面试官:怎么做JDK8的垃圾收集器的调优?
面试官:怎么做JDK8的垃圾收集器的调优?

看着面试官真诚的眼神,心中暗想看起来年纪轻轻却提出如此直击灵魂的问题。擦了擦额头上汗,我稍微调整了一下紧张的情绪,对面试官说:
在JDK8中有Serial收集器、Parallel收集器、CMS收集器、G1收集器这么几种收集器,需要根据实际硬件配置和业务需求进行选择调优。
如此浅显的回答,无法让面试官达到深入的要求,肯定不能满足面试官强烈的需求,果不其然面试官又追问到:如果是桌面应用,内存占用也就100MB,应该选择哪种垃圾收集器呢?我快速的回答:Serial收集器。看着面试官期待的眼神,我又详细解释到:
文章持续更新,微信搜索「万猫学社第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
Serial收集器
Serial收集器是使用单线程处理所有的垃圾收集工作的,因为没有多线程的额外开销,相对来说也是比较有效的。所以,最适合单核CPU环境,因为本来也没办法利用多核。不过,当应用的使用的内存大小在100MB左右甚至更小的时候,在也适用于多核CPU的环境。
我一边说着,一边在纸上画了起来:
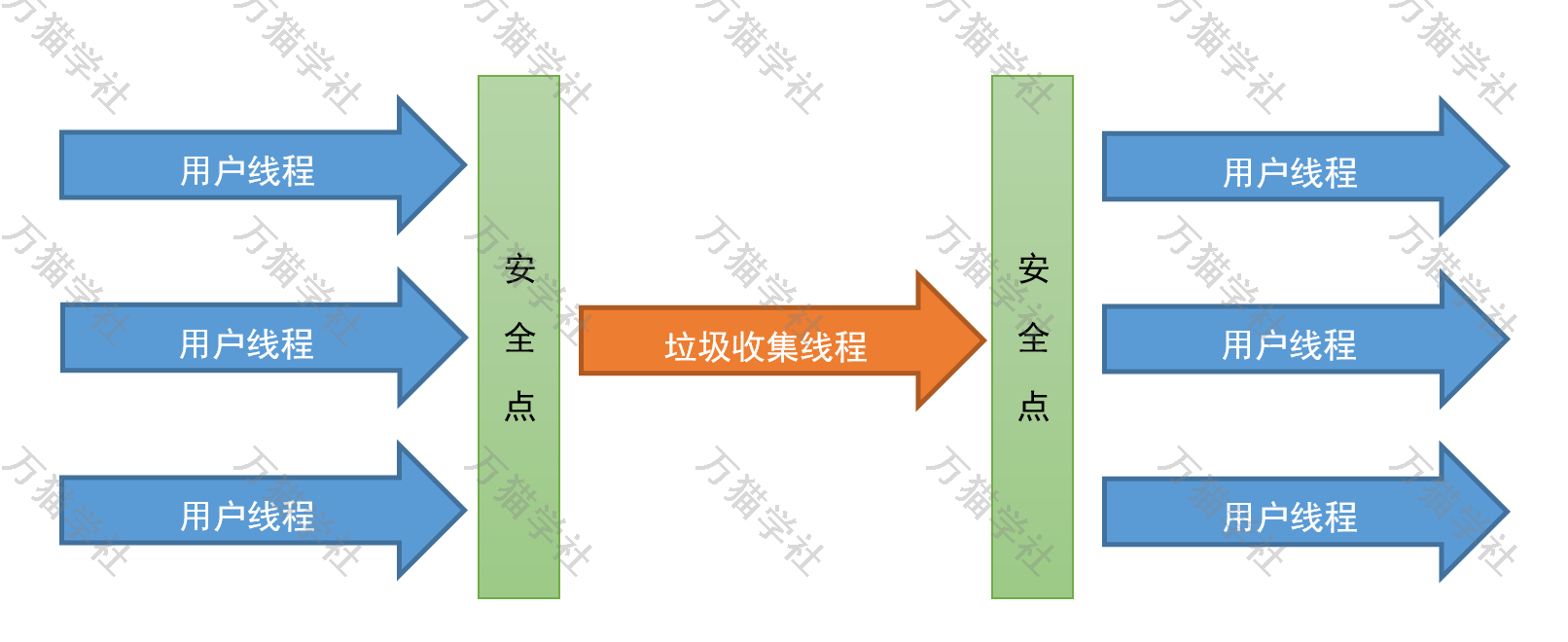
Client模式的JVM默认的垃圾收集器就是Serial收集器,或者可以使用JVM参数-XX:+UseSerialGC显式启用Serial收集器。
面试官又追问到:如果是要求高吞吐量的应用,使用较大内存并且有多核CPU,应该选择哪种垃圾收集器呢?我快速的回答:Parallel收集器。看着面试官期待的眼神,我又详细解释到:
文章持续更新,微信搜索「万猫学社第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
Parallel收集器
Parallel收集器是类似于Serial收集器的分代收集器,主要区别是在垃圾回收的时候使用了多个线程进行加速垃圾的收集。所以,对于使用较大内存并且有多核CPU的环境更加适合。
我一边说着,一边在纸上画了起来:
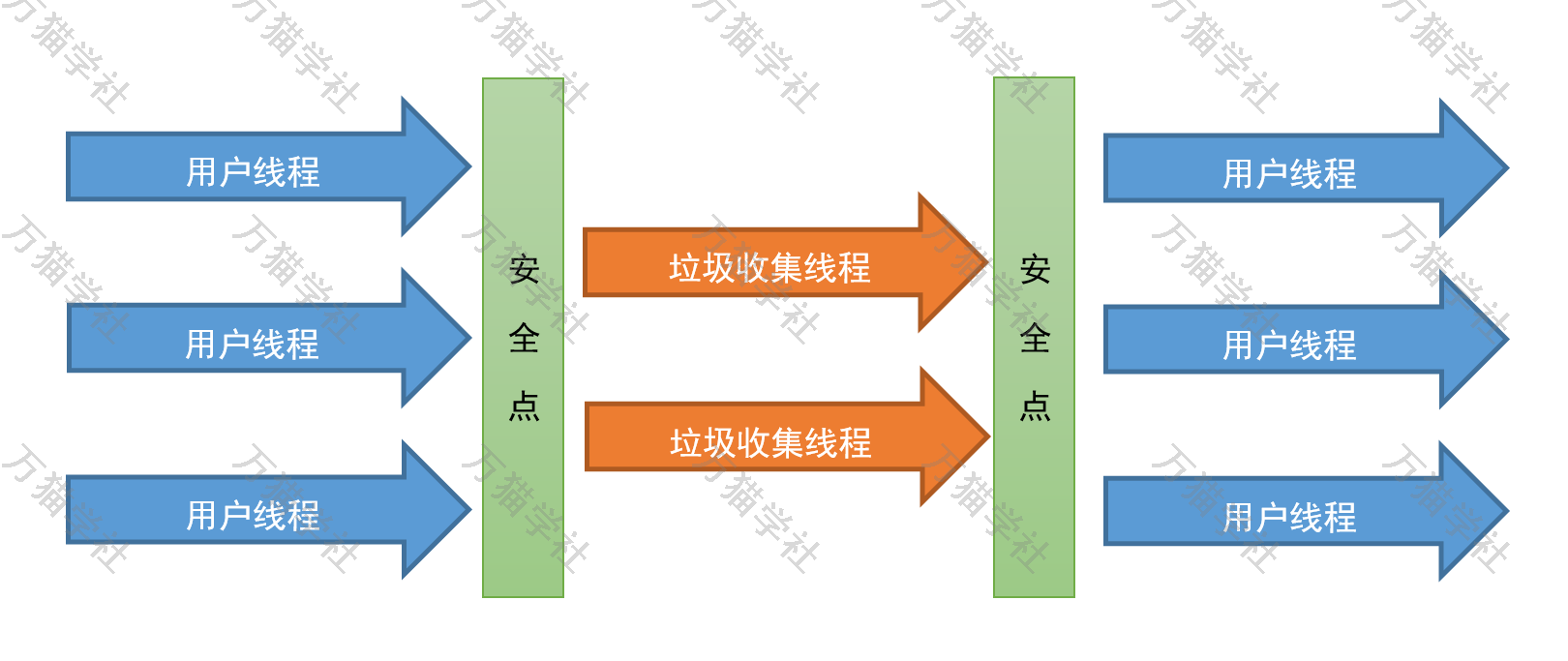
Server模式的JVM默认的垃圾收集器就是Parallel收集器,也可以使用JVM参数-XX:+UseParallelGC启用。启用Parallel收集器后默认情况下,Minor垃圾收集(针对年轻代的垃圾收集)和Major垃圾收集(针对老年代的垃圾收集)都是并行执行的,可以进一步减少垃圾收集的开销。
Parallel收集器可以通过JVM参数指定最大垃圾收集暂停时间、吞吐量(用户代码运行时间/(用户代码运行时间+垃圾收集运行时间))和堆占用空间的目标值:
- -XX:MaxGCPauseMillis:最大垃圾收集暂停时间,单位为毫秒,如:-XX:MaxGCPauseMillis=200,表示垃圾收集暂停时间最大为200毫秒。默认情况下,没有指定最大垃圾收集暂停时间。如果指定了暂停时间目标,则会调整堆大小与垃圾收集相关的其他参数,使垃圾收集的暂停时间短于指定值。这些调整可能导致降低应用的整体吞吐量,也有可能无法始终满足所指定的最大垃圾收集暂停时间目标。
- -XX:GCTimeRatio:吞吐量大小,如:-XX:GCTimeRatio=19,表示将垃圾收集运行时间的目标设定为应用总运行时间(用户代码运行时间+垃圾收集运行时间)的1/(1+19),即5%。默认值为99,垃圾收集的目标时间占应用总运行时间的1/(1+99),即1%。
- -Xmx:堆占用的最大占用空间,如:-Xmx1G,表示堆占用的最大占用空间为1GB。另外,Parallel收集器还有一个隐含的目标:只要满足其他目标的同时,把堆占用内存的大小最小化。
这三个目标是有优先级的:
- 高优先级:最大垃圾收集暂停时间
- 中优先级:吞吐量目标
- 低优先级:最小堆占用内存目标
Parallel收集器按照指定的目标对分代大小和底层进行自动调节,尽量达到指定的目标,但不保证百分之百能达到。
面试官又追问到:如果同样是使用较大内存并且有多核CPU,但是要求垃圾收集暂停时间要尽可能短的Web应用,应该选择哪种垃圾收集器呢?我稍微思考了一下,回答:CMS收集器。看着面试官期待的眼神,我又详细解释到:
文章持续更新,微信搜索「万猫学社第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
CMS收集器
CMS(Concurrent Mark Sweep)收集器是为那些要求垃圾收集暂停时间尽可能短,并且可以和垃圾收集器共享CPU资源的应用设计的。具有相对较大的内存使用并有多核CPU的应用,往往会更适合CMS收集器的使用。可以使用JVM参数-XX:+UseConcMarkSweepGC启用CMS收集器,启用后同时作用于Minor垃圾收集(针对年轻代的垃圾收集)和Major垃圾收集(针对老年代的垃圾收集)。
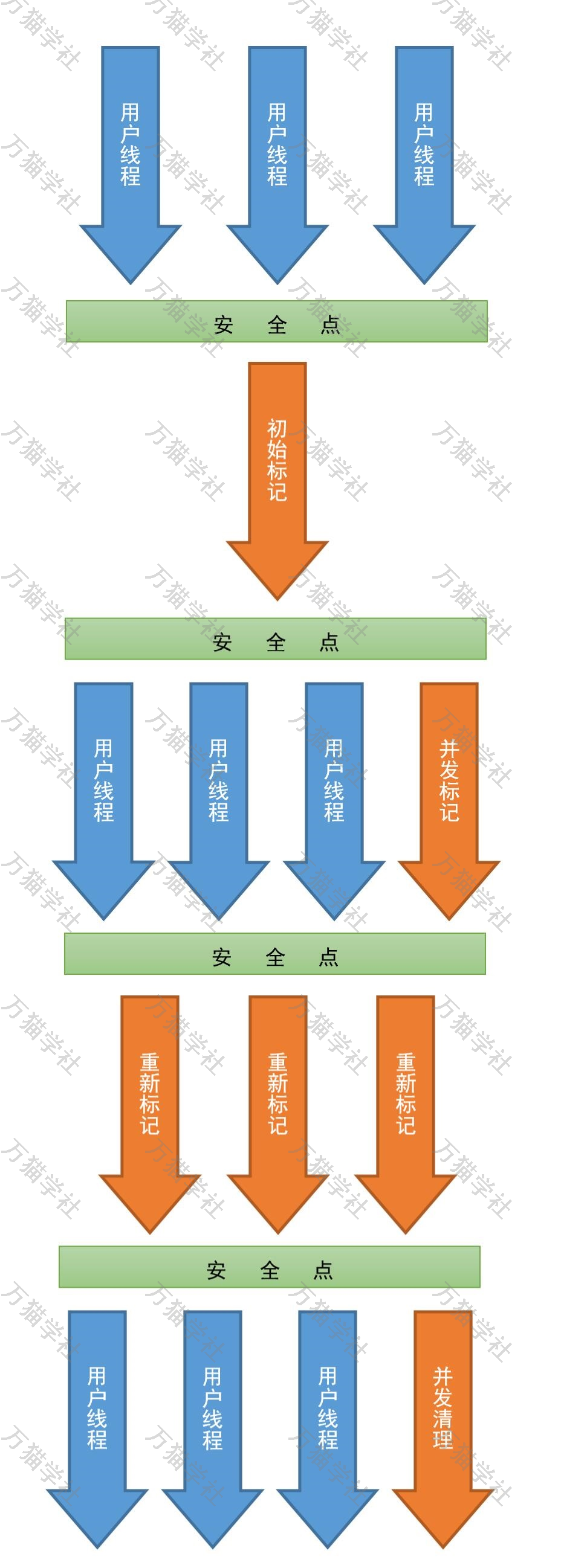
CMS收集器尝试通过使用单独的垃圾收集器线程在执行用户线程的同时并跟踪可访问对象,来减少由于Major垃圾收集而导致的暂停时间。在每个Major垃圾收集周期中,CMS收集器会在收集开始时暂停所有用户线程一小段时间,然后在收集的中期再次暂停。第二个暂停往往是两个暂停中较长的一个,在两个暂停之间都使用多个线程并行做收集工作的。所以,CMS收集器的垃圾收集过程分为以下四个步骤:
- 初始标记(CMS initial mark):这个步骤会暂停所有用户线程,但耗时非常短,标记GC Root直接关联的对象。
- 并发标记(CMS concurrent mark):这个步骤耗时较长,但用户线程可同时运行,标记至GC Root有可达路径的对象。
- 重新标记(CMS remark):这个步骤会暂停所有用户线程,但耗时比较短。由于步骤2用户线程同步运行,所以要修正在步骤二中用户线程同步运行产生对象标记的变动。
- 并发清除(CMS concurrent sweep):这个步骤耗时较长,但用户线程可同时运行。
我一边说着,一边在纸上画了起来:
面试官继续追问到:如果堆中有超过50%的活跃对象,分配对象和对象升代的频率较高,垃圾收集停顿时间大于0.5秒,应该选择哪种垃圾收集器呢?我稍微思考了一下,回答:G1收集器。看着面试官期待的眼神,我又详细解释到:
文章持续更新,微信搜索「万猫学社第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
G1收集器
G1(Garbage-First)收集器是一款主要面向服务端应用的垃圾收集器,适用于具有大内存的多核CPU的服务器。它尝试在高概率下同时满足较小的垃圾收集暂停时间和较高的吞吐量。所有堆相关的操作(如:全局标记)与用户线程同时运行,这样可以避免随着堆内存的大小的增加垃圾收集的停顿时间也跟着增加。
G1收集器是垃圾收集技术历史上里程碑的成果,它跳出了之前收集整个代垃圾的思维模式,开创了收集器面向局部收集的设计思路和基于Rigion的内存布局形式。在之后的JDK版本中,G1收集器正在逐渐成为了CMS收集器的替代者和继任者。
G1收集器虽然遵循分代收集的设计,但是整个堆的内存设计有显著的不同。整个堆被划分为一组大小相等的独立区域(Region),每个独立区域(Region)都有一个连续的虚拟内存范围,并且根据需要在逻辑被划分为年轻代的Eden区、Survivor区或者老年代。
我一边说着,一边在纸上画了起来:

通过JVM参数-XX:MaxGCPauseMillis来给G1收集器指定垃圾收集的目标停顿时间,默认是200毫秒。G1收集器会使用预测模型来估算停顿时间内可以收集多少个独立区域。在一次垃圾回收结束时,G1收集器会选择下次将要收集哪些独立区域。通常情况下,G1收集器通过选择年轻代独立区域的数量来控制垃圾收集的停顿时间。与其他垃圾收集器一样,可以通过参数指定年轻代的大小,但是这样做可能会影响G1收集器达到停顿时间目标的效果。除了停顿时间目标之外,还可以通过JVM参数-XX:GCPauseIntervalMillis指定停顿的间隔时长,默认是0。
听了我的回答后,面试官对我会心一笑,我仿佛还在她的眼神中看到了一丝倾慕。正所谓:金风玉露一相逢,便胜却人间无数,欲知后事如何,且听下回分解。
文章持续更新,微信搜索「万猫学社」第一时间阅读。
关注后回复「电子书」,免费获取12本Java必读技术书籍。
微信公众号:万猫学社
微信扫描二维码
关注后回复「电子书」
获取12本Java必读技术书籍



