AnalyticDB实现和特点浅析
本篇主要是根据AnalyticDB的论文,来讨论AnalyticDB出现的背景,各个模块的设计,一些特性的解析。可能还会在一些点上还会穿插一些与当前业界开源实现的比对,希望能够有一个更加深入的探讨。OK,那我们开始吧。
AnalyticDB介绍与背景
要说AnalyticDB,那起码得知道它是干什么的。这里直接贴下百度百科的介绍:
AnalyticDB是阿里云自主研发的一款实时分析数据库,可以毫秒级针对千亿级数据进行即时的多维分析透视。
简单地说,就是实时OLAP型数据库,它的对标产品是Apache Kylin,Apache Druid,Clickhouse这些。然后AnalyticDB的特点,包括高并发实时摄入数据,兼容Mysql协议,无需预计算即可有的极快响应时间,多种数据源接入,大规模集群管理等。好吧,这几个特点都很官方,不急,接下来会逐渐讨论各个点。
然后介绍下AnalyticDB的背景。
首先先说说传统的OLAP型数据仓库,以往构建OLAP型数据仓库通常都是采用离线模式,即在晚上设置定时任务将前一天的数据同步到数据仓库中,第二天数据分析师或报表工具就可以根据数据产出分析结果。但这样的问题是数据延迟太高了,商业瞬息万变,可能今天线上出现了什么订单激增的情况,数据分析师却要等明天才能进行分析,这谁受得了呀。所以近几年的趋势就是实时数仓,简单说就是增加一个实时接收数据以供查询的模块,这也叫做lambda架构。如图,就是用一个Batch层和一个Real-time层共同提供查询结果。[1]

好像有点扯远了,说回AnalyticDB,它就是在大背景下提出的,所以它的一个主要特性就是实时。然后由于它本身是云原生的结构,也就是本身就是根植于阿里云上面的,面向的客户更加广泛,所以是有通用性的要求的。比如传统企业都是使用Mysql,Postgresql等关系型数据库,这些企业也没有人力去搭建和维护Hadoop和Kylin,Druid这些集群。而Postgresql这类关系型数据库可能会有对复杂结构对支持,比如json,vector等,所以AnalyticDB也提供了对这种复杂类型的支持。
在性能方面,AnalyticDB维持所有列的索引,用以快速检索数据。在存储方面,使用行-列混合存储,使得AnalyticDB可以同时对OLAP分析和行级查询快速响应。然后为了高并发的查询和高吞吐的写入,又提出了读,写分离。这几个性能方面的特性,以及这些优化如何与实时查询结合起来,在后面会详细介绍。
总而言之,目前业界对海量数据的OLAP分析查询方案无非两种,通过预计算构建多维立方体,在查询的时候直接读取预计算好的数据做一些简单的合并(因为分区存储)然后返回给用户。这种类型的代表是Kylin和Druid,它们的好处是比较简单,OLAP分析查询速度很快,缺点是不够灵活,比如Kylin一点改动可能就要全部数据rebuild。
另一种是非预计算,充分利用各种资源(CPU,内存,列存储,向量化执行),或是架构尽量优化(如AnalyticDB),来让海量数据快速查询得到结果。比较典型的代表是Clickhouse,查询性能不赖,也相对灵活,但缺点是集群数据量没法拓展到很大。
这两种方案都有办法这实时这个点上进行拓展,只是实现思路也不大一样。第一种是添加一个流式层,OLAP查询的时候分别查询历史数据和流式层数据然后合并返回。第二种则是用微批方式倒入数据仓库中实现流式查询。
整体上,AnalyticDB更加偏向于第二种非预计算的方式实现,不过在很多设计上还考虑了行级查询的实现和性能,所以要比Clickhouse这种要复杂一些。下面我们从几个方面来讨论它的实现。
AnalyticDB详细解析
AnalyticDB是一个能够在PB数据集上高并发,低延迟,实时分析查询,并且能够在2000+云服务器上运行的OLAP数据库。在设计上有多个挑战,需要兼顾多种查询类型的性能要求。这里的多种情境包括全表扫描分析,多表join的点查询操作,多个列的多个筛选条件等等,而这些操作又难以优化。
第二个挑战是要设计一个底层存储,应对不同类型的查询所需要的不同存储结构。比如OLAP查询需要列式存储,而点查询(行级查询)需要行式存储。如何将这两种存储结构(列式,行式)结合起来以供不同查询类型使用,同时还需要考虑到复杂类型,json,vector,text等,这也是一个难点。
第三个是实时方面的,要如何做到每秒数百万数据写入吞吐的同时,呈现给用户低延迟的查询响应和数据延迟。以前的做法将读写操作交由同一进程处理,但这样一来读写操作的性能是互斥的,即高吞吐的写入会影响到查询性能和数据延迟[2]。
为了解决上述挑战,AnalyticDB引入以下特性:
- 高效的索引引擎
- 混合(列-行)存储引擎
- 读写分离
- 高效检索引擎
这些特性暂时就有个映像就好,后面会详细对这部分阐述。
架构设计
要说这块,我们先来看看整体的架构设计图。
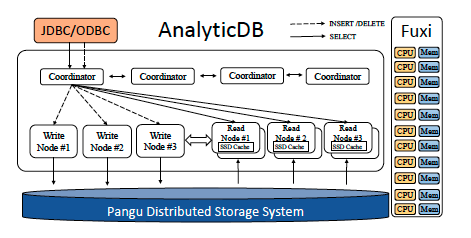
前面与说到,AnalyticDB是云原生的,AnalyticDB主要依赖于两个外部结构,任务管理与调度组件Fuxi,和分布式存储系统Pangu,而这几个组件又都是基于阿里云的Apsara(负责管理底层的物理主机并向上层提供服务)。
整体架构上看还是比较简单的,主要就是对外提供JDBC/ODBC接口,内部由多个协调器(Coordinator)负责统一管理写节点和读节点(读写分离)。
- 协调器(Conrdinator):协调器负责接收JDBC/ODBC的读写请求,分发到不同的读或写节点。
- 写节点(Write Node):负责处理写请求并将数据写入到Pangu中持久化。
- 写节点(Read Node):负责处理查询请求并返回。
在具体的处理流程中,Fuxi资源分配和异步调度(类似yarn)。而数据计算则是使用管道的方式进行计算,如下图:
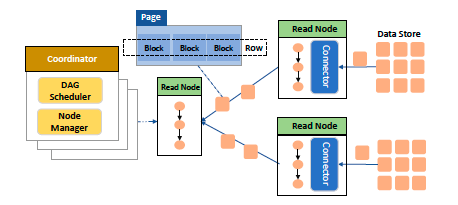
图中,数据按页(Page)进行切分(Pangu的存储特性),数据处理以管道的方式进行处理,且数据流转的不同阶段均在内存中执行。看这张图其实有点像Spark的数据处理流程,当然AnalyticDB本身也是使用DAG模型进行数据处理。
不过按照论文中说的数据完全在内存中处理还是有点不现实,虽然这样能极大提高处理的效率,但遇到数据量太大导致内存装不下的情况,还是需要暂时落到磁盘上,就类似Spark有提供多种persist方案一样。否则查询的并发量势必会受到一些影响,但这样一来可能查询响应又降低了,鱼与熊掌不可兼得啊。
数据分区
在一开始创建表的时候,可以分配数据按照两级分区进行存储,这里通过论文中的小例子阐述两级分区的实现,如以下建表语句:
CREATE TABLE db_name.table_name (
id int,
city varchar,
dob date,
primary key (id)
)
PARTITION BY HASH KEY(id)
PARTITION NUM 50
SUBPARTITION BY LIST (dob)
SUBPARTITION OPTIONS (available_partition_num = 12);
第一级索引,可以让数据按照指定列进行hash分区以及指定分区数,比如上述建表语句指定一级索引为id,分区数是50个。这样可以让数据根据id的hash值分布到不同的50个分区中,这一列通常是使用高基数的列,诸如用户Id等。
第二级索引(SUBPARTITION,可选)可以针对某个列指定最大分区数,用来对数据保留和回收,通常使用日期类型数据。比如如果指定按天进行分区,最大分区为12,那么数据仅会保留12天内的数据。
读写分离和读写流程
大多数传统的OLAP数据库,都是使用一个线程负责处理用户SQL的操作,不管是写请求(Insert)还是读请求(Select)。这在查询和写入的并发量都很高的情况下会出现资源争用的情况,针对这种情况AnalyticDB提出读写分离的解决方案。写节点负责写,读节点负责读数据,两种节点彼此分离,这样就避免了高并发场景下读写资源互斥的情况。
写节点主要是master和worker架构,由zookeeper进行协调管理。写master节点负责分配一张表的分区给不同的写worker节点。在一个SQL到达的时候,Coordinators会首先识别是读还是写SQL语句,若是写,那么会先发送到对应的写worker节点,写worker节点先将数据存到内存,定期以日志的形式持久化到Pangu中形成Pangu日志。当日志一定规模的时候,才会构建真正的数据和全量索引。
而对于读节点,同样每个节点会被实现分配不同的分区。功能上,AnalyticDB有两种读模式,实时读取(real-time read),写入数据立即可读,和延迟读(boundedstaleness),即容忍一定时间的写入数据延迟。延迟读是默认采用的方式,虽然与一定数据延迟,但查询响应更快,通常而言也足够了。
而实时读,那么可以立即查询到刚刚写入的数据。之所以能这么快,其中一个原因是读节点会直接从写节点中获取更新数据,也就是说写节点在某种程度上说充当了缓存。其他的OLAP数据库的做法通常有两种,一种是用一个segment专门存储实时数据,OLAP查询的时候,会扫描实时segment和离线数据,合并后返回用户,比如最新的kylin streaming就是这样实现。一种是微批导入数据到存储引擎中,然后用以检索,这样的话写入频率(微批的间隔)会大大影响检索性能。AnalyticDB的方式可以说是一种比较新颖的方式,借助读写分离的架构和强大的索引能力(下面介绍),可以实现实时写入且低延迟检索。
不过其实这会面临一个问题,数据同步的一致性问题(读写节点数据不一致),AnalyticDB是怎么做的呢?这里也不卖关子,主要是使用一个版本号来处理。Coordinators在分发写请求给写节点,写节点更新后会返回更新后的分区版本号给Coordinators。Coordinators分发读请求给读节点时,也会带上这一个分区版本号,读节点就会与自己缓存的版本号对比,发现自己小的话,就会去拉取写节点的最新数据(写节点有一定的缓存功能)。
可以发现,通过读写分离的机制,以及预先分配好读/写节点的数据分区(hash),能提高数据处理的并行度,并且减少数据计算产生的数据传输网络开销,比如join的shuffle操作就不需要进行大规模的数据再分区。而后有能够将两种请求相互解耦,每种操作关心自身就可以,方便以后的拓展。
OK,到这里系统的架构,数据分区,读写流程就差不多说完了,接下来再讨论下它的其他特性。
其他特性介绍
混合(列-行)存储引擎
先说下背景,OLAP查询一般会有全表扫描操作,所以主流做法是使用列式存储,因为列式存储可以极大减少磁盘IO操作,提高提高全表扫描性能,但这种对点查询(即行级别)查询和更新等不甚友好。而如Mysql这种行级存储,点查询方便,但OLAP操作又会又额外更多开销(数据压缩比低)。许多主流系统的做法是,基本摒弃另一种功能,比如Mysql不适合做大规模OLAP查询,Kylin,或者说hive这种不支持行级别更新(特殊情况下可以,但支持不好),Druid则更加极致,直接就不存明细了。
而AnalyticDB却通过行-列混合存储结构,不仅兼顾OLAP分析和点查询,还实现了复杂类型的存储(json,vector)。不过在介绍它的行-列混合存储结前,先来看看流行的列式存储结构,然后再引出AnalyticDB的行列混合。
我们以开源的列式存储结构Parquet为例来看列式存储是怎么存储数据的。
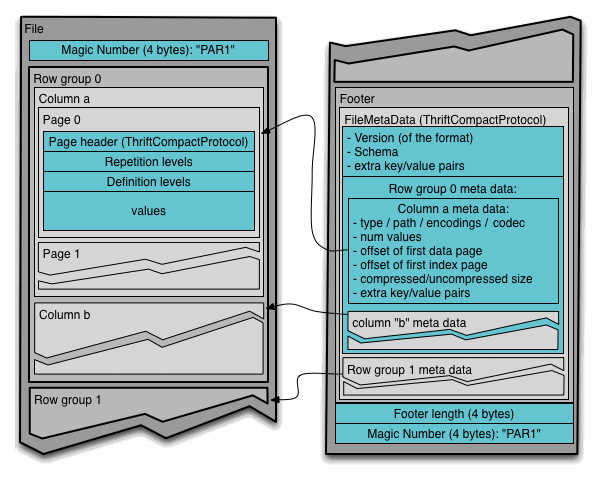
Parquet本身是hadoop底层使用的存储引擎,其强大毋庸置疑。所谓列式存储,可以简单理解成就是将一整列数据压缩打包,然后按顺序存储。
存储中有三级结构:
- 行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。一个列块由多个页组成。
- 页(Page):每一个列块划分为多个页,页是压缩和编码的单元,对数据模型来说页是透明的。在同一个列块的不同页可能使用不同的编码方式[3]。
在最后是Footer模块,这里存储的是数据的元数据信息,比如列名,列的类型。还有一些统计信息,min,max,用以提升部分检索的效率。同时Parquet也支持复杂类型的存储,说简单点就是将复杂类型Map,List等转换成schema树,把树的叶子节点当做列数据存储。
简单了解了列式存储,我们再来看AnalyticDB的行-列混合存储。
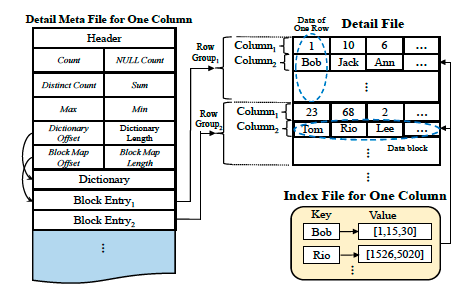
注意图中左右两部分分别是两个文件,左边的是元数据文件,存储诸如字段名,一些简单的统计信息帮助过滤,这个文件比较小通常驻存在内存中。这部分内容和前面的Parquet的Footer存储内容类似,这里就不多介绍了。主要还是介绍下右边部分,即数据存储方式。
图片右边,数据以row group的形式存储,每个row group中存储固定数量的行。但是在row group中依旧采用列式存储,即同一列的被存储到一起,称为Data bolck,所有的Data block按顺序存储(这点和列式存储一样)。而Data block是最小的操作单元(缓存,读取等)。注意这里不像Parquet那样,每一个Data block再分多个Page。
看上去,它的存储结构和Parquet是类似的,只是没有再将Data block划分成多个Page,这里论文没和Parquet对比,也没论述很清楚。不过最主要的区别应该就是这里了。为什么Data block不需要再划分?因为它没那么多数据呀,在Parquet里,一个row group的数据量是GB级别的,所以一个row group中的列需要再划分。而AnalyticDB中,它的row group明显是小数量级的,可能一个row group仅仅是MB级别的数据量。这一点细微的差别,使AnalyticDB在点查询的时候就可以直接几MB内获取一行全部数据,而Parquet可能需要在1G内才能获取一行数据。这也是为什么AnalyticDB的叫做行-列混合存储结构。
对比Parquet和AnalyticDB,它们的设计分歧可能是天生的,Hadoop适合存储追加的数据,以及非结构化数据,它的场景更多是在大数据存储和加载,所以不会考虑单行查询的场景。而AnalyticDB要考虑各种检索,所以设计上就会要差异。当然AnalyticDB这样也不是没有缺点,比如它在全表扫描性能会有所下降。
说完AnalyticDB的存储结构,再来说说AnalyticDB如何存储复杂类型数据。
复杂类型数据(json,vector)存储有个难点,这种复杂类型的数据通常大小是不定的,而且往往会出乎意料的大。如果按照上面提到row group的方式,可能一个block entry会非常大,所以需要一种其他类型的存储结构来存储复杂类型数据。
具体的做法可以说借鉴了hadoop的存储思路。既然复杂类型数据大小不一样,可能大可能小,那就将数据统一用32KB大小的块组织起来,称为FBlock。一个复杂类型数据可能分散在多个FBlock中(超过32KB),多个FBlock按顺序存储。然后使用稀疏索引,方便快速查询。这样的设计无疑可以方便得将复杂数据进行存储,同时通过稀疏索引又能在一定程度上保证检索的速度。
最后再说说如何支持update和delete操作。
一般的列式存储是不怎么支持行级更新和删除操作的,因为数据都是压缩成二进制进行存储,如果支持行级更新,那并你需要先解压缩,整块数据,然后删除数据,再压缩存储。要是并发量一上来那简直是灾难。
那hbase的底层是hadoop,它是怎样实现更新和删除的呢?这是因为hbase使用LSM-tree,我之前也过一篇介绍这个东西,也兴趣可以看看数据的存储结构浅析LSM-Tree和B-tree。粗略说就是将更新和删除操作都按key-value的形式追加到文件末尾,然后整个文件定期去重,只保留最新的key的数据,旧的key数据就被删除了。检索的时候如果也多个key,只会认最新的那个key的数据。当然具体细节要复杂得多。
AnalyticDB也是类似的思想,不过做了一些改变。它使用一个存储在内存中的bit-set结构,记录更新和删除的数据id以及对应版本号。同时使用copy-on-write(写时复制)技术提供多版本支持。更新和删除操作都会改变版本号,然后查询的时候会提供一个版本号去查找对应的更新和删除信息,然后在查询结果中和结果进行合并。这样就实现了更新和删除操作。
稍稍总结下AnalyticDB的存储结构,行-列混合存储的优势确实是也的,它算是牺牲一部分OLAP查询的性能,换取一些灵活性。而这样的换取,使得它拥有快速行级检索,更新删除的能力,对AnalyticDB而言是值得的。
索引
索引可以说是一个数据库系统中极为重要的优化设计。目前主流的索引,包括B+tree,倒排索引,稀疏索引等等,但它们都有各种局限,比如B+tree插入分裂代价太大,倒排索引只支持特定类型,有些索引虽然能提供快速检索的能力但对写入性能有负担。那么AnalyticDB的索引是怎样实现的呢?
AnalyticDB重度使用倒排索引加速检索效率,首先,AnalyticDB对每一列都建立一个倒排索引,索引的key是列的值,索引的值的列的行号。前面的存储结构中可以看到,每个row group存储的是固定的行数,所以可以快速检索到对应的行。而针对不同的数据量特点,提供了bitmap和int array两种结构存储倒排索引,达到一定阈值的时候会做相应转化。
而针对复杂类型数据(三种,json,full text,vector),还是通过倒排提供支持,只是针对不同类型做了不同的优化改动。
先说json,以往查询json数据的做法,是要先读取json然后解析再然后查询,这样效率很低。AnalyticDB采用空间换时间的思路,将json数据先解析,然后对每个列构建倒排索引(和单列倒排索引类似)。在查询的时候就可以直接根据索引快速定位到对应的json。
full-text的索引方式应该是和ElasticSearch类似的,即词到整个文档的倒排索引,查询时还会按TF/IDF评分将结果返回给用户(ES也是这样)。
第三种类型是vector类型数据,主要采用NNS(nearest neighbour search)方法来加速查询(看名字和KNN算法有点像),大意也是用类似计算临近数据的方式加速检索。
对于增量数据,由于数据是落盘到磁盘上才构建全量索引,索引增量数据和已经落盘的数据有检索性能的区别,所以需要对增量数据额外构建索引来弥补这种差距。而AnalyticDB对增量数据构建的是排序索引。所谓排序索引,本质上是一个数组,存储的是数据的id。具体原理比较难解释清楚,可以理解为就是存储排序后的数据的id。通过排序索引可以将全表检索的复杂度从O(n)降低到O(log n),也是一种空间换时间的思路了。
说完AnalyticDB,我们来对比下其他索引结构。Apache Kylin就不必多说了,基本就是依托于Hbase的row-key索引机制,算是比较弱的索引机制。
和AnalyticDB比较像是应该算是Druid,也是倒排索引,不过是bitmap结构存储的倒排索引,它的倒排索引是经过优化的,叫Roaring bitmap,可以规避存储小数据时候的存储空间问题。相比于AnalyticDB的大而全的索引,Druid可以说是小而美。只对维度数据存储bitmap索引,并且是和数据一起存储在文件中,而非AnalyticDB那样数据和索引分开存。出现这样的原因一个是场景上,Druid毕竟是面向OLAP查询的,索引它只需要对维度索引构建就行。这样的好处在于实现简单,存储也不会占用太多空间。而针对单一OLAP场景,其实这样也已经足够了。
小结
总而言之言而总之,AnalyticDB因为其是云原生,底层存储,资源调度等都是依托于阿里云的其他服务,所以它开源出来是不现实的(毕竟人家还靠这个赚钱),哪怕真的开源,使用者使用开源存储和资源调度方案估计也难以做到它在阿里云生态上那么好。
不过它的架构和一些特性还是很有借鉴意义的,比如读写分离,预先分区,还有行-列混合存储,强大的索引机制,索引机制如何跟底层的存储相互配合等,这些东西目前开源的一些系统可能还没有或没AnalyticDB那么完善。一方面可能是因为这些东西实现起来后,配置上会比较复杂,阿里云的东西不怕复杂,因为后端对用户是不可见的。要是开源系统搞得特别复杂,工程师们就不大会想用这些东西。毕竟为了一些可能用不着的性能提升,引入一个后续可能维护复杂的系统,是否值得也是需要权衡的。
总体上看,AnalyticDB还是走在了业界的前头的,好像也通过了TPC-DS的全流程测试,算是未来可期。未来开源数据库的方向会不会从分化走上AnalyticDB这种全面的道路呢?
以上~


