深度学习论文翻译解析(十):Visualizing and Understanding Convolutional Networks
- 2020 年 7 月 13 日
- 筆記
- 深度学习论文翻译解析
论文标题:Visualizing and Understanding Convolutional Networks
标题翻译:可视化和理解卷积网络
论文作者:Matthew D. Zeiler Rob Fergus
论文地址://arxiv.org/pdf/1311.2901v3.pdf
//arxiv.org/abs/1311.2901
参考的翻译博客://blog.csdn.net/kklots/article/details/17136059
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
前言
在所有深度网络中,卷积神经网络和图像处理最为密切相关,卷积网在很多图片分类竞赛中都取得了很好的效果,但卷积网调参过程很不直观,很多时候都是碰运气,我们却不知道原因。为此,卷积网发明者 Yann LeCun 的得意门生 Matthew Zeiler 在 2013年专门写了一篇论文,阐述了如何用反卷积网络可视化整个卷积网络,并进行分析和调优,该论文是在AlexNet基础上进行了一些细节的改进,网络结构上并没有太大的突破,但是最大的贡献是通过使用可视化技术揭示了神经网络各层到底是在干什么,起到了什么作用。
从科学的观点触发,如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。这篇文献的目的,就是要通过特征可视化,查看精度变化,从而知道CNN学习到的特征如何。它使用一个多层的反卷积网络来可视化训练过程中特征的演化以及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
所以简单总结本文内容:当输入一张图片到卷积网中时,网络会逐级产生特征,但究竟是图片中的那一部分刺激网络产生了特定特征,没法直接得到;作者想到了一种办法:将产生的特征通过反卷积技术,重构出对应的输入刺激,而重构的刺激只会显示真正有用东西,作者就可以通过分析这些信息来分析模型,实现模型调优。

摘要
近些年,大型卷积神经网络模型在 ImageNet数据集上表现出令人印象深刻的效果(如 2012年的Krizhevsky),但是由很多人还没有搞懂为什么这些卷积模型会取得如此好的效果,以及如何提高分类效果。在这篇文章中,我们对这两个问题均进行了讨论。我们介绍了一种创新性的可视化技术可以深入观察中间的特征层函数的作用以及分类器的行为。作为一项类似诊断性的技术,可视化操作可以使我们找到比 Krizhevsky(AlexNet模型)更好的模型架构。在ImageNet分类数据集上,我们还进行了一项抽丝剥茧的工作,以发现不同的层对结果的影响。我们看到,当 Softmax分类器重新训练后,我们的模型在 ImageNet数据集上可以很好地泛化到其他数据集,瞬间就击败了现如今 Caltech-101以及 Caltech-256 上的最好的方法。


1,引言
自从 1989年 LeCun 等人研究推广卷积神经网络(以下称为 CNN)之后,在 1990年代,CNN在一些图像应用领域展现出极好的效果,例如手写字体分类,人脸识别等等。在去年,许多论文都表示他们可以在一些有难度的数据集上取得较好的分类效果,Ciresan等人于 2012年在 NORB 和 CIFAR-10 数据集上取得了最好的效果。更具有代表性的是 Krizhevsky 等人 2012 的论文,在ImageNet 2012 数据集分类挑战中取得了绝对的优势,他们的错误率仅有 16.4%,与此相对的第二名则是 26.1%。造成这种有趣的现象的因素有很多:(i)大量的训练数据和已标注数据;(ii)强大的 GPU训练;(iii)更好的正则化方法如 Dropout(Hinton et al,2012)
尽管如此,我们还是很少能够深入理解神经网络中的机制,以及为何他们能取得如此效果。从科学的角度来说,这是远远不够的。如果没有清楚地了解其中的本质,那么更好的模型的开发就只能变成整天像无头苍蝇一样乱试。在本文中,我们利用反卷积网重构每层的输入信息,再将重构信息投影到像素空间中,从而实现了可视化。通过可视化技术来分析“输入的色彩如何映射不同层上的特征”,“特征如何随着训练过程发生变化”等问题,甚至利用可视化技术来诊断和改进当前网络结果可能存在的问题。我们还进行了一项很有意义的研究,那就是遮挡输入图像的一部分,来说明那一部分是对分类最有影响的。

使用这些方法,我们从 Krizhevsky 模型的体系结构开始,逐步探索了其他不同模型的体系结构,发现他们的性能优于 ImageNet 上的结果。我们还探索了不同数据集上模型的泛化能力,仅依靠在上面重新训练 Softmax层。因此,我们这儿讨论的是一种有监督的预训练形式,与 Hinton 和 Bengio,Vincent等人推广的无监督的训练方法不同。另外 Convnet 特征的泛化能力的讨论在 Donahue 的 2013的论文中也有探讨过。

1.1 相关工作
通过对神经网络可视化方法来获得一些科研灵感是很常有的做法,但大多数都局限于第一层,因为第一层比较容易映射到像素空间。在较高的网络层就难以处理了,只有有限的解释节点活跃性的方法。Erhan等人 2009 的方法,通过在图像空间中执行梯度下降以最大化单元的激活来找到每个单元的最大响应刺激方式。这需要很细心的操作,而且也没有给出任何关于单位某种恒定属性的信息。受此启发有一种改良的方法,(Leet al ,2010)在(Berkes & Wiskott 2006)的基础上做一些延伸,通过计算一个节点的 Hessian矩阵来观测节点的一些稳定的属性,问题在于对于更高层次而言,不变性非常复杂,因此通过简单的二次近似法(quadratic approximation)很难描述。相反,我们的方法提供了非参数化的不变性视图,显示了训练集中的哪些模式激活了特征映射。(Donahue等,2013)显示了可视化,看可视化结果能表明模型中高层的节点究竟是被哪一块区域给激活。我们的可视化效果不同,因为它不仅仅是输入图像的作物,而是自上而下的投影,它揭示了每个补丁内的结构,这些结构会刺激特定的特征图谱。


2,实现方法
本文采用了由(LeCun etal. 1989)以及(Krizhevsky etal 2012)提出的标准的有监督学习的卷积网模型,该模型通过一系列隐含层,将输入的二维彩色图像映射成长度为C的一维概率向量,向量的每个概率分别对应 C 个不同分类,每层包含以下部分:1,卷积层,每个卷积图都由前面一层网络的输出结果(对于第一层来说,上层输出结果就是输入图片),与学习获得的特定核进行卷积运算产生;2,矫正层,对每个卷积结果都进行矫正运算 relu(x) = Max(0, 1);3 [可选] max pooling 层,对矫正运算结果进行一定领域内的 max pooling 操作,获得降采样图;4 [可选] 对降采样图进行对比度归一化操作,使得输出特征平稳。更多操作细节,请参考(Krizhevsky et al 2012)以及(Jarrett et al 2009)。最后几乎是全连接网络,输出层是一个 Softmax 分类器,图3上部展示了这个模型。
我们使用 N 张标签图片(x, y)构成的数据集来训练模型,其中标签 yi 是一个离散变量,用来表示图片的类别。用交叉熵误差函数来评估输出标签 yihat 和真实标签 yi 的差异。整个网络参数(包括卷积层的卷积核,全连接层的权值矩阵和偏置值)通过反向传播算法进行训练,选择随机梯度下降法更新权值,具体细节参见章节3。

2.1 通过反卷积网络(Deconvnet)实现可视化
要想深入了解卷积网络,就需要了解中间层特征的作用。本文将中间层特征反向映射到像素空间,观察出什么输入会导致特点的输出,可视化过程基于(Zeiler et al 2011)提出的反卷积网络实现。一层反卷积网可以看成是一层卷积网络的逆操作,他们拥有相同的卷积核和 pooling函数(准确来讲,应该是逆函数),因此反卷积网是将输出特征逆映射成输入信号。在(Zeiler et al 2011)中,反卷积网络被用作无监督学习,本文则用来可视化演示。
为了检查一个网络,在本文的模型中,卷积网络的每一层都附加了一个反卷积层,参见图1,提供了一条由输出特征到输入图像的反通路。首先,输入图像通过卷积网模型,每层都会产生特定特征,而后,我们将反卷积网中观测层的其他连接权值全部置零,将卷积网观测层产生的特征当做输入,送给对应的反卷积层,依次进行以下操作:1 unpool,2 rectify(矫正),3 反卷积(过滤以重新构建所选激活下的图层中的活动,然后重复此操作直至达到输入像素空间)


Unpooling:严格来讲,max pooling 操作是不可逆的,本文用了一种近似方法来计算 max pooling 的逆操作:在 max pooling 过程中,用 Max locations “Switches”表格记录下每个最大值的位置,在 unpooling 过程中,我们将最大值标注回记录所在位置,其余位置填 0,图1底部显示了这一过程。
简单说就是,在训练过程中记录每一个池化操作的 z*z 的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补0。
Rectification:在卷积网络中,为了保证特征有效性,我们通过 relu 非线性函数来保证所有输出都为非负数,这个约束对反卷积过程依然成立,因此将重构信号送入 relu 函数中。
Filtering:卷积网使用学习得到的卷积核与上层输出做卷积,得到特征。为了实现逆过程,反卷积网络使用相同卷积核的转置作为核,与矫正后的特征进行卷积运算。
使用原卷积核的转秩和 feature map 进行卷积。反卷积其实是一个误导,这里真正的名字就是 转秩卷积操作。
在 unpooling过程中,由于“Switches”只记录了极大值的位置信息,其余位置均用 0 填充,因此重构出的图片看起来会不连续,很像原始图片中的某个碎片,这些碎片就是训练出高性能卷积网的关键。由于这些重构图像不是从模型中采样生成,因此中间不存在生成式过程。
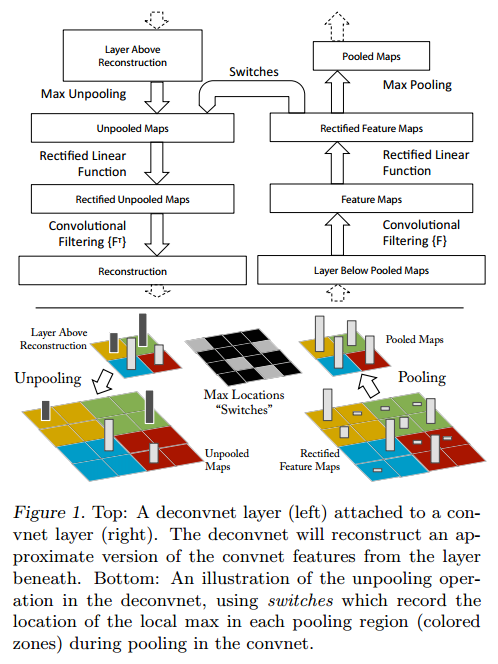
图1:Top:一层反卷积网络(左)附加在一层卷积网(右)上。反卷积网络层会近似重构出下卷积网络层产生的特征。 Bottom:反卷积网络 unpooling 过程的演示,使用 Switches表格记录极大值点的位置,从而近似还原出 pooling 操作前的特征。

3,训练细节
图3中的网络模型与(Krizhevsky et al 2012)使用的卷积模型很相似,不同点在于:1,Krizhevsky在3, 4, 5层使用的是稀疏连接(由于该模型被分配到了两个 GPU上),而本文用了稠密连接。2,另一个重要的不同将在章节4.1 和 图6中详细阐述。
本文选择了 ImageNet 2012 作为训练集(130万张图片,超过 1000 个不同类别),首先截取每张 RGB图片最中心的 256*256区域,然后减去整张图片颜色均值,再截出 10 个不同的 224*224 窗口(可对原图进行水平翻转,窗口可在区域中滑动)。采用随机梯度下降法学习,batchsize选择128, 学习率选择 0.01,动量系数选择 0.9;当误差趋于收敛时,手动停止训练过程:Dropout 策略(Hinton et al 2012)运用在全连接层中,系数设为 0.5,所有权值初始化值设为 0.01, 偏置值设为0。
图6(a)展示了部分训练得到的第1层卷积核,其中有一部分核数值过大,为了避免这种情况,我们采取了如下策略:均方根超过 0.1 的核将重新进行归一化,使其均方根为 0.1.该步骤非常关键,因为第1层的输入变化范围在 [-128, 128]之间。前面提到了,我们通过滑动窗口截取和对原始图像的水平翻转来提高训练集的大小,这一点和(Krizhevsky et al 2012)相同。整个训练过程基于(Krizhevsky et al 2012)的代码实现,在单块 GTX580 GPU 上进行,总共进行了 70次全库迭代,运行了 12天。


4,卷积网络可视化
通过章节3描述的结构框架,我们开始使用反卷积网来可视化ImageNet验证集上的特征激活。
特征可视化:图2展示了训练结束后,模型各个隐含层提取的特征,图2显示了在给定输出特征的情况下,反卷积层产生的最强的9个输入特征。将这些计算所得的特征,用像素空间表示后,可以清洗的看出:一组特定的输入特征(通过重构获得),将刺激卷积网络产生一个固定的输出特征。这一点解释了为什么当输入存在一定畸变时,网络的输出结果保持不变。在可视化结果的右边是对应的输入图片,和重构特征相比,输入图片之间的差异性很大,而重构特征只包含哪些具有判别能力纹理结构。举例说明:层5第1行第2列的9张输入图片各不相同,差异很大,而对应的重构输入特征则都显示了背景的草地,没有显示五花八门的前景。
每层的可视化结果都展示了网络的层次化特点。层2展示了物体的边缘和轮廓,以及与颜色的组合;层3拥有了更复杂的不变性,主要展示了相似的纹理(例如:第1行第1列的网格模型;第2行第4列的花纹);层4不同组重构特征存在着重大差异性,开始体现类与类之间的差异:狗狗的脸(第一行第一列),鸟的腿(第4行第2列);层5每组图片都展示了存在重大差异的一类物体,例如:键盘(第1行第1列),狗(第4行)
特征在训练过程中的演化:图4展示了在训练过程中,由特定输出特征反向卷积,所获得的最强重构输入特征(从所有训练样本中选出)是如何演化的,当输入图片中的最强刺激源发生变换时,对应的输出特征轮廓发生跳变。经过一定次数的迭代后,底层特征趋于稳定。但更高层的特征则需要更多的迭代才能收敛(约 40~50个周期),这表明:只有所有层都收敛时,分类模型才堪用。
特征不变性:图5展示了5个不同的例子,他们分别被平移,旋转和缩放。图5右边显示了不同层特征向量所具有的不变性能力。在第1层,很小的微变都会导致输出特征变换明显,但越往高层走,平移和尺度变换对最终结果的影响越小。总体来说:卷积网络无法对旋转操作产生不变性,除非物体具有很强的对称性。



图2 :训练好的卷积网络,显示了层2到层5通过反卷积层的计算,得到9个最强输入特征,并将输入特征映射到了像素空间。本文的重构输入特征不是采样生成的:他们是固定的,由特定的输出特征反卷积计算产生。每一个重构输入特征都对应的显示了它的输入图像。三点启示:1 每组重构特征(9个)都有强相关性;2 层次越高,不变性越强;3都是原始输入图片具有强辨识度部分的夸张展现。例如:狗的眼睛,鼻子(层4, 第一行第1列)

4.1 结构选择
观察 Krizhevsky 的网络模型可以帮助我们在一开始就选择一个好的模型。反卷积网络可视化技术显示了 Krizhevsky 卷积网络的一些问题。如图 6(a)以及 6(d)所示,第1层卷积核混杂了大量的高频和低频信息,缺少中频信息;第二层由于卷积过程选择4作为步长,产生了混乱无用的特征。为了解决这些问题,我们做了如下的工作:(i)将第一层的卷积核大小由11*11 调整到 7*7;(ii)将卷积步长由 4调整为2;新的模型不但保留了1, 2层绝大部分的有用特征,如图 6(c),6(e)所示,还提高了最终分类性能,我们将在章节5.1看到具体结果。

4.2 遮挡灵敏性
当模型达到期望的分类性能时,一个自然而然的想法是:分类器究竟使用了什么信息实现分类?是图像中具体位置的像素值,还是图像中的上下文。我们试图回答这个问题,图7中使用了一个灰色矩阵对输入图像的每个部分进行遮挡,并测试在不同遮挡情况下,分类器的输出结果,可以清楚地看到:当关键区域发生遮挡时,分类器性能急剧下降。图7还展示了最上层卷积网的最强响应特征,展示了遮挡位置和响应强度之间的关系:当遮挡发生在关键物体出现的位置时,响应强度急剧下降。该图真实的反映了输入什么样的刺激,会促使系统产生某个特定的输出特征,用这种方法可以一一查找出图2和图4中特定特征的最佳刺激是什么。

4.3 图片相关性分析
与其他许多已知的识别模型不同,深度神经网络没有一套有效理论来分析特定物体部件之间的关系(例如:如何解释人脸眼睛和鼻子在空间位置上的关系),但深度网络很可能非显式的计算了这些特征。为了验证这些假设,本文随机选择了5张狗狗的正面图片,并系统性地挡住狗狗所有照片的一部分(例如:所有的左眼,参见图8)。对于每张图I,计算:
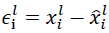
其中 xil 和 xilhat 分别表示原始图片和被遮挡图片所产生的的特征,然后策略所有图片对(i, j)的误差向量 epsilon 的一致性:
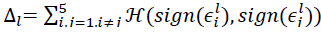
其中,H 是 Hamming distance, Δl 值越小,对应操作对狗狗分类的影响越一致,就表明这些不同图片上被遮挡的部件越存在紧密联系。表1 中我们对比了遮挡 左眼,右眼,鼻子的 Δ 比随机遮挡的 Δ 更低,说明眼睛图片和鼻子图片内部存在相关性。第5层鼻子和眼睛的得分差异明显,说明第5层卷积网对部件级(鼻子,眼睛等等)的相关性更为关注;第7层各个部分得分差异不大,说明第7层卷积网络开始关注更高层的信息(狗狗的品种等等)。
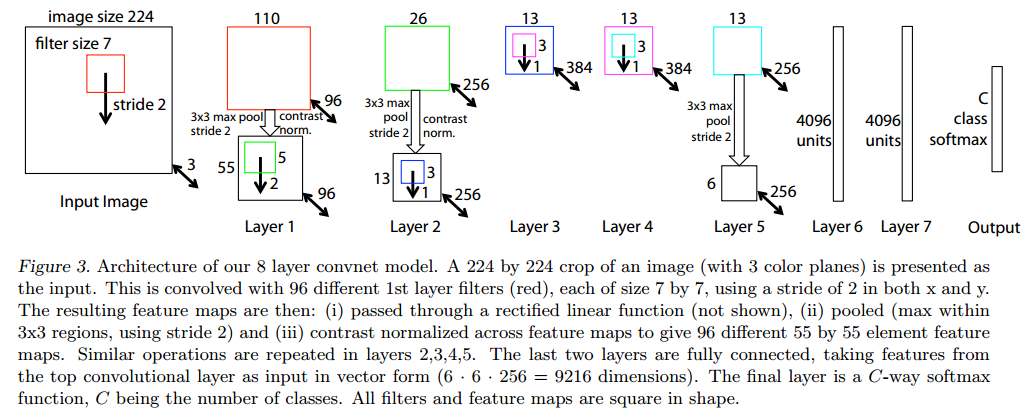
图3 本文使用8层卷积网络模型。输入层为 224*224 的3通道 RGB图像,从原始图像裁剪产生。层1 包含了 96个卷积核(红色表示),每个核大小为 7*7 ,x和 y方向的跨度均为2。获得的卷积图进行如下操作:1 通过矫正函数 relu(x) = max(0, x),使所有卷积值均不小于0(图中未显示);2 进行 max pooling 操作(3*3 区域,跨度为2);3 对比度归一化操作。最终产生 96个不同的特征模板,大小为 55*55。层2, 3, 4, 5都是类似操作,层5输出 256个 6*6 的特征图。最后两层网络为全连接层,最后层是一个 C类softmax函数,C为类别个数。所有的卷积核与特征图均为正方形。

图4 模型特征逐层演化过程。从左至右的块,依次为层1到层5的重构特征。块展示在随机选定一个具体输出特征时,计算所得的重构输入特征在第 1, 2, 5, 10, 20, 30, 40, 64 次迭代时(训练集所有图片跑1遍为1次迭代),是什么样子(1列为1组)。显示效果经过了人工色彩增强。

图5 图像的垂直移动,尺度变换,旋转以及卷积网络模型中相应的特征不变性。列1:对图像进行各种变形;列2和列3:原始图片和变形图片分别在层1~层7所产生特征间的欧式距离。列4:真实类别在输出中的概率。
图6 (a)层1输出的特征,还未经过尺度约束操作,可以看到有一个特征十分巨大;(b)(Krizhevsky et al 2012)第1层产生的特征;(c)本文模型第1层产生的特征。更小的跨度(2 vs 4),更小的核尺寸(7*7 vs 11*11)从而产生了更具辨识度的特征和更少的“无用特征”;(d):(Krizhevsky et al 2012)第二层产生的特征;(e)本文模型第二层产生的特征,很明显,没有(d)中的模糊特征。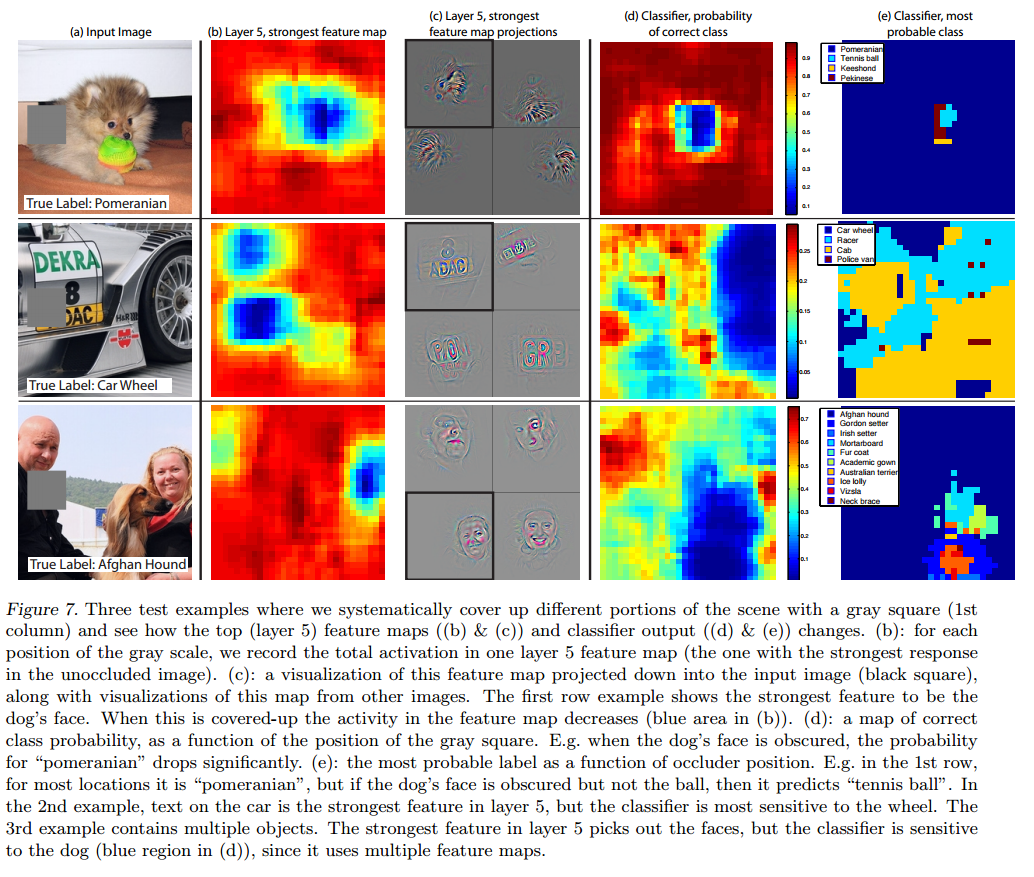
图7:输入图片被遮挡时的情况。灰度方块遮挡了不同区域(第1列),会对第5层的输出强度产生影响(b和c),分类结果也发生改变(d和e)(b):图像遮挡位置对第5层特定输出强度的影响。(c)将第5层特定输出特征投影到像素空间的情形(带黑框的),第1行展示了狗狗图片产生的最强特征。当存在遮挡时,对应输入图片对特征产生的刺激强度降低(蓝色区域表示降低)。(d)正确分类对应的概率,是关于遮挡位置的函数,当小狗面部发生遮挡时,波西米亚小狗的概率急剧降低。(e)最可能类的分布图,也是一个关于遮挡位置的函数。在第1行中,只要遮挡区域不在狗狗面部,输出结果都是波西米亚小狗,当遮挡区域发生在狗狗面部但有没有遮挡网球时,输出结果是“网球”。在第2行中,车上的纹理是第5层卷积网络的最强输出特征,但也很容易被误判为“车轮”。第三行包含了多个物体,第5层卷积网对应的最强输出特征是人脸,但分类器对“狗狗”十分敏感(d)中的蓝色区域,原因在于 Softmax 分类器使用了多组特征(即有人的特征,又有狗的特征)。
图8 其他用于遮挡实验的图片,第1列:原始图片,第2,3,4列;遮挡分别发送在右眼,左眼和鼻子部位;其余列显示了随机遮挡。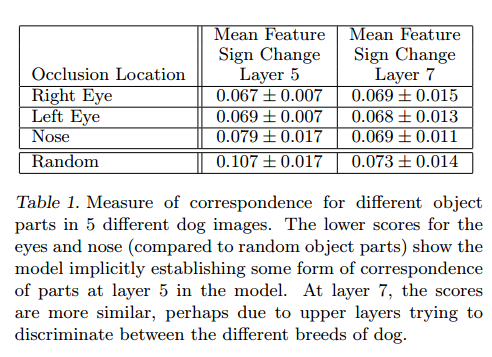


5,实验内容
5.1 ImageNet 2012
该图像库共包含了(130万/5万/10万)张(训练/确认/测试)样例,种类数超过 1000。表2显示了本文模型的测试结果。
首先,本文重构了(Krizhevsky et al 2012)的模型,重构模型的错误率与作者给出的错误率十分一致,误差在 0.1%以内,一次作为参考标准。
而后,本文将第1层的卷积核大小调整为 7*7,将第1层和第2层卷积运算的步长改为2,获得了相当不错的结果,与(Krizhevsky et al 2012)相比,我们的错误率为 14.8%,比(Krizhevsky et al 2012)的 15.3% 提高了 0.5 个百分点。
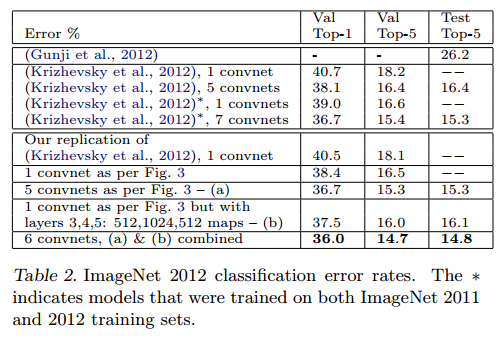
表2,ImageNet 2012分类错误率,星号表示了使用 ImageNet2011和ImageNet2012两个训练集

改变卷积网络结构:如图3所示,本文测试了改变(Krizhevsky et al 2012)模型的结构会对最终分类造成什么样的影响,例如:调节隐藏层节点个数,或者将某隐含层直接删除等等。每种情况下,都将改变后的结构从头训练。当层6, 7被完全删除后,错误率只有轻微上升;删除掉两个隐含卷积层,错误率也只有轻微上升。然而当所有的中间卷积层都被删除后,仅仅只有4层的模型分类能力急剧下降。这个现象或许说明了模型的深度与分类效果密切相关,深度越大,效果越好。改变全连接层的节点个数对分类性能影响不大;扩大中间卷积层的节点数对训练效果有提升,但也同时加大了全连接出现过拟合的可能。



5.2 特征泛化
上面的实验显示了我们的 ImageNet 模型的卷积部分在获得最新性能方面的重要性。这由图2 的可视化支持,它显示了卷积层中的复杂不变性。我们现在探索这些特征提取层的能力,以推广到其他数据集,即 Caltech-100(Feifei 等人, 2006),Caltech-256(Grifffi等人, 2006)和 PASCAL VOC 2012。为此,我们将我们的 ImageNet 训练的模型的第1~7层固定并使用新数据集的训练图像在最上面训练一个新的 Softmax 分类器(使用适当的类别数)。由于Softmax包含的参数相对较少,因此可以从相对较小的示例中快速训练,如某些数据集的情况。
我们的模型(Softmax)和其他方法(通常是线性 SVM)使用的分类器具有相似的复杂性,因此实验将我们从 ImageNet 学习到的特征表示与其他方法使用的手工标注的特征进行比较。需要注意的是,我们的特征表示和手工标注的特征都是使用 Caltech 和 PASCAL 训练集的图像设计的。例如,HOG描述中的超参数是通过对行人数据集进行系统实验确定的(Dalal & Triggs,2005)。我们还尝试了第二种从头开始训练模型的策略,即将层1~7重新设置为随机值,并在数据集的训练图像上训练他们以及 Softmax。
其中一个复杂因素是 Caltech 数据集中有一些图像也是在 ImageNet 训练数据中。使用归一化相关性,我们确定了这些“重叠”图像,并将其从我们的 ImageNet训练集中移除,然后重新训练我们的 ImageNet 模型,从而避免训练/测试 污染的可能性。


Caltech-101:我们遵循(Fei-fei等 ,2006)的程序,每类随机选择15或30幅图像进行训练,每类测试50幅图像,表4中报告了每类准确度的平均值,使用 5次训练/测试折叠。训练 30张图像/类的数据用时 17分钟。预先训练的模型在 30幅图像/类上的结果比(Bo et al 2013)的成绩提高 2.2%,然而,从零开始训练的 Convnet 模型非常糟糕,只能达到 46.5%。说明基于 ImageNet 学习到的特征更有效。
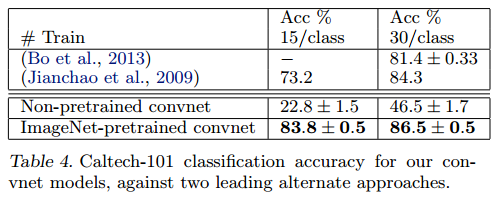

Caltech-256:遵循(Griffin et al 2006)的测试方法进行测试,为每个类选择15, 30, 45,或 60 个训练图片,结果如表5所示,基于ImageNet预先学习的模型在每类 60 训练图像上以准确率高出 19% (74.2% VS 55.2%)的巨大优势击败了历史最好的成绩。图9从另一个角度(一次性学习)描述了基于 ImageNet 预先学习模型的成功,只需要6张 Caltech-256训练图像即可击败使用10倍图像训练的先进方法,这显示了ImageNet特征提取器的强大功能。



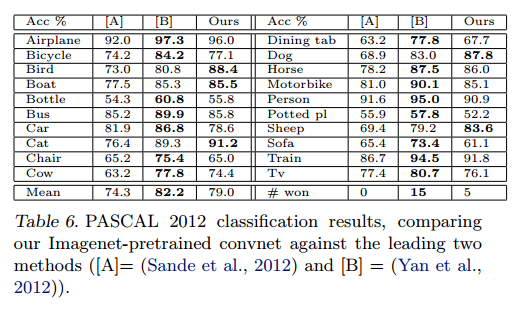
PASCAL 2012:我们使用标准的训练和验证图像在ImageNet预训练的网络顶部训练20类Softmax。这并不理想,因为 PASCAL 图像可以包含多个对象,而我们的模型仅为每个图像提供一个单独的预测。表6显示了测试集的结果。PASCAL 和 ImageNet 的图像本质上是完全不同的,前者是完整的场景而后者不是。这可能解释我们的平均表现比领先(Yan et al 2012)的结果低 3.2%,但是我们确实在 5类的结果上击败了他们,有时甚至大幅度上涨。

5.3 特征分析
我们研究了 ImageNet 预训练模型在每一层如何区分特征的。我们通过改变 ImageNet模型中的层数来完整这一工作,并将线性SVM 或者 Softmax 分类器置于顶层。表7显示了 Caltech-101 和 Caltech-256 的结果。对于这两个数据集,随着我们提升模型,可以看到一个稳定的改进,使用所有层可以获得最佳结果。该结果证明了:当深度增加时,网络可学到更好的特征。


6,讨论
我们以多种方式探索了大型神经网络模型,并对图像分类进行了训练。首先,我们提出了一种新颖的方式来可视化模型中的活动。这揭示了这些特征远不是随机的,不可解释的模式。相反,提升模型时,他们显示出许多直观上令人满意的属性,例如组合性,增强不变性和类别区别等。我们还展示了如何使用这些可视化来调试模型的问题以获得更好的结果,例如改进(Krizhevsky et al 2012)令人印象深刻的 ImageNet 2012 结果。然后,我们通过一系列遮挡实验证明,该模型虽然训练了分类,但是对图像局部结构高度敏感,并不仅仅使用广阔的场景环境。对该模型的进一步研究表明,对网络而言,具有最小的深度而不是单独的部分对模型的性能至关重要。
最后我们展示了 imageNet 训练模型如何很好地推广到其他数据集。对于Caltech-101 和 Clatech-256,数据集足够相似,以至于我们可以击败最好的结果,在后一种情况下,结果有一个显著的提高。这个结果带来了对具有小(数量级1000)训练集的基准效用的问题。我们的 ConvNet模型对 PASCAL 数据的推广程度较差,这可能源于数据集偏差(Torrarba & Efors, 2011),虽然它仍处理报告的最佳结果的 3.2%之内,尽管没有调整任务。例如,如果允许对每个图像的多个对象的使用不同的损失函数,我们的性能可能会提高。这自然也能使网络能够很好地处理对象检测。

