面试官:对象可能会迟到,但它永远不会缺席
- 2020 年 8 月 17 日
- 筆記
- Java Grammar, 面试
问题一:简单聊一下关于你对Object的理解
在 Java 中,只有基本数据类型不是对象,比如,数值,布尔和字符类型的值都不是对象。而其余的数据类型都是继承自一个名为Object的类,这个类是所有类的始祖,每个类都是由Object类扩展而来。
如果一个类继承自Object类,我们可以将extends Object给省略掉,如果在一个类的定义中没有明确的指出哪个是它的父类,那么Object类就认为是这个类的父类。
问题二:Object类中有一个registerNatives方法,对此你了解多少?
从方法的命名上我们就可以看出,该方法是用于注册本地(native)方法,主要是为了服务于JNI的,它主要是提供了 java 类中的方法与对应 C++ 代码中的方法的映射,方便jvm去查找调用 C++ 中的方法。
问题三:Object类中有clone方法,聊聊你对这个方法的认识
clone方法是Object类的一个protected的方法,我们可以这样去应用这个方法
-
实现
Cloneable接口 -
重写
clone方法,并指定public修饰符。
问题四:为什么我们一定要去实现Cloneable接口,而不是直接去重写这个方法呢?
我们通过源码可以发现这是一个空的接口,clone是从Object类继承的。这个接口只是作为一个标记,指示类设计者了解克隆继承。对象对于克隆也很”偏执”,如果一个对象请求克隆,但没有实现这个接口,就会生成一个异常。
在 Java 中,Cloneable这样的接口叫做标记接口,标记接口不包括任何方法,它的唯一作用就是允许在类型查询的时候使用instanceof:
- ounter(line
- ounter(line
- ounter(line
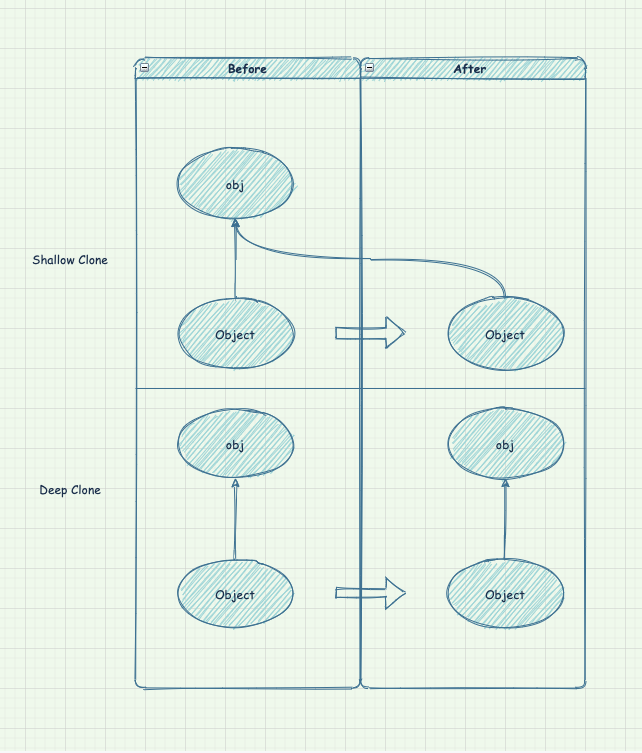
if (obj instanceof Cloneable){ //TODO}问题五:说一说你对关于深克隆和浅克隆的认识
首先来说一下Object类是如何实现clone,它对这个对象一无所知,所以只能逐个域的进行拷贝。如果对象中的所有数据域都是数值或其他基本类型,拷贝这些域没有任何问题,但是如果对象中包含子对象的引用,拷贝域就会得到相同子对象的另一个引用,这样一来,原对象和克隆对象仍然会去共享一些信息。这种Object类默认实现的clone方法称为浅拷贝(Shallow Clone)。
这里需要注意,关于浅克隆的安全性,如果原对象和浅克隆对象共享的子对象是不可变的,那么这种共享就是安全的。如果子对象属于一个不可变的类,如String,就是这种情况。或者在对象的生命期中,子对象一直包含不变的常量 ,没有更改器方法会改变它,也没有方法会生成它的引用,这种情况同样是安全的。
不过子类对象通常是可变的,这时我们就需要定义深拷贝(Deep Clone),来克隆这个类的所有子对象。
具体实现方法如下:
- ounter(line
- ounter(line
- ounter(line
- ounter(line
- ounter(line
- ounter(line
- ounter(line
public Test clone() throws CloneNotSupportedException{ //拷贝该对象 Test cloned = (Test)super.clone(); //拷贝该对象中的可变域 cloned.time = (Date) time.clone(); return cloned;}这里需要提到的一点是:
虽然我们已经学习了clone的两种用法,但是在实际的编码中还是尽量少用这个方法,它具有天生的不稳定性,仅仅了解即可。即使是Java的标准库中也只有5%的类实现了这个方法。
我们可以使用Java的对象串行化特性来实现克隆对象,虽然效率不高,但是很安全,而且很容易实现。
问题六: 关于equals方法,说说是什么?
Object类中的equals方法用于检测一个对象是否等于另一个对象。在Object类中,这个方法将判断两个对象是否具有相同的引用。如果两个对象具有相同的引用,它们一定是相等的。

问题七:有没有自己去重写过equals方法呢?
当然,这个我有笔记~

问题八:不限于Object,聊聊hashCode
在Java中,hash code是由对象导出的一个整型值,以下是几个常见哈希值的算法:
-
Object类的hashCode()。返回对象的内存地址经过处理后的结构,由于每个对象的内存地址都不一样,所以哈希码也不一样。 -
String类的hashCode()。根据String类包含的字符串的内容,根据一种特殊算法返回哈希码,只要字符串所在的堆空间相同,返回的哈希码也相同。 -
Integer类,返回的哈希码就是Integer对象里所包含的那个整数的数值,例如Integer i1=new Integer(100),i1.hashCode的值就是100 。由此可见,2个一样大小的Integer对象,返回的哈希码也一样。
问题九:说说Equals和 Hashcode的关系
这两个其实确切意义上并没有什么联系,前提是我们不会在HashSet,HashMap这种本质是散列表的数据结构中使用,如果我们要在HashSet,HashMap这种本质是散列表的数据结构中使用,在重写equals方法的同时也要重写hashCode方法,以便用户将对象插入到散列表中,否则会导致数据不唯一,内存泄漏等各种问题。
1.hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
2.equals()和hashCode()需要同时覆盖,而且定义必须一致,也就是说equals比较了哪些域,hashCode就会对哪些域进行hash值的处理。
3.若两个对象equals()返回true,则hashCode()有必要也返回相同的值。
4.若两个对象equals()返回false,则hashCode()不一定返回不同的值。
5.若两个对象hashCode()返回相同的值,则equals()不一定返回true。
6.若两个对象hashCode()返回不同值,则equals()一定返回false。
7.同一对象在执行期间若已经存储在集合中,则不能修改影响hashCode值的相关信息,否则会导致内存泄露问题。


