用go语言爬取珍爱网 | 第三回
- 2019 年 10 月 18 日
- 筆記
前两节我们获取到了城市的URL和城市名,今天我们来解析用户信息。

爬虫的算法:
我们要提取返回体中的城市列表,需要用到城市列表解析器;
需要把每个城市里的所有用户解析出来,需要用到城市解析器;
还需要把每个用户的个人信息解析出来,需要用到用户解析器。
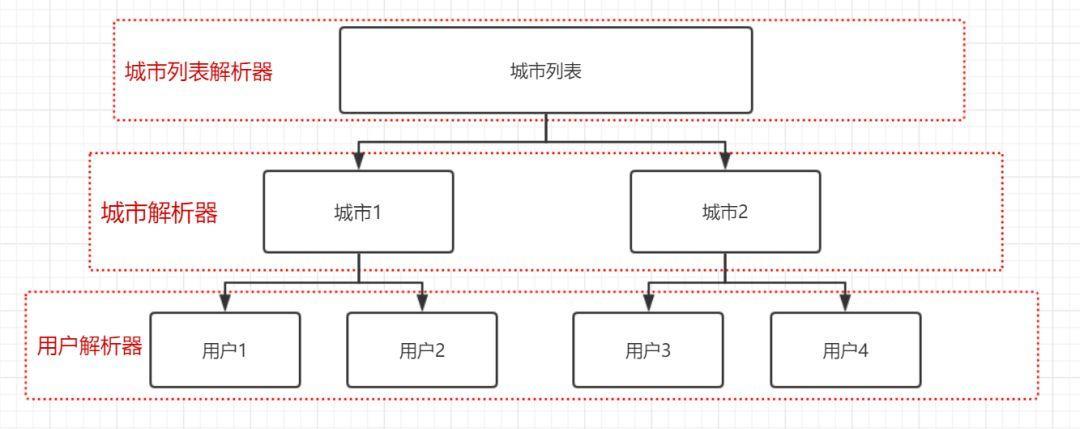
爬虫整体架构:
Seed把需要爬的request送到engine,engine负责将request里的url送到fetcher去爬取数据,返回utf-8的信息,然后engine将返回信息送到解析器Parser里解析有用信息,返回更多待请求requests和有用信息items,任务队列用于存储待请求的request,engine驱动各模块处理数据,直到任务队列为空。
代码实现:
按照上面的思路,设计出城市列表解析器citylist.go代码如下:
package parser import ( "crawler/engine" "regexp" "log" ) const ( //<a href="http://album.zhenai.com/u/1361133512" target="_blank">怎么会迷上你</a> cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>` ) func ParseCity(contents []byte) engine.ParserResult { compile := regexp.MustCompile(cityReg) submatch := compile.FindAllSubmatch(contents, -1) //这里要把解析到的每个URL都生成一个新的request result := engine.ParserResult{} for _, m := range submatch { name := string(m[2]) log.Printf("UserName:%s URL:%sn", string(m[2]), string(m[1])) //把用户信息人名加到item里 result.Items = append(result.Items, name) result.Requests = append(result.Requests, engine.Request{ //用户信息对应的URL,用于之后的用户信息爬取 Url : string(m[1]), //这个parser是对城市下面的用户的parse ParserFunc : func(bytes []byte) engine.ParserResult { //这里使用闭包的方式;这里不能用m[2],否则所有for循环里的用户都会共用一个名字 //需要拷贝m[2] ---- name := string(m[2]) return ParseProfile(bytes, name) }, }) } return result }城市解析器city.go如下:
package parser import ( "crawler/engine" "regexp" "log" ) const ( //<a href="http://album.zhenai.com/u/1361133512" target="_blank">怎么会迷上你</a> cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>` ) func ParseCity(contents []byte) engine.ParserResult { compile := regexp.MustCompile(cityReg) submatch := compile.FindAllSubmatch(contents, -1) //这里要把解析到的每个URL都生成一个新的request result := engine.ParserResult{} for _, m := range submatch { name := string(m[2]) log.Printf("UserName:%s URL:%sn", string(m[2]), string(m[1])) //把用户信息人名加到item里 result.Items = append(result.Items, name) result.Requests = append(result.Requests, engine.Request{ //用户信息对应的URL,用于之后的用户信息爬取 Url : string(m[1]), //这个parser是对城市下面的用户的parse ParserFunc : func(bytes []byte) engine.ParserResult { //这里使用闭包的方式;这里不能用m[2],否则所有for循环里的用户都会共用一个名字 //需要拷贝m[2] ---- name := string(m[2]) return ParseProfile(bytes, name) }, }) } return result }用户解析器profile.go如下:
package parser import ( "crawler/engine" "crawler/model" "regexp" "strconv" ) var ( // <td><span class="label">年龄:</span>25岁</td> ageReg = regexp.MustCompile(`<td><span class="label">年龄:</span>([d]+)岁</td>`) // <td><span class="label">身高:</span>182CM</td> heightReg = regexp.MustCompile(`<td><span class="label">身高:</span>(.+)CM</td>`) // <td><span class="label">月收入:</span>5001-8000元</td> incomeReg = regexp.MustCompile(`<td><span class="label">月收入:</span>([0-9-]+)元</td>`) //<td><span class="label">婚况:</span>未婚</td> marriageReg = regexp.MustCompile(`<td><span class="label">婚况:</span>(.+)</td>`) //<td><span class="label">学历:</span>大学本科</td> educationReg = regexp.MustCompile(`<td><span class="label">学历:</span>(.+)</td>`) //<td><span class="label">工作地:</span>安徽蚌埠</td> workLocationReg = regexp.MustCompile(`<td><span class="label">工作地:</span>(.+)</td>`) // <td><span class="label">职业: </span>--</td> occupationReg = regexp.MustCompile(`<td><span class="label">职业: </span><span field="">(.+)</span></td>`) // <td><span class="label">星座:</span>射手座</td> xinzuoReg = regexp.MustCompile(`<td><span class="label">星座:</span><span field="">(.+)</span></td>`) //<td><span class="label">籍贯:</span>安徽蚌埠</td> hokouReg = regexp.MustCompile(`<td><span class="label">民族:</span><span field="">(.+)</span></td>`) // <td><span class="label">住房条件:</span><span field="">--</span></td> houseReg = regexp.MustCompile(`<td><span class="label">住房条件:</span><span field="">(.+)</span></td>`) // <td width="150"><span class="grayL">性别:</span>男</td> genderReg = regexp.MustCompile(`<td width="150"><span class="grayL">性别:</span>(.+)</td>`) // <td><span class="label">体重:</span><span field="">67KG</span></td> weightReg = regexp.MustCompile(`<td><span class="label">体重:</span><span field="">(.+)KG</span></td>`) //<h1 class="ceiling-name ib fl fs24 lh32 blue">怎么会迷上你</h1> //nameReg = regexp.MustCompile(`<h1 class="ceiling-name ib fl fs24 lh32 blue">([^d]+)</h1> `) //<td><span class="label">是否购车:</span><span field="">未购车</span></td> carReg = regexp.MustCompile(`<td><span class="label">是否购车:</span><span field="">(.+)</span></td>`) ) func ParseProfile(contents []byte, name string) engine.ParserResult { profile := model.Profile{} age, err := strconv.Atoi(extractString(contents, ageReg)) if err != nil { profile.Age = 0 }else { profile.Age = age } height, err := strconv.Atoi(extractString(contents, heightReg)) if err != nil { profile.Height = 0 }else { profile.Height = height } weight, err := strconv.Atoi(extractString(contents, weightReg)) if err != nil { profile.Weight = 0 }else { profile.Weight = weight } profile.Income = extractString(contents, incomeReg) profile.Car = extractString(contents, carReg) profile.Education = extractString(contents, educationReg) profile.Gender = extractString(contents, genderReg) profile.Hokou = extractString(contents, hokouReg) profile.Income = extractString(contents, incomeReg) profile.Marriage = extractString(contents, marriageReg) profile.Name = name profile.Occupation = extractString(contents, occupationReg) profile.WorkLocation = extractString(contents, workLocationReg) profile.Xinzuo = extractString(contents, xinzuoReg) result := engine.ParserResult{ Items: []interface{}{profile}, } return result } //get value by reg from contents func extractString(contents []byte, re *regexp.Regexp) string { m := re.FindSubmatch(contents) if len(m) > 0 { return string(m[1]) } else { return "" } }engine代码如下:
package engine import ( "crawler/fetcher" "log" ) func Run(seeds ...Request){ //这里维持一个队列 var requestsQueue []Request requestsQueue = append(requestsQueue, seeds...) for len(requestsQueue) > 0 { //取第一个 r := requestsQueue[0] //只保留没处理的request requestsQueue = requestsQueue[1:] log.Printf("fetching url:%sn", r.Url) //爬取数据 body, err := fetcher.Fetch(r.Url) if err != nil { log.Printf("fetch url: %s; err: %vn", r.Url, err) //发生错误继续爬取下一个url continue } //解析爬取到的结果 result := r.ParserFunc(body) //把爬取结果里的request继续加到request队列 requestsQueue = append(requestsQueue, result.Requests...) //打印每个结果里的item,即打印城市名、城市下的人名... for _, item := range result.Items { log.Printf("get item is %vn", item) } } }Fetcher用于发起http get请求,这里有一点注意的是:珍爱网可能做了反爬虫限制手段,所以直接用http.Get(url)方式发请求,会报403拒绝访问;故需要模拟浏览器方式:
client := &http.Client{} req, err := http.NewRequest("GET", url, nil) if err != nil { log.Fatalln("NewRequest is err ", err) return nil, fmt.Errorf("NewRequest is err %vn", err) } req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36") //返送请求获取返回结果 resp, err := client.Do(req)最终fetcher代码如下:
package fetcher import ( "bufio" "fmt" "golang.org/x/net/html/charset" "golang.org/x/text/encoding" "golang.org/x/text/encoding/unicode" "golang.org/x/text/transform" "io/ioutil" "log" "net/http" ) /** 爬取网络资源函数 */ func Fetch(url string) ([]byte, error) { client := &http.Client{} req, err := http.NewRequest("GET", url, nil) if err != nil { log.Fatalln("NewRequest is err ", err) return nil, fmt.Errorf("NewRequest is err %vn", err) } req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36") //返送请求获取返回结果 resp, err := client.Do(req) //直接用http.Get(url)进行获取信息,爬取时可能返回403,禁止访问 //resp, err := http.Get(url) if err != nil { return nil, fmt.Errorf("Error: http Get, err is %vn", err) } //关闭response body defer resp.Body.Close() if resp.StatusCode != http.StatusOK { return nil, fmt.Errorf("Error: StatusCode is %dn", resp.StatusCode) } //utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder()) bodyReader := bufio.NewReader(resp.Body) utf8Reader := transform.NewReader(bodyReader, determineEncoding(bodyReader).NewDecoder()) return ioutil.ReadAll(utf8Reader) } /** 确认编码格式 */ func determineEncoding(r *bufio.Reader) encoding.Encoding { //这里的r读取完得保证resp.Body还可读 body, err := r.Peek(1024) //如果解析编码类型时遇到错误,返回UTF-8 if err != nil { log.Printf("determineEncoding error is %v", err) return unicode.UTF8 } //这里简化,不取是否确认 e, _, _ := charset.DetermineEncoding(body, "") return e }main方法如下:
package main import ( "crawler/engine" "crawler/zhenai/parser" ) func main() { request := engine.Request{ Url: "http://www.zhenai.com/zhenghun", ParserFunc: parser.ParseCityList, } engine.Run(request) }最终爬取到的用户信息如下,包括昵称、年龄、身高、体重、工资、婚姻状况等。
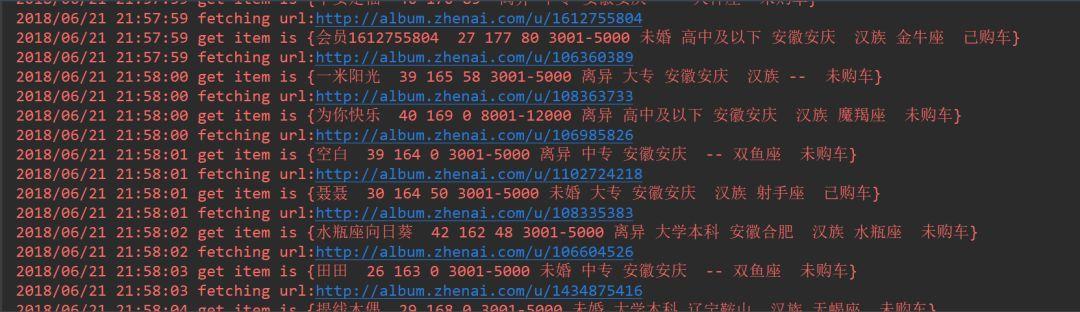
如果你想要哪个妹子的照片,可以点开url查看,然后打招呼进一步发展。
至此单任务版的爬虫就做完了,后面我们将对单任务版爬虫做性能分析,然后升级为多任务并发版,把爬取到的信息存到ElasticSearch中,在页面上查询
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你

本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你