基于公共子序列的轨迹聚类(c#)
- 2019 年 10 月 12 日
- 筆記
前言
如今的世界中,想要研究人们的出行活动,可以利用智能手机或智能手环等个人设备生成的 GPS 数据进行研究。而在众多的研究方向中,出行的热点路线或者说经常出行的路线也比较受欢迎。采用热力图的方式对其进行研究具有许多优点。热力图给使用者的感觉就是特别直观,一眼便看出来哪些路径属于热迹(我们把热点路线,也就是重复度高的路线称为热迹)。如下图所示:
 (图片来自网上,侵删)
(图片来自网上,侵删)
从图中我们一眼便能够找出两条粗壮的热迹。这表示有某种物体经常沿着两条路线运动。但对于计算机来说,要从图中找出这两条热迹,并加以区分形成两条完整的路线可不是一件容易的事。所以我们只能直接从轨迹上入手。接下来将介绍利用公共子序列进行轨迹聚类的方法。
该聚类方法的核心思想是相似的轨迹在地理空间中占有的位置基本一致,轨迹越相似其共有的位置占原轨迹空间的比重越大,并且随着我们划分轨迹的精度降低而提高。
数据准备
Gps 数据准备
研究轨迹聚类,最基本的要求就是拥有大量的轨迹数据。幸运的,我从网上的项目中找到了公开的 Gps 数据。为什么说是幸运的?在此之前,我曾写过一个 App,以期收集自己的出行轨迹进行研究。该应用的确达到了预期,但困难的是手机要开启 Gps 才能得到比较精准的轨迹数据,这显然提高了手机电量的要求。除此之外,收集众多的轨迹需要大量时间、上班族轨迹相对固定等一系列因素导致收集自己的轨迹计划夭折。而在网上找到的数据完全满足研究要求。这些数据来自于微软亚洲研究院的项目 Geolife,是每个人都能够获取的。该数据以 plt 为文件后缀存储,但实际上就是普通的文本文件,并且除了前六行外就是 csv 格式的。
轨迹数据模型类
这是本项目中用到的数据类模型
//轨迹数据点通用模型(以接口定义) public interface IGeoInfoModel { float Latitude { get; set; } float Longitude { get; set; } } //轨迹类 public class Trajectory { public Guid Id { get; } public Trajectory() { Id = Guid.NewGuid(); } public string Name { get; set; } public List<IGeoInfoModel> GeoPoints { get; set; }//轨迹点集 public List<string> GeoCodes { get; set; }//轨迹编码集 public Trajectory Parent { get; set; }//轨迹的父亲 //轨迹的兄弟姐妹,该集合中的轨迹与该轨迹相似度极高(线程安全集合) public ConcurrentBag<Trajectory> Siblings { get; } = new ConcurrentBag<Trajectory>(); //轨迹的后辈,该集合中的轨迹与该轨迹具有一定相似性,但低于兄弟姐妹(线程安全集合) public ConcurrentBag<Trajectory> Children { get; } = new ConcurrentBag<Trajectory>(); public float MinLat => GeoPoints.Min(t => t.Latitude); public float MinLon => GeoPoints.Min(t => t.Longitude); public float MaxLat => GeoPoints.Max(t => t.Latitude); public float MaxLon => GeoPoints.Max(t => t.Longitude); public int Level { get; set; }//轨迹在族谱中的代数/层数 public string LevelTag { get; set; }//代数标签,用于打印 }轨迹序列产生(轨迹的低分辨率/低精度描述)
要找轨迹间的公共子序列,首先得有可以描述轨迹的序列的方法。该序列具有比原始轨迹低的精度,但基本可以描述一条轨迹的空间位置。下面介绍两种该项目中用到的编码方法。
保留高位小数法
最简单的就是仅保留经纬度的高位小数来进行编码。这种方式的产生的数据的精度调节有限,但也能满足一般需求。以坐标(1.2222,33.44444)来说保留三位小数后可得“1.222_33.444”,中间添加下划线是保留反解码的需求。
var digits = 3; var dig = $"F{digits}"; var code = $"{t.Latitude.ToString(dig)}_{t.Longitude.ToString(dig)}"GeoHash 法
GeoHash 是公认的计算经纬度编码的有效方法,并且精度调节能力较强。读者可以从这里进行了解Geohash 精度和原理。除此之外,GeoHash 可以得到较短的字符串,还是以坐标(1.2222,33.44444)来说,得到 7 位的字符编码“s8pycn3”。该hash码精度和直接取上面取三位小数的方式上精度接近,但字符长却缩减了 5 位。这利于高效的查找公共子序列。在 c#中我们直接 nuget 命令添加 nupkg 包NGeoHash.DotNetCore即可获得 GeoHash 的计算方法。
var code = GeoHash.Encode(1.2222,33.44444, 7);子序列的最终形式
上述两种方法皆可得到描述轨迹的序列。对于我们的公共子序列聚类来说,我们使用 GeoHash 得到轨迹序列能够得到较高的效率(花费时间基本为保留高位小数法的 60%)。此外需要注意的就是:1.该聚类方法并不关心轨迹点的先后顺序,也就是时间无关性;2.产生的轨迹序列会有重复值,但我们只关心轨迹是否在某一空间,而不关心在某一空间出现的次数,也就是重复无用性。基于以上两点,初步产生的轨迹序列需要去重,这对于查找公共子序列来说也是一种效率优化。
这对于 c#来说是极其简单的:
//并行迭代轨迹获得轨迹序列 Parallel.ForEach(tracks, t => { // t.GeoCodes = GeoHelper.GetGeoCodes(t.GeoPoints, 3).ToList();//保留高位小数法 t.GeoCodes = t.GeoPoints .Select(tt => GeoHash.Encode(tt.Latitude, tt.Longitude, 7)) .Distinct() .ToList();//GeoHash法 });轨迹相似度的计算
在得到每条轨迹的序列基础上,我们可以进行轨迹的相似度计算。而轨迹相似度可以归结为轨迹序列间的公共子序列占原始序列的比率。
//array为轨迹列表,ibf为索引1,jaf为索引2,计算GeoCodes的交集 var intersect = array[ibf].GeoCodes.Intersect(array[jaf].GeoCodes).ToList(); //公共子序列的个数转为浮点型,避免下一步计算为整形时结果直接归零 var intersectCount = (float) intersect.Count; //公共轨迹(子序列)的与轨迹1的相似度 var rateIbf = intersectCount / array[ibf].GeoCodes.Count; //公共轨迹(子序列)的与轨迹2的相似度 var rateJaf = intersectCount / array[jaf].GeoCodes.Count;轨迹族谱的生成
得到轨迹相似度后,我们定义了两个阈值:一个为兄弟姐妹相似度scaleSimilar,一个为后代相似度scaleBlood。注意,兄弟姐妹相似度总是比后代相似度的值要大。根据这两个阈值,我们可以进行轨迹族谱的生成。如果相似度rateIbf和rateJaf都大于scaleSimilar,说明两条轨迹极为相似,被定义为兄弟姐妹。如果都大于scaleBlood,并且rateIbf大于rateJaf,则轨迹 2 是 1 的后代,反之 1 是 2 的后代。
以下是这个算法的核心:
//构建轨迹树(族谱) public IEnumerable<Trajectory> BuildClusterTree(IEnumerable<Trajectory> trajectories, float scaleSimilar = 0.8f, float scaleBlood = 0.6f) { var array = trajectories.OrderByDescending(t => t.GeoCodes.Count).ToArray(); for (var ibf = 0; ibf < array.Length; ibf++) { Parallel.For(ibf + 1, array.Length, jaf => { if (array[jaf].Level == 1) return; var intersect = array[ibf].GeoCodes.Intersect(array[jaf].GeoCodes).ToList(); var intersectCount = (float) intersect.Count; var rateIbf = intersectCount / array[ibf].GeoCodes.Count; var rateJaf = intersectCount / array[jaf].GeoCodes.Count; if (rateIbf >= scaleSimilar && rateJaf >= scaleSimilar) { array[jaf].Level = 1; array[ibf].Siblings.Add(array[jaf]); array[jaf].Siblings.Add(array[ibf]); } else if (rateJaf > rateIbf && rateIbf >= scaleBlood) { array[jaf].Level = 1; array[jaf].Parent = array[ibf]; array[ibf].Children.Add(array[jaf]); } else if (rateIbf > rateJaf && rateJaf >= scaleBlood) { array[ibf].Level = 1; array[ibf].Parent = array[jaf]; array[jaf].Children.Add(array[ibf]); } }); } var root = array.Where(t => t.Level == 0 ).ToList(); SetClusterTreeLevelInfo(root); return root; } //设置代数及标签信息 private void SetClusterTreeLevelInfo(IEnumerable<Trajectory> tree,int level = 0, string levelTag = "") { Parallel.For(0, tree.Count(), i => { var node = tree.ElementAt(i); node.Level = level; node.LevelTag = $"{levelTag}{i}"; for (var j = 0; j < node.Siblings.Count; j++) { var sib = node.Siblings.ElementAt(j); sib.Level = level; sib.LevelTag = $"{node.LevelTag}__{j}_sim"; } SetClusterTreeLevelInfo(node.Children, level + 1, $"{node.LevelTag}_"); }); }结果展示及说明
我们直接上最终的轨迹族谱图的展示
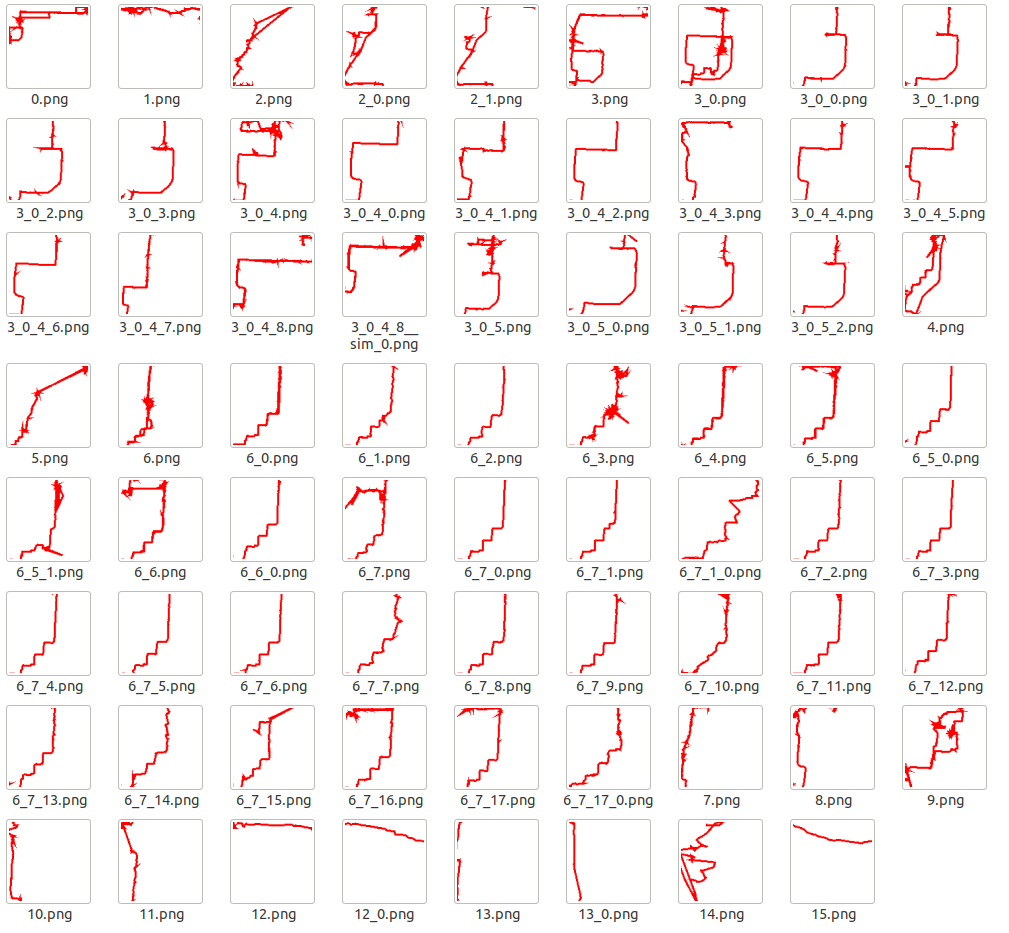
读者放大后应该能够看清图片的文件名,文件名是代数标签。以“3.png”和“3_0.png”来说,“3.png”是“3_0.png”的父亲。对应的,后者是前者的孩子(所有轨迹对于都是自适应固定大小的图片画的,所以缩放比例和整体偏移会导致看起来有差别。读者仔细观察能够发现 3_0 只是 3 的左下角一部分)。而对于“3_0_4_8.png”和“3_0_4_8__sim_0.png”来说则互为兄弟姐妹(缩略图与自适应的确影响了结果的查看)。
此外,我们能够看出第 3 和第 6 是两个大家族。如果利用所有轨迹的数据生成热力图,那么 3 族和 6 族所经过的地方热力值相对来说要高很多。把一个大家族的所有成员轨迹叠加后可以得到我们想要的热迹。
总结
该算法如果不用并行计算是一个时间复杂度为:O(n^2)的算法“n(n+1)/2”。而改为并行计算后,效率有很大提升(由于直接采用并行计算,不知道提升了多少)。示例中71条轨迹生成族谱树仅需25毫秒左右,而1988条轨迹需要7.5秒左右。从效率和结果上来说都达到了令人满意的程度。另外,该项目已经上传github,访问请点击QianMo,欢迎大家提出修改意见。

