群x.x.x.2。 注意此操作并不能迁移索引的配置如分片数量和副本数量,必须对每个索引单独进行配置的迁移,或者直接在目标集群中将索引创建完毕后再迁移数据
elasticdump --input=http://x.x.x.1:9200 --output=http://x.x.x.2:9200
logstash
logstash支持从一个ES集群中读取数据然后写入到另一个ES集群,因此可以使用logstash进行数据迁移,具体的配置文件如下:
input { elasticsearch { hosts => ["http://x.x.x.1:9200"] index => "*" docinfo => true } } output { elasticsearch { hosts => ["http://x.x.x.2:9200"] index => "%{[@metadata][_index]}" } }
上述配置文件将源ES集群的所有索引同步到目标集群中,当然可以设置只同步指定的索引,logstash的更多功能可查阅logstash官方文档 logstash 官方文档.
reindex
reindex是Elasticsearch提供的一个api接口,可以把数据从一个集群迁移到另外一个集群。
1 配置reindex.remote.whitelist参数
需要在目标ES集群中配置该参数,指明能够reindex的远程集群的白名单
2 调用reindex api
以下操作表示从源ES集群中查询名为test1的索引,查询条件为title字段为elasticsearch,将结果写入当前集群的test2索引
POST _reindex { "source": { "remote": { "host": "http://x.x.x.1:9200" }, "index": "test1", "query": { "match": { "title": "elasticsearch" } } }, "dest": { "index": "test2" } }
snapshot
snapshot api是Elasticsearch用于对数据进行备份和恢复的一组api接口,可以通过snapshot api进行跨集群的数据迁移,原理就是从源ES集群创建数据快照,然后在目标ES集群中进行恢复。需要注意ES的版本问题:
- 目标ES集群的主版本号(如5.6.4中的5为主版本号)要大于等于源ES集群的主版本号;
- 1.x版本的集群创建的快照不能在5.x版本中恢复;
1 源ES集群中创建repository
创建快照前必须先创建repository仓库,一个repository仓库可以包含多份快照文件,repository主要有一下几种类型
fs: 共享文件系统,将快照文件存放于文件系统中 url: 指定文件系统的URL路径,支持协议:http,https,ftp,file,jar s3: AWS S3对象存储,快照存放于S3中,以插件形式支持(repository-s3) hdfs: 快照存放于hdfs中,以插件形式支持(repository-hdfs) cos: 快照存放于腾讯云COS对象存储中,以插件形式支持(repository-cos)
以repository-cos为例,创建仓库:
PUT _snapshot/my_cos_backup { "type": "cos", "settings": { "app_id": "xxxxxxx", "access_key_id": "xxxxxx", "access_key_secret": "xxxxxxx", "bucket": "xxxxxx", "region": "ap-guangzhou", "compress": true, "chunk_size": "500mb", "base_path": "/" } }
2 源ES集群中创建snapshot
调用snapshot api在创建好的仓库中创建快照
curl -XPUT http://x.x.x.1:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true
创建快照可以指定索引,也可以指定快照中包含哪些内容,具体的api接口参数可以查阅官方文档官方文档
3 目标ES集群中创建repository
目标ES集群中创建仓库和在源ES集群中创建仓库类似,用户可在腾讯云上创建COS对象bucket, 将仓库建在COS的某个bucket下。
4 移动源ES集群snapshot至目标ES集群的仓库
把源ES集群创建好的snapshot上传至目标ES集群创建好的仓库中
5 从快照恢复
curl -XPUT http://x.x.x.2:9200/_snapshot/my_backup/snapshot_1/_restore
6 查看快照恢复状态
curl http://x.x.x.2:9200/_snapshot/_status
数据迁移时不能停止旧集群的写入
如果旧集群不能停止写入,此时进行在线数据迁移,需要保证新旧集群的数据一致性。目前看来,除了官方提供的CCR功能,没有成熟的可以严格保证数据一致性的在线数据迁移方法。此时可以从业务场景出发,根据业务写入数据的特点选择合适的数据迁移方案。
一般来说,业务写入数据的特点有以下几种:
- add only, 只追加新数据,比如日志、APM场景中,数据基本都是时序数据,只会追加,没有更新、删除数据的操作
- add & update, 数据有追加也有更新,但是没有删除数据的操作
- add & update & delete, 数据有追加,也有更新和删除,搜索场景比较常见
下面来具体分析不同的写入数据的特点下,该如何选择合适的数据迁移方式。
add only
在日志或者APM的场景中,数据都是时序数据,一般索引也都是按天创建的,当天的数据只会写入当前的索引中。此时,可以先把存量的不再写入的索引数据一次性同步到新集群中,然后使用logstash或者其它工具增量同步当天的索引,待数据追平后,把业务对ES的访问切换到新集群中。
具体的实现方案为:
- 全量迁移冷索引 因为冷的索引不再写入,可以采用elasticdump、logstash、reindex进行迁移;如果数据量比较大的情况下,可以采用snapshot方式进行迁移。
- 增量迁移热索引
add only的数据写入方式,可以按照数据写入的顺序(根据_doc进行排序,如果有时间戳字段也可以根据时间戳排序)批量从旧集群中拉取数据,然后再批量写入新集群中;可以通过写程序,使用用scroll api 或者search_after参数批量拉取增量数据,再使用bulk api批量写入。
使用scroll拉取增量数据:
POST {my_index}/_search?scroll=1m { "size":"100", "query": { "range": { "timestamp": { "gte": "now-1m", "lt": "now/m" } } } } POST _search/scroll { "scroll": "1m", "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAHCbaFndPR3J4bDJtVDh1bnNRaW5yYWZBWncAAAAAABwm2RZ3T0dyeGwybVQ4dW5zUWlucmFmQVp3AAAAAAAcJtwWd09HcnhsMm1UOHVuc1FpbnJhZkFadwAAAAAAHCbbFndPR3J4bDJtVDh1bnNRaW5yYWZBWncAAAAAABwm3RZ3T0dyeGwybVQ4dW5zUWlucmFmQVp3" }
上述操作可以每分钟执行一次,拉起前一分钟新产生的数据,所以数据在旧集群和新集群的同步延迟为一分钟。
使用search_after批量拉取增量数据:
POST {my_index}/_search { "size":100, "query": { "match_all": {} }, "search_after": [ 1569556667000 ], "sort": "timestamp" }
上述操作可以根据需要自定义事件间隔执行,每次执行时修改search_after参数的值,获取指定值之后的多条数据;search_after实际上相当于一个游标,每执行一次向前推进,从而获取到最新的数据。
使用scroll和search_after的区别是:
- scroll相当于对数据做了一份快照,快照会保存在内存中,会比较消耗资源;search_after是无状态的,并不会过多的消耗内存资源。
- scroll可以分批次执行,search_after获取到的结果只能一次拉取完,所以需要合理控制search_after参数的值以及size的大小,以免出现一次拉取过多的数据导致内存暴涨。
- scroll执行过程中并不能获取到更新后的数据(对add only的场景并无影响),search_after每次拉取到的数据都是最新的。
另外,如果不想通过写程序迁移旧集群的增量数据到新集群的话,可以使用logstash结合scroll进行增量数据的迁移,可参考的配置文件如下:
input { elasticsearch { hosts => "x.x.x.1:9200" index => "my_index" query => '{"query":{"range":{"timestamp":{"gte":"now-1m","lt":"now/m"}}}}' size => 100 scroll => "1m" docinfo => true schedule => "*/1 * * * *" #定时任务,每分钟执行一次 } } output { elasticsearch { hosts => "x.x.x.2:9200" index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}" } }
使用过程中可以根据实际业务的需求调整定时任务参数schedule以及scroll相关的参数。
add & update
业务场景如果是写入ES时既有追加,又有存量数据的更新,此时比较重要的是怎么解决update操作的数据同步问题。对于新增的数据,可以采用上述介绍的增量迁移热索引的方式同步到新集群中。对于更新的数据,此时如果索引有类似于updateTime的字段用于标记数据更新的时间,则可以通过写程序或者logstash,使用scroll api根据updateTime字段批量拉取更新的增量数据,然后再写入到新的集群中。
可参考的logstash配置文件如下:
input { elasticsearch { hosts => "x.x.x.1:9200" index => "my_index" query => '{"query":{"range":{"updateTime":{"gte":"now-1m","lt":"now/m"}}}}' size => 100 scroll => "1m" docinfo => true schedule => "*/1 * * * *" #定时任务,每分钟执行一次 } } output { elasticsearch { hosts => "x.x.x.2:9200" index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}" } }
实际应用各种,同步新增(add)的数据和更新(update)的数据可以同时进行。但是如果索引中没有类似updateTime之类的字段可以标识出哪些数据是更新过的,目前看来并没有较好的同步方式,可以采用CCR来保证旧集群和新集群的数据一致性。
add & update & delete
如果业务写入ES时既有新增(add)数据,又有更新(update)和删除(delete)数据,可以采用6.5之后商业版X-pack插件中的CCR功能进行数据迁移。但是使用CCR有一些限制,必须要注意:
- 旧集群和新集群的版本必须都在6.5及以上才能使用
- Leader Index必须开启index.soft_deletes.enabled, 否则不能使用CCR, 该参数的意义是打开后Leader Index中的所有操作都会被暂存下来,Follower Index 可以通过pull这些操作然后进行重放,从而达到数据同步的目的;另外index.soft_deletes.enabled也只能在6.5之后的版本使用,并且只能在创建索引时开启,如果没有开启的话可以通过reindex到新的索引解决。
具体的使用方式如下:
1 在新集群中配置旧集群的地址,注意必须为transport端口
PUT /_cluster/settings { "persistent" : { "cluster" : { "remote" : { "leader" : { "seeds" : [ "x.x.x.1:9300" ] } } } } }
2 创建Leader Index
PUT my_leader_indx { "settings":{ "index.soft_deletes.enabled": true } }
3 创建Follower Index
PUT my_follower_index/_ccr/follow?wait_for_active_shards=1 { "remote_cluster" : "leader", "leader_index" : "my_leader_indx" }
4 查看Follower Index统计信息
GET my_follower_index/_ccr/stats
使用中间件进行双写
如果业务是通过中间件如kafka把数据写入到ES, 则可以使用如下图中的方式,使用logstash消费kafka的数据到新集群中,在旧集群和新集群数据完全追平之后,可以切换到新集群进行业务的查询,之后再对旧的集群下线处理。
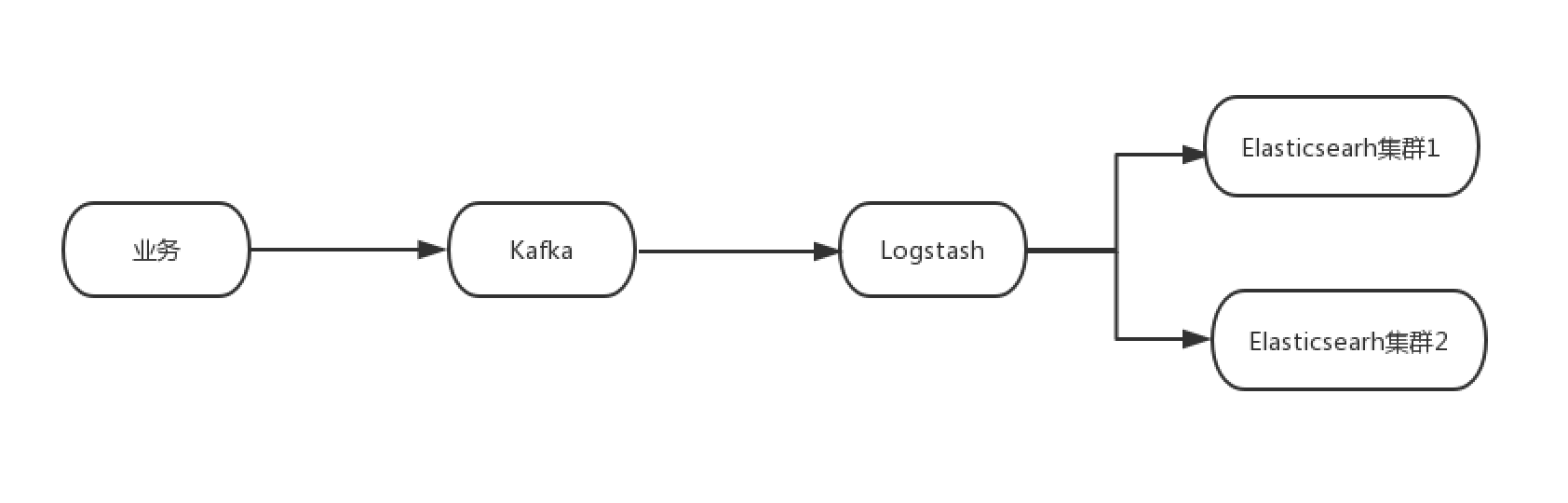
使用中间件进行同步双写的优点是:
- 写入过程中丢失数据风险较低
- 可以保证新旧集群的数据一致性
当然,双写也可以使用其他的方式解决,比如自建proxy,业务写入时向proxy写入,proxy把请求转发到一个或者多个集群中,但是这种方式存在以下问题:
- proxy的性能会影响数据写入的性能
- proxy故障可能会丢失数据,需要有一套完善的机制保证proxy的可用性
Elasticsearch跨机房容灾
随着业务规模的增长,业务侧对使用的ES集群的数据可靠性、集群稳定性等方面的要求越来越高,所以要比较好的集群容灾方案支持业务侧的需求。
同城跨机房容灾:主备集群
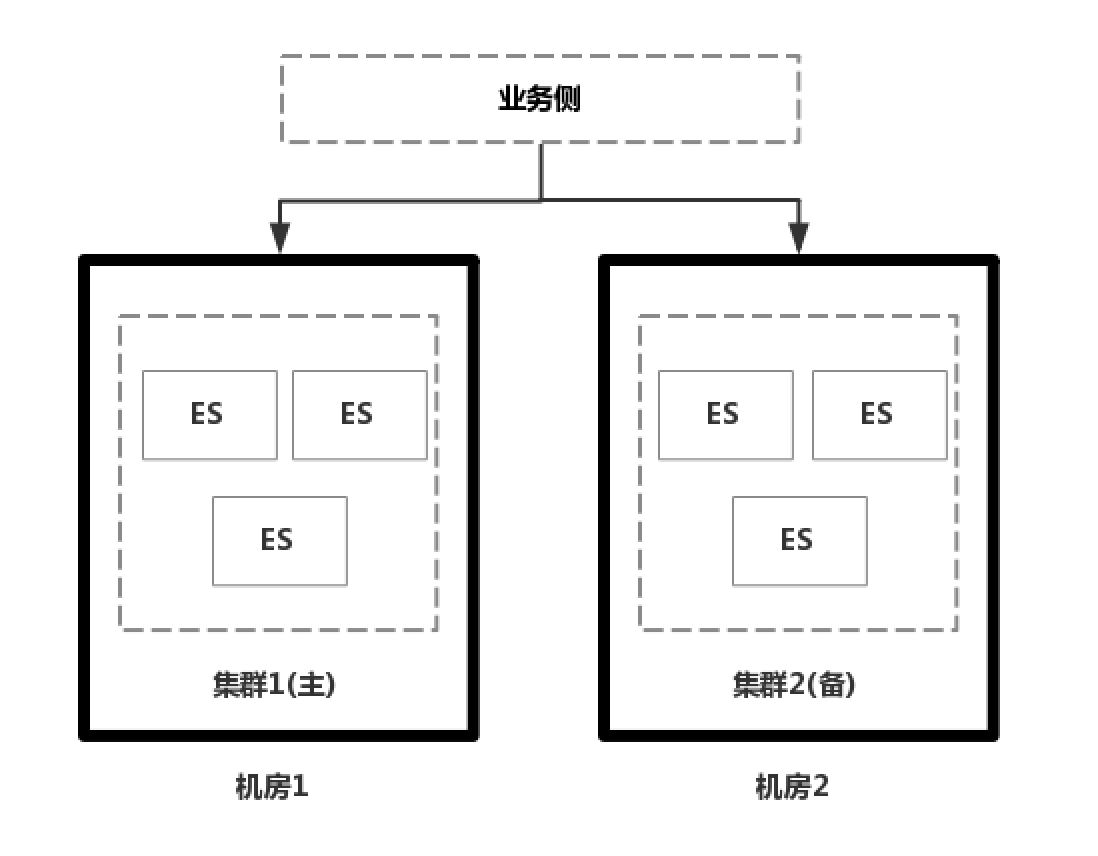
如果是公司在自建IDC机房内,通过物理机自己搭建的ES集群,在解决跨机房容灾的时候,往往会在两个机房 部署两个ES集群,一主一备,然后解决解决数据同步的问题;数据同步一般有两种方式,一种方式双写,由业务侧实现双写保证数据一致性,但是双写对业务侧是一个挑战,需要保证数据在两个集群都写成功才能算成功。另外一种方式是异步复制,业务侧只写主集群,后台再把数据同步到备集群中去,但是比较难以保证数据一致性。第三种方式是通过专线打通两个机房,实现跨机房部署,但是成本较高。
同城跨机房容灾:跨机房部署集群
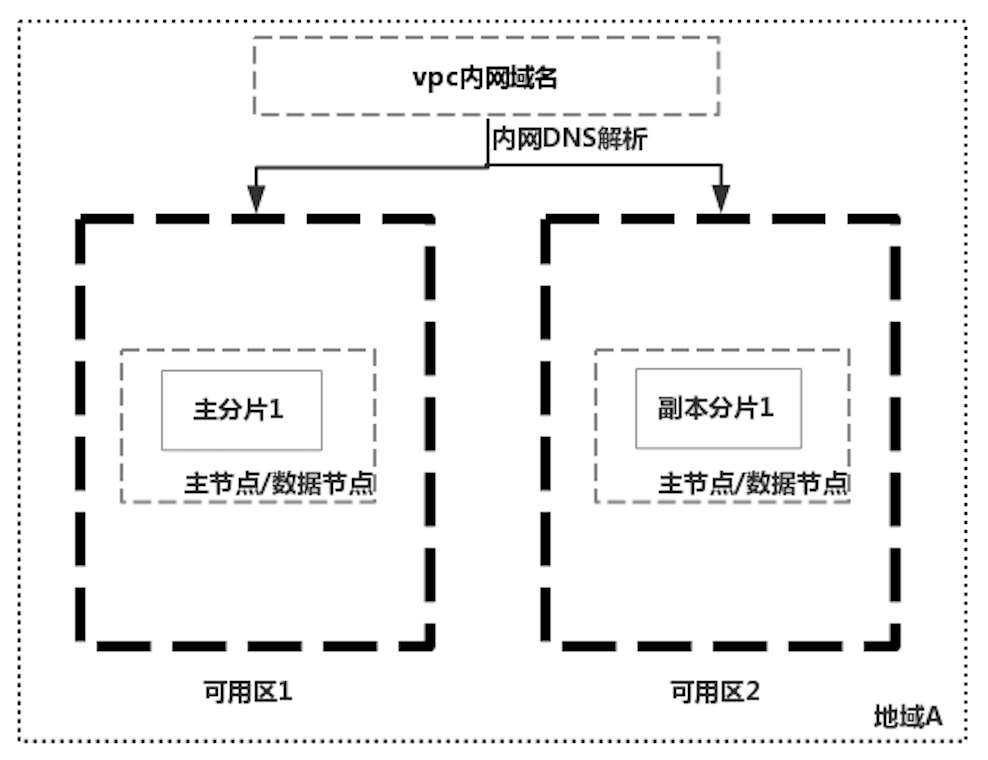
因为数据同步的复杂性,云厂商在实现ES集群跨机房容灾的时候,往往都是通过只部署一个集群解决,利用ES自身的能力同步数据。国外某云厂商实现跨机房部署ES集群的特点1是不强制使用专用主节点,如上图中的一个集群,只有两个节点,既作为数据节点也作为候选主节点;主分片和副本分片分布在两个可用区中,因为有副本分片的存在,可用区1挂掉之后集群仍然可用,但是如果两个可用区之间网络中断时,会出现脑裂的问题。如下图中使用三个专用主节点,就不会存在脑裂的问题了。
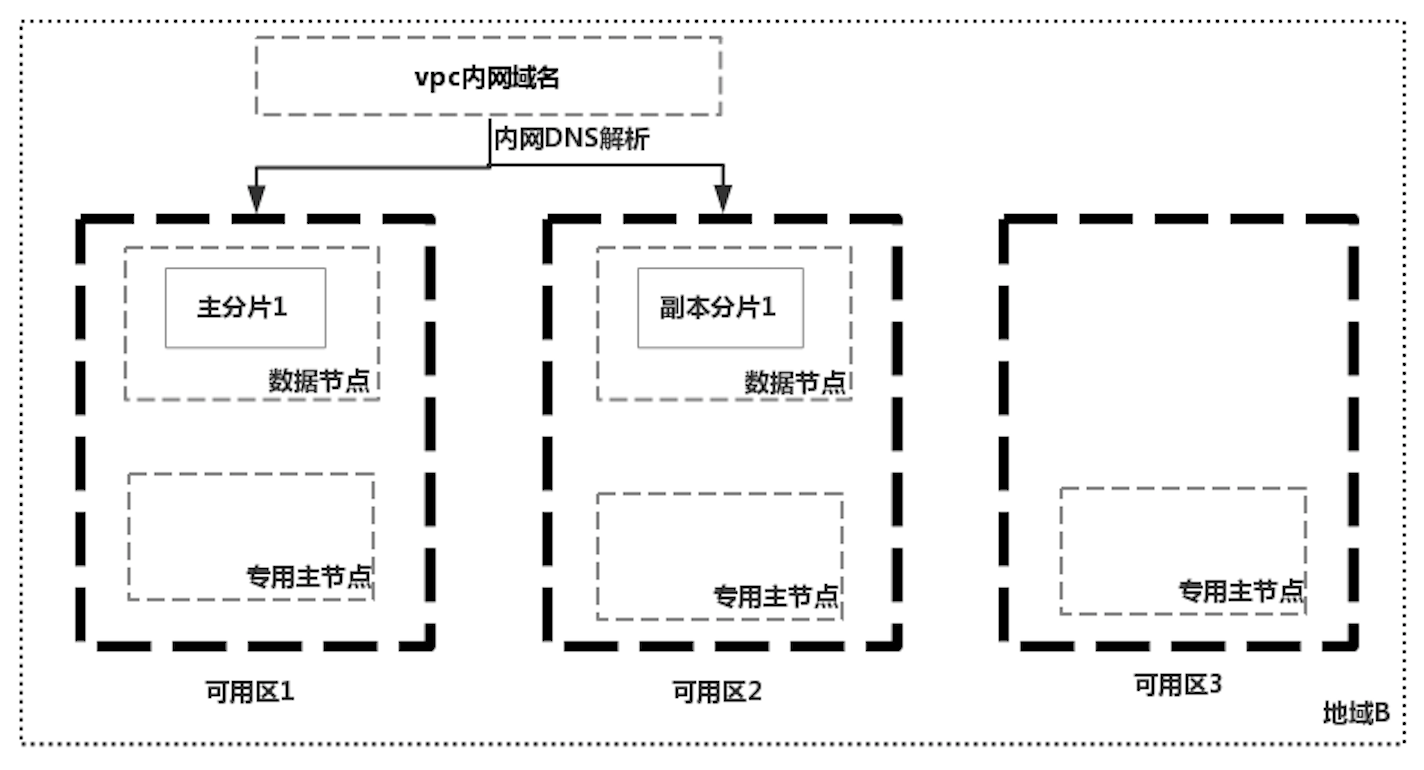
但是如果一个地域没有三个可用区怎么办呢,那就只能在其中一个可用区中放置两个专用主节点了,如国内某云厂商的解决方案:
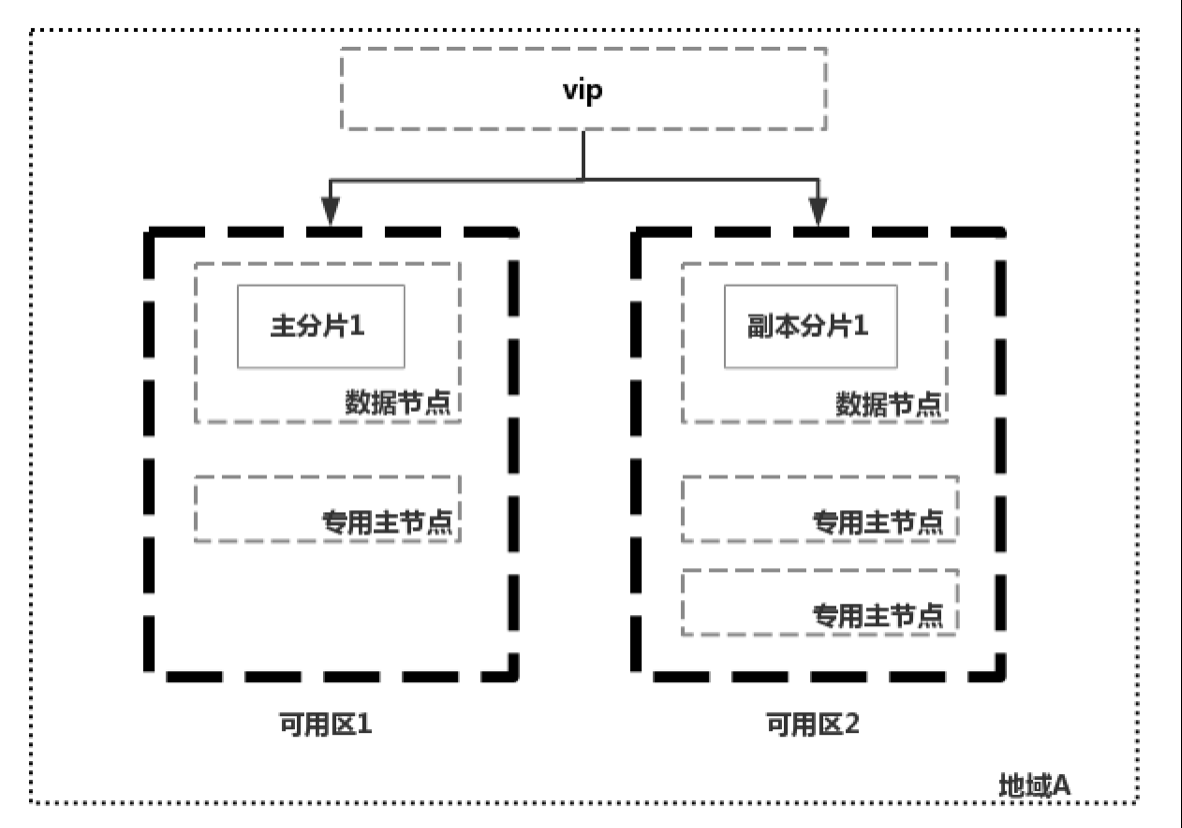
国内某云厂商的做法是不管当前地域有几个可用区,只要用户只选择在两个可用区创建集群,那集群的节点必然只分布在两个可用区中。但是这样会引发集群无法选主的问题。比如上图中的集群,如果可用区2挂掉,就只剩一个主节点了,不能满足quorum法定票数, 无法选主了,这时候集群就不可用了。针对可能发生的脑裂和无法选主这两个问题,国外某云厂商和国内某云厂商的解决办法是进行故障恢复,重建节点。
但是重建节点的过程还是存在问题的,如上图中,集群本身的quorum应该为2,可用区1挂掉后,集群中只剩一个专用主节点,需要把quorum参数(discovery.zen.minimum_master_nodes)调整为1后集群才能够正常进行选主,等挂掉的两个专用主节点恢复之后,需要再把quorum参数(discovery.zen.minimum_master_nodes)调整为2,以避免脑裂的发生。
当然还是有可以把无法选主和脑裂这两个可能发生的问题规避掉的解决方案,如下图中国内某云厂商的解决思路:
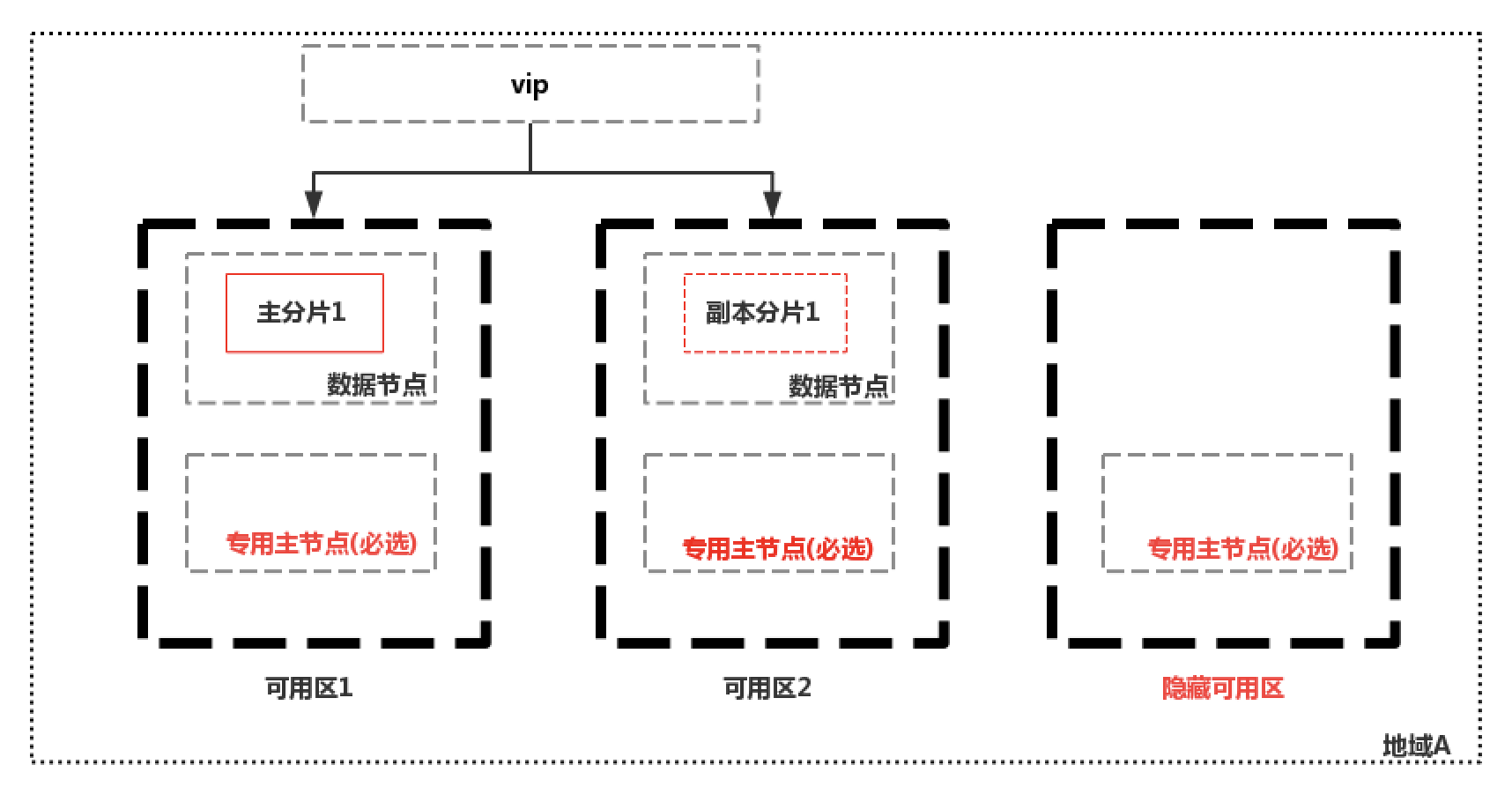
创建双可用区集群时,必须选择3个或者5个专用主节点,后台会在一个隐藏的可用区中只部署专用主节点;方案的优点1是如果一个可用区挂掉,集群仍然能够正常选主,避免了因为不满足quorum法定票数而无法选主的情况;2是因为必须要选择三个或5个专用主节点,也避免了脑裂。
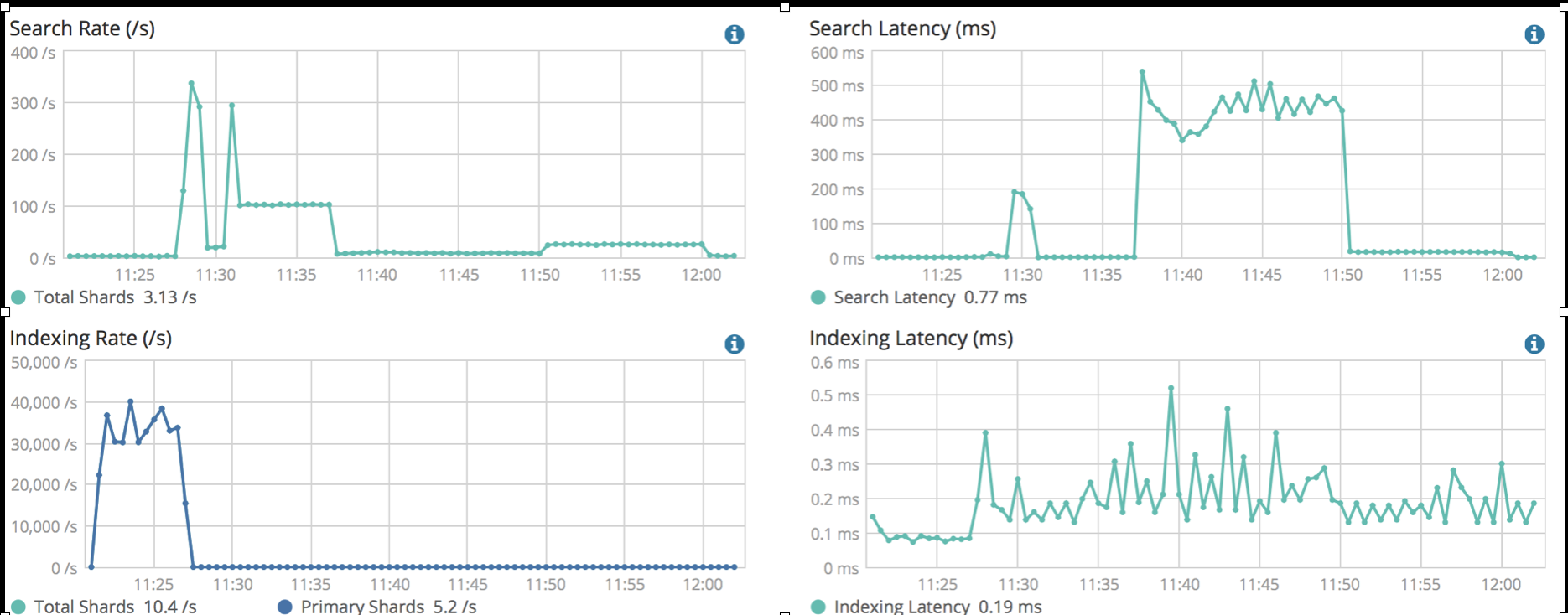
想比较一主一备两个集群进行跨机房容灾的方式,云厂商通过跨机房部署集群把原本比较复杂的主备数据同步问题解决了,但是,比较让人担心的是,机房或者可用区之间的网络延迟是否会造成集群性能下降。这里针对腾讯云的双可用区集群,使用标准的benchmark工具对两个同规格的单可用区和双可用区集群进行了压测,压测结果如下图所示:
- 多可用区集群:
- 单可用区集群:
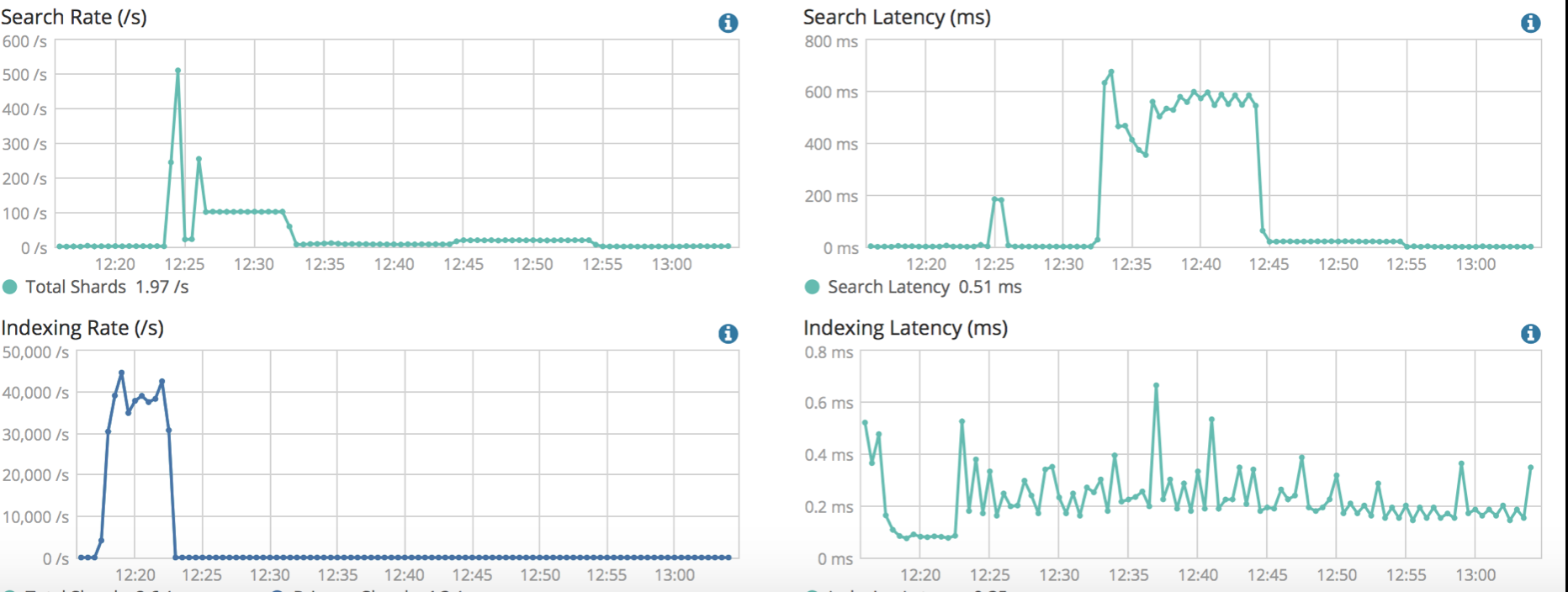
从压测结果的查询延时和写入延时指标来看,两种类型的集群并没有明显的差异,这主要得益与云上底层网络基础设施的完善,可用区之间的网络延迟很低。
异地容灾:主备集群
类似于同城跨机房容灾,异地容灾一般的解决思路是在异地两个机房部署一主一备两个集群。业务写入时只写主集群,再异步地把数据同步到备集群中,但是实现起来会比较复杂,因为要解决主备集群数据一致性的问题,并且跨地域的话,网络延迟会比较高;还有就是,当主集群挂掉之后,这时候切换到备集群,可能两边数据还没有追平,出现不一致,导致业务受损。当然,可以借助于kafka等中间件实现双写,但是数据链路增加了,写入延迟也增加了,并且kafka出现问题,故障可能就是灾难性的了。
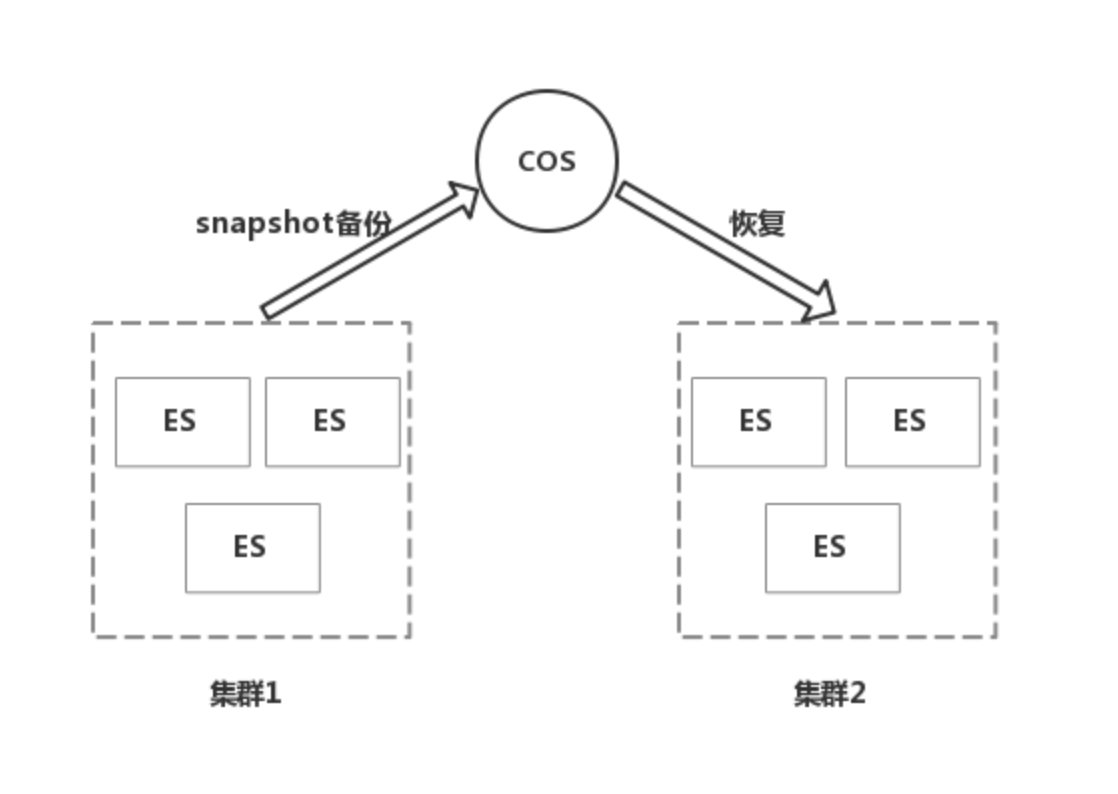
一种比较常见的异步复制方法是,使用snapshot备份功能,定期比如每个小时在主集群中执行一次备份,然后在备集群中进行恢复,但是主备集群会有一个小时的数据延迟。以腾讯云为例,腾讯云的ES集群支持把数据备份到对象存储COS中,因为可以用来实现主备集群的数据同步,具体的操作步骤可以参考https://cloud.tencent.com/document/product/845/19549。
在6.5版本官方推出了CCR功能之后,集群间数据同步的难题就迎刃而解了。可以利用CCR来实现ES集群的异地容灾:
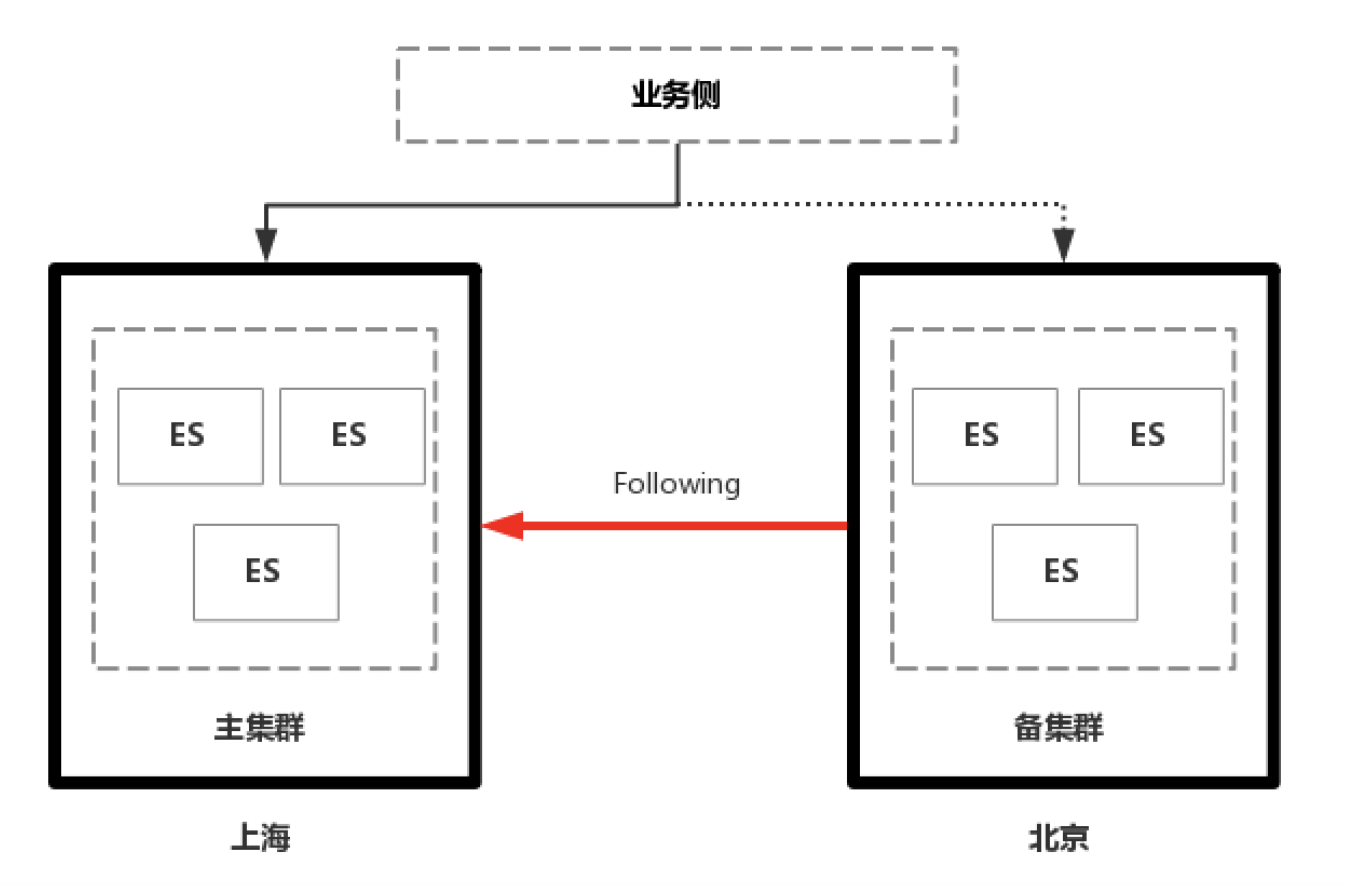
CCR是类似于数据订阅的方式,主集群为Leader, 备集群为Follower, 备集群以pull的方式从主集群拉取数据和写请求;在定义好Follwer Index时,Follwer Index会进行初始化,从Leader中以snapshot的方式把底层的segment文件全量同步过来,初始化完成之后,再拉取写请求,拉取完写请求后,Follwer侧进行重放,完成数据的同步。CCR的优点当然是因为可以同步UPDATE/DELETE操作,数据一致性问题解决了,同步延时也减小了。
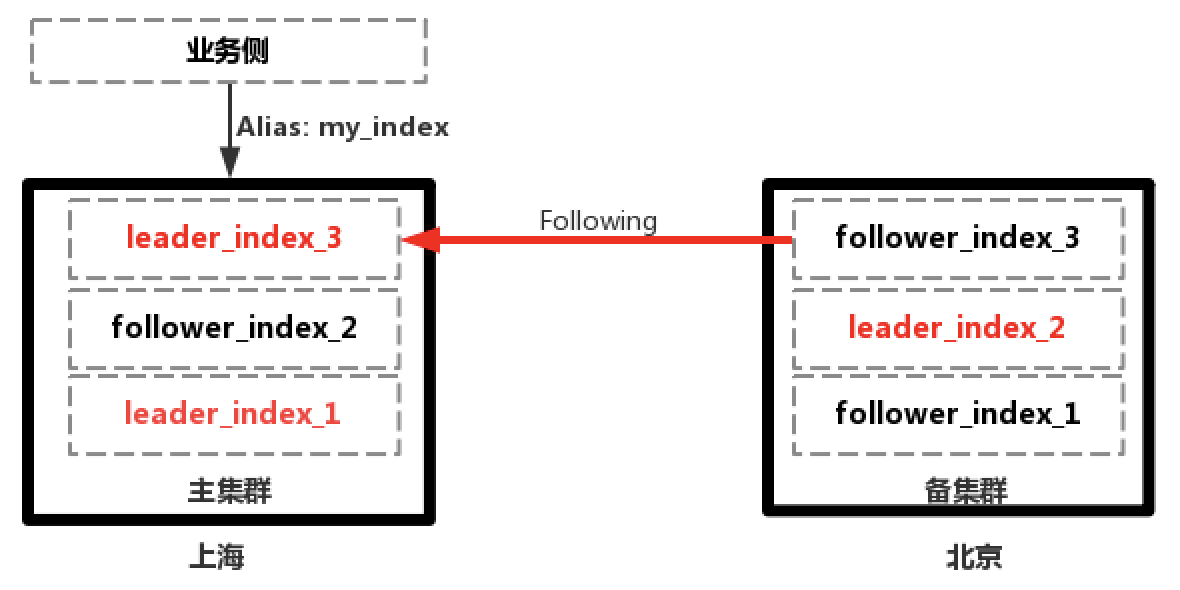
另外,基于CCR可以和前面提到的跨机房容灾的集群结合,实现两地多中心的ES集群。在上海地域,部署有多可用区集群实现跨机房的高可用,同时在北京地域部署备集群作为Follwer利用CCR同步数据,从而在集群可用性上又向前走了一步,既实现了同城跨机房容灾,又实现了跨地域容灾。
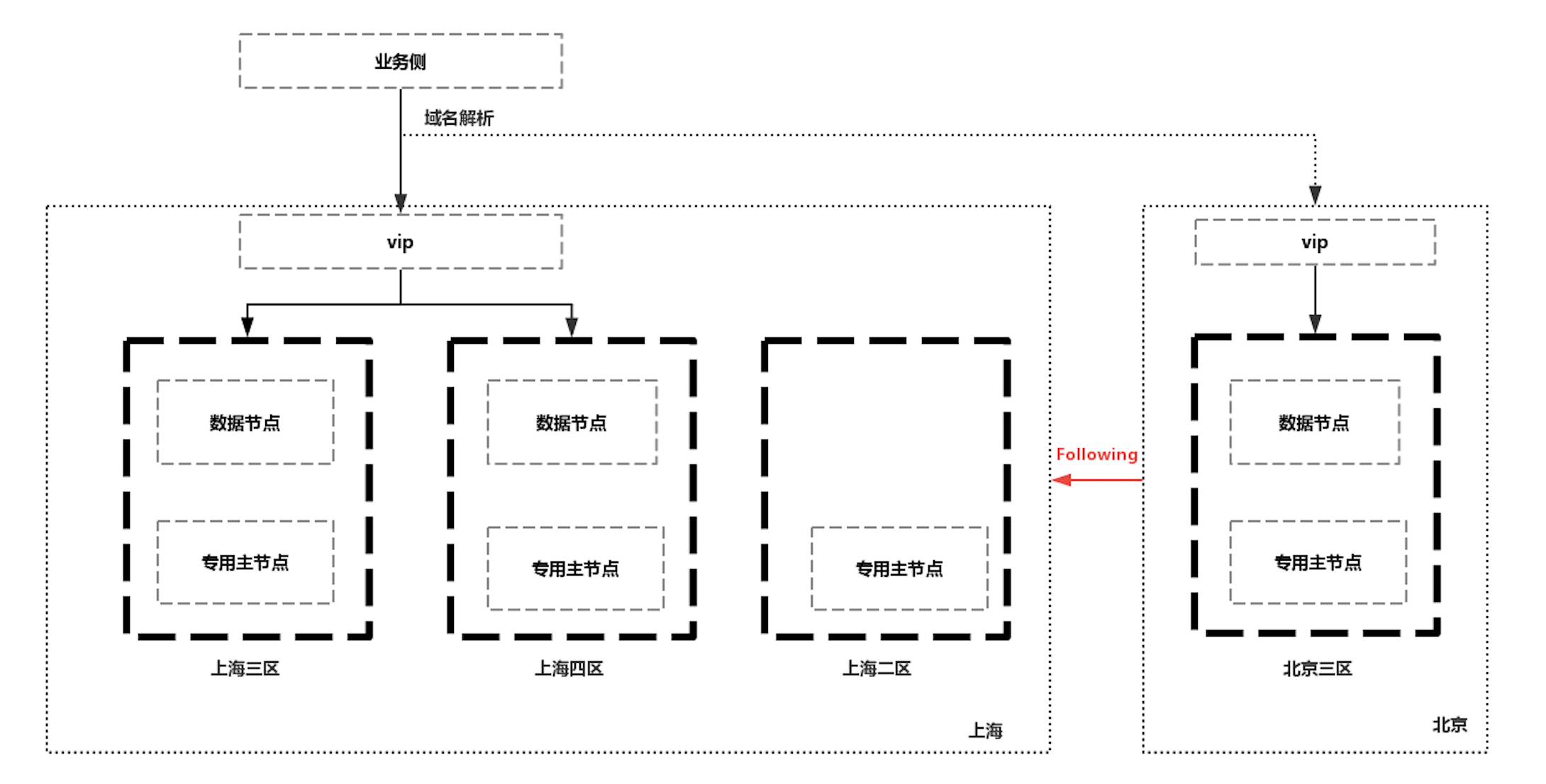
但是在出现故障时需要把集群的访问从上海切换到北京时,会有一些限制,因为CCR中的Follwer Index是只读的,不能写入,需要切换为正常的索引才能进行写入,过程也是不可逆的。不过在业务侧进行规避,比如写入时使用新的正常的索引,业务使用别名进行查询,当上海地域恢复时,再反向的把数据同步回去。
POST /<follower_index>/_ccr/pause_follow POST /<follower_index>/_close POST /<follower_index>/_ccr/unfollow POST /<follower_index>/_open
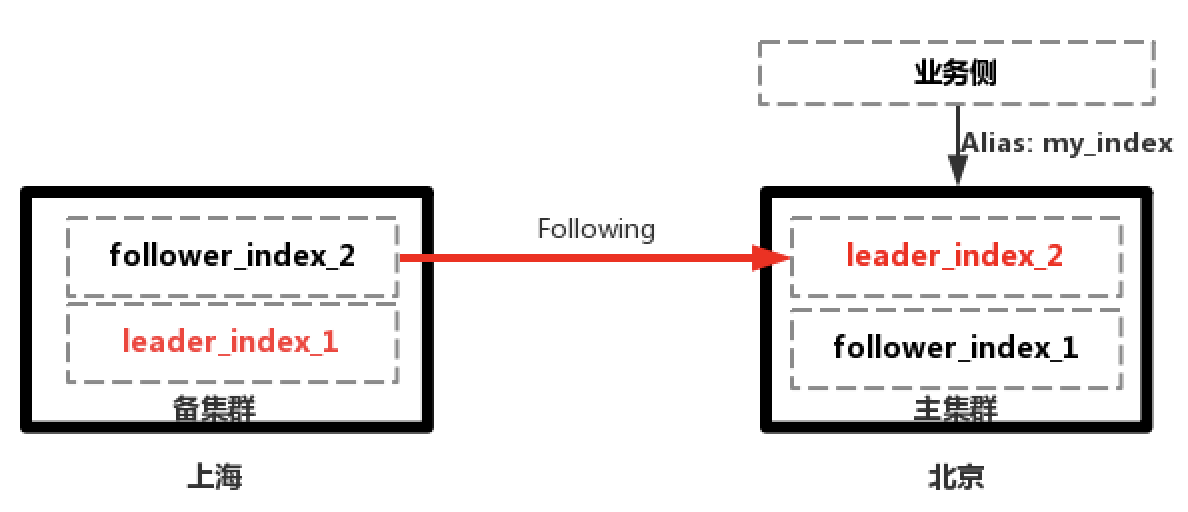
现在问题就是保证上海地域集群数据的完整性,在上海地域恢复后,可以在上海地域新建一个Follower Index,以北京地域正在进行写的索引为Leader同步数据,待数据完全追平后,再切换到上海地域进行读写,注意切换到需要新建Leader索引写入数据。
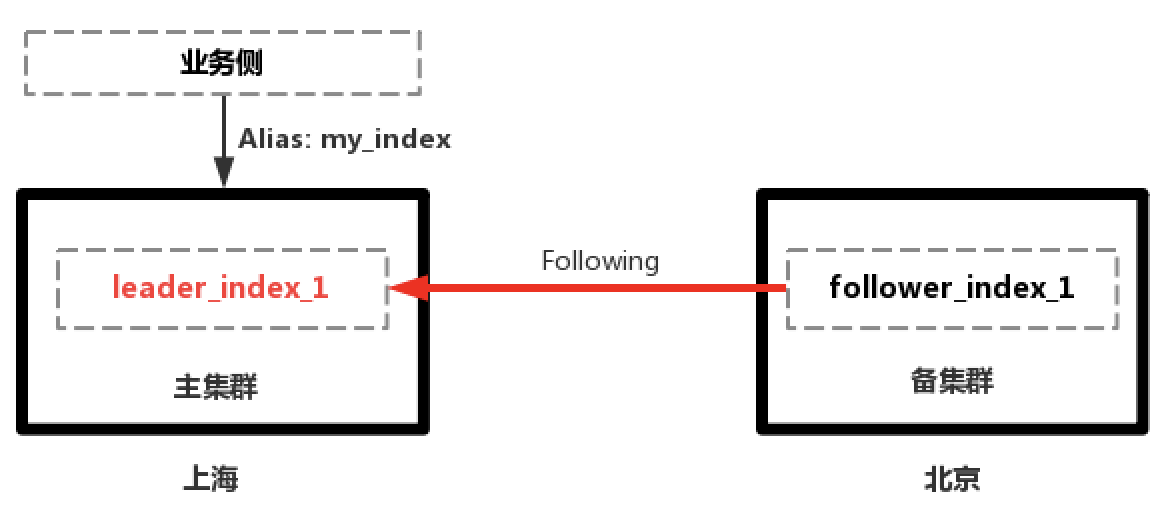
数据同步过程如下所示:
1.上海主集群正常提供服务,北京备集群从主集群Follow数据
2.上海主集群故障,业务切换到北京备集群进行读写,上海主集群恢复后从北京集群Follow数据
3.主备集群数据追平后,业务切换到上海集群进行读写