GIT原理介绍
- 2019 年 10 月 12 日
- 筆記
Git 是一套内容寻址文件系统。很不错。不过这是什么意思呢? 这种说法的意思是,Git 从核心上来看不过是简单地存储键值对(key-value)。它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。
我们都知道当我们初始化一个仓库的时候,也就是执行以下命令后,文件夹内会生成一个.git文件夹,
git init内部会包含,以下文件夹。
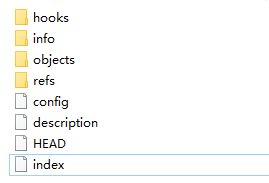
- hooks //钩子文件夹,内部文件实际上就是一些特定时间触发的shell脚本,我们可以简单的做一个部署系统,每次提交特定tag的时候,则部署最新的代码到服务器。
- objects //真正的内容存放的文件夹,下面重点讲下这里。
- refs //refs目录存放了各个分支(包括各个远端和本地的HEAD)所指向的commit对象的指针(引用),也就是对应的sha-1值;同时还包括stash的最新sha-1值
- config //git配置信息,包括用户名,email,remote repository的地址,本地branch和remote branch的follow关系
- HEAD //存放的是一个具体的路径,也就是refs文件夹下的某个具体分支。意义:指向当前的工作分支。项目中的HEAD 是指向当前 commit 的引用,它具有唯一性,每个仓库中只有一个 HEAD。在每次提交时它都会自动向前移动到最新 的 commit
- index //存放的索引文件,可使用 git ls-files –stage 查看。应该zlib加密后的,PHP可使用gzdeflate()函数
这是objects文件夹,可以看到都是些数字和字符,实际上就是十六进制数。
下图是进入00文件夹后所有文件。
认识下GIT对象: blob对象, tree对象, commit对象
1.创建blob对象
下面我们直接上底层命令, 运行此命令后,会在 .git/objects 文件夹下生成一个 两个字符 的文件夹,文件夹内部文件即类似上图中文件一样。
echo 'test' | git hash-object -w --stdin git hash-object -w test.txt分解命令:
hash-object: 计算文本内容的sha-1(哈希值) -w : 加上此参数后,会把内容写入/objects文件夹,不加则仅仅是计算(不可使用此法单纯做计算用,因为GIT计算的HASH,其基础内容与原内容有所区别) --stdin : 此参数接收来自于标准输入的内容,即前面的 echo 'test'; 不加此参数,则直接写入某个文本所以实际上我们看到的,objects 文件夹下的内容,文件名实际上是 hash 值。文件夹是40个字符的前两个(拥有相同前2位的hash值会被分配到同一个文件夹中), 具体文件名则是后面38个字符。使用hash值的原因就在于,位数够多,并且hash值唯一,一点小变化,都会生成新的hash值,和md5算法是一样的道理。
注意:此hash值就像是GIT的指针,能唯一对应某一个具体的内容或提交,hash值作为寻址作用,不作为内容存储用,具体的文件内容存储方式是GIT更底层的存储方式决定。(sha-1和md5一样,均是不可逆的)
通过Linux find 命令查看所有已存储的hash文件:
find .git/objects -type f通过 cat-file 命令可以将数据内容取回。该命令是查看 Git 对象的瑞士军刀。传入 -p 参数可以让该命令输出数据内容的类型:
git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 test content通过 hash-object 命令,会把每一个文件的内容都给记录下来, 以此生成一个blob对象。可通过以下命令查看对象的类型
git cat-file -t d670460b4b4aece5915caf5c68d12f560a9fe3e4 blob在实际项目过程中,不会这么简单,因为我们每次提交都是一个多文件的提交。很少的时候是单文件的,那此时Git就不是单单存储一个 blob对象了,而是 tree对象,
tree对象,见名知意,就是一个树对象,类似于操作系统目录,tree的分支,可能还是tree,也可能是blob,这就看实际的场景了。
对象存储方法:
GIT使用 zlib 库 的 deflate方法对数据内容进行压缩,但内容为 "blob 字符串长度+空字节+字符串本身"; 如:
blob 3�aaa2.创建tree对象
上面说的创建blob对象,仅仅只是对某一个文件进行的计算与存储,而我们实际项目中,可能每一次操作都是好几个,甚至十几个文件一起,那如何才能把他们组织到一起,这就是 tree 对象的作用了。
要创建tree对象,需要使用 update-index,write-tree 命令:
git update-index --add a.txt //此命令即可将a.txt加入到暂存区, git write-tree //此命令即写入tree对象。 or git update-index --add --cacheinfo 100164 sha-1 a.txt git write-tree –cacheinfo 会从已存在的数据库(Object)中取得对应的内容给添加到索引中。
实际生产中,一般情况下,会把末尾文件夹中的所有修改文件创建,blob对象,再对该文件夹(也就是所有的blob对象整体)进行write-tree的操作,得到一个tree对象,反复进行此操作,最后得到多个tree对象和多个blob对象。
如上所说,若需要对某个存在三级文件夹的二级文件夹进行write-tree操作, 在把三级文件夹下的所有修改文件生成blob后,进行整体tree对象化,之后再与二级文件夹同级的文件夹和文件进行相同操作。此时就需要用到: read-tree 命令。如:
git read-tree --prefix=test_add_tree c08670e3f77cae748fbda5c0b83613d5f5995655 //该操作会把tree对象b822ff7272492f12b211d3b9c0f90163f48383bb 加入暂存区中,并取名test,之后再进行write-tree就把tree对象b822ff7272492f12b211d3b9c0f90163f48383bb 给加入了 //从实际生产来看,GIT会把此prefix默认为文件夹的名字 git cat-file -p dc054e0c59565791c70a1f6d6ad7d6676baf0349 100644 blob 765dc741c088b3baef0314a457f74c877a43405b a.txt 100644 blob 7609a432a0ba538cfe3d7bbdb107096c2f010577 b.txt 100644 blob b114c2d776f5dd25dc75a2c7a81f99262d618bc3 c.txt 040000 tree c08670e3f77cae748fbda5c0b83613d5f5995655 test_add_tree3.创建commit对象
平时我们都是用** git commit -m "xxxx"** 提交了信息, 在这之前,会暂存相关文件的改动, 在提交后,会生成对应的tree对象,返回tree所对应的 sha-1值, 再进行一次 commit-tree 操作,最后会把刚保存的tree对象所对应的sha-1值 赋值给 commit-tree, 即生成了一个commit 对象。用法:
echo '提交信息' | git commit-tree b822ff7272492f12b211d3b9c0f90163f48383bb (对应的tree对象返回的 sha-1值) f7bc39001ff6cb183022234c94aa61ddedee44e0通过 git cat-file -p f7bc39001ff6cb183022234c94aa61ddedee44e0 得到:
tree b822ff7272492f12b211d3b9c0f90163f48383bb //该commit对象指向的tree对象 author max.hua <****@****.cn> 1563847402 +0800 //config中指定的user.name信息 committer max.hua <****@****.cn> 1563847402 +0800 //config中指定的user.email信息 first commit我们还可以给某一个commit对象指定它的父commit对象:
echo 'second commit' | git commit-tree b822ff7272492f12b211d3b9c0f90163f48383bb -p f7bc39001ff6cb183022234c94aa61ddedee44e0 (父级commit对象sha-1值) 42e08b70c341b7e60944de6dffc342b77f94f6e4通过 git cat-file -p 42e08b70c341b7e60944de6dffc342b77f94f6e4得到:
tree b822ff7272492f12b211d3b9c0f90163f48383bb parent f7bc39001ff6cb183022234c94aa61ddedee44e0 //指向的父级commit对象 author max.hua <****@****.cn> 1563848153 +0800 committer max.hua <****@****.cn> 1563848153 +0800 second commit想要查看我们使用管道命令生成的log记录: git log –stat 42e08b70c341b7e60944de6dffc342b77f94f6e4 ,得到:
git log --stat 42e08b70c341b7e60944de6dffc342b77f94f6e4 commit 42e08b70c341b7e60944de6dffc342b77f94f6e4 Author: max.hua <****@****.cn> Date: Tue Jul 23 10:15:53 2019 +0800 second commit commit f7bc39001ff6cb183022234c94aa61ddedee44e0 Author: max.hua <****@****.cn> Date: Tue Jul 23 10:03:22 2019 +0800 first commit a.php | 6 ++++++ b.txt | 1 + c.txt | 1 + 3 files changed, 8 insertions(+) 从上面的用法可以得到, git commit-tree 生成的 commit对象,只会包含 tree对象,参数选项中没有可以指定blob对象的参数。
如下:在测试时,强制使用blob对象的 sha-1值,会出现报错现象。
echo '第一次提交' | git commit-tree e56e15bb7ddb6bd0b6d924b18fcee53d8713d7ea fatal: e56e15bb7ddb6bd0b6d924b18fcee53d8713d7ea is not a valid 'tree' object4.应用
以上基本上就可概括平时使用git add 和 git commit 命令时GIT的工作。
- 保存已修改文件成blob格式对象: git hash-object -w 各个文件
- 更新索引: git update-index –add 各个文件名 或者 git update-index –add –cacheinfo mode sha-1 文件名 或者 git read-tree –prefix=test sha-1(某个tree的sha-1) ,作用在于把某个tree读入索引中
- 创建树对象: git write-tree
- 最后创建commit对象: git commit-tree sha-1 -m "提交信息" 或者 echo "提交信息" | git commit-tree sha-1 -p 父级sha-1
4.1 git add
平时我们在使用的时候,使用 git add c.txt 后,把 c.txt 放入了暂存区, 而实际上此时已经生成了blob对象,并保存了相应的sha-1值命名的文件,同时添加到了索引文件中;之后当我们修改了之前添加到暂存区的文件并使用 git status 查看状态的时候,GIT会再对文件进行一次 hash运算,如果发现和已存在与索引中的内容产生了变化(sha-1值不同),则又会呈现出一个 Modify 状态。
通过以下命令可查看到 .git/index 文件中的内容,其中存放了每一个被追踪的文件,对应的blob对象最新的sha-1值, 通过这里即可很直接的判断出哪个文件是否被修改,哪些没有被追踪了。
git ls-files --stage 100644 45c2647671db4e9d426c2085eba814fea16f6b9a 0 b.txt 100644 177308c04fc55b0d9985a7dfb545f6cebb7ea432 0 c.txt4.2 git diff
同上, 使用 git diff后, 会把文件的差异给列出来,而对比对象即是 索引中的内容,并不是HEAD指向的内容。 当对某文件执行了 git add 后,之后再进行修改,再使用git diff 查看区别, 你会发现已经存在区别了。也就是说,git diff 实际上是把当前文件与索引中的文件进行比较(通过sha-1值比较),当有不同的情况,则列出对应的改变。
4.3 git status
使用 git status 后,GIT会对所有文件进行sha-1值计算,若计算到与前面讲到的 索引中得对应文件的sha-1值不同了,则代表有所改动,则标记为 Modify,若发现索引中不存在对应文件的sha-1值, 则标记为 Untracked files。
4.4 git branch 分支名
该命令会生成一个新分支,也就是在 .git/refs/heads里面生成一个新的文件,文件名为分支名,如果有前缀feature之类的。则feature是文件夹名,其内是文件名。文件内容为当前的 commit 对象对应的sha-1值。所以实际上分支,也是一个 commit 对象的引用。只是在GIT中专门有文件记录了分支名和指向。我们甚至可以通过创建文件的方式,直接创建branch。
cd .git/refs/head/ echo 'e56e15bb7ddb6bd0b6d924b18fcee53d8713d7ea' > test_aaa4.5 git checkout 某分支
当使用 git checkout 的时候, GIT内部实际上就是把当前的HEAD指针给指向了另一个分支,而实际上也就是把 .git/HEAD 文件内容修改为切换的分支,而 .git/HEAD 内容指向的就是 .git/refs/heads中的分支,此文件内容又是一个 commit 对象的 sha-1值,所以也就间接指向了某个具体的 commit对象了, 从这个commit对象可得到它的父级对象,依次类推,即可得到完整的代码。
git update-ref HEAD <newvalue>有时候,我们在使用PHPStorm的时候,会用到"Annotate", 就是查看本文件的GIT提交记录,还会查看某个提交下以前的版本的文件,看具体是修改了啥。"Amnotate previous revision",实际上就是做了
git checkout sha-1 文件名 //该命令就会把某文件给恢复到某个提交的时候,不加文件名的话,就是恢复整个项目到某个提交的时候4.6 git commit -m "提交信息"
见如上信息。
4.7 git log
使用该命令后,去 .git/logs 下寻找当前分支对应的文件名,文件中的内容即为每一次提交的信息。
4.8 git push
使用git push 是把当前的分支上传到远程仓库,并把这个 branch 的路径上的所有 commits 也一并上传。 我认为实际就是修改了.git中的文件,因为这些文件里实际上就已经包含了压缩后的代码,等你切换分支的时候,GIT会根据这些内容把代码给检索出来。
4.9 git tag [version name]
使用 git tag 实际上和 git branch 类似,branch 是指向某一个commit的指针,但是branch会随着每次提交而移动, 但是tag不会, 当打了tag后, 那这个 tag 对应的commit对象指针就固定了,不会移动了。它和 git branch 一样,都不会产生blob或 tree 对象, git tag 只会在 .git/refs/tag 下生成一个 tag名的文件,内容为指向当前commit的sha-1
4.10 git stash
使用git stash 实际上是创建了一个新的commit对象,为什么这么说呢?在 .git/refs 目录下,当第一次stash后,会生成一个 stash文件, 内容即为一个sha-1值, 通过 git cat-file -p查看到具体内容为一个 commit对象的内容, 还能看到其有两个 父级 commit, 一个是前一个 git commit 的sha-1值, 一个是执行stash后,新生成的commit。最后把这两个commit对象作为父亲,再生成一个commit对象存放于stash文件中。
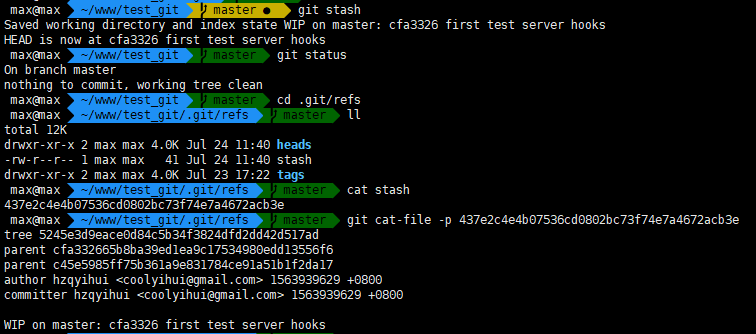
疑问:
-
git commit-tree的时候,是怎么指定父级commit对象的,以什么为参考,才能指定对应的父级commit对象。我从平时工单的log记录来看,有些commit对象有两个父级commit对象(可能是合并操作的时候自动生成的commit对象),但不一定就是前一个commit。(git stash 有两个父级对象)
- 我们都知道git stash 存的是一个栈的结构,但是 .git/refs/stash 文件里 只有一个sha-1值,只对应一个commit对象,我查看了commit对象的具体内容,他的两个父亲均不是我前一个创建的stash对应的commit对象,不知道这个栈的结构怎么来的。
-
看某项目的树结构,会发现,每一个commit对象内部对应的 tree,都是一整个项目,而不是某一个文件或者某几个文件夹,这就解决了我的疑惑, 每次只需 git update-index –add 后,我想新创建一个 tree对象, tree对象内部一直会存在之前加入index中的blob对象。 那么GIT实际上就是每一个commit,都应该能从tree和 p-tree上追溯到整个项目文件。
-
在手动创建分支的过程中,发现在执行 git init后,看起来你是在master分支, 但是实际执行 git branch,看不到任何输出,这说明在这个时候实际上master分支是没有创建的,必须要有第一次提交后,master分支才会创建,因为只有这样 , .git/refs/head/master 文件中才有可写的 commit 对象的 sha-1值。
需要注意:对commit对象的跟踪,commit对象能跟踪到具体哪一次修改,改了哪些具体文件,通过对commit的切换,就能找到某个时间点的文件记录了。GIT每次提交文件,实际上都是提交的整个文件,而不仅仅是修改的部分。所以当我们执行一些回退操作的时候能回到某个时间点的文件,即直接指定某个commit对象,查到commit对象中包含的各类tree对象和blob对象,把这些对象中压缩内容给取出来覆盖当前的同级,同名文件即可;同时新增的,给删除了。
