现代NLP的零样本学习
现代NLP的零样本学习
英文原文:Zero-Shot Learning in Modern NLP
无标注数据的文本分类的最优NLP模型
NLP(自然语言处理)是一个当前非常活跃的领域。近些年NLP领域的研究员已研究出一些从网上获得的大量未标注语料中学习知识的行之有效的方法。使用非监督模型进行迁移学习的成功使得我们可以超越几乎所有现有的对下游任务的监督学习达到的性能指标。随着持续研发出新的模型架构与非监督学习的目标,对于很多有大量标注数据的任务而言,“最优”的指标仍然在快速更新。
模型持续优化有一个益处,即我们发现这些模型对下游任务的大量标注预料的依赖正在缓慢降低。本周Open AI项目组发布了一个描述他们的当前最大模型的预印本,GPT-3,它有1750亿个参数。论文标题是“Language Models are Few-Shot Learners”,并展示了极大规模的语言模型在下游任务的性能可以与较小的模型相媲美,但需要的数据量却比它们少很多。

GPT-3 模型参数量与few-shot性能效果的关系图
然而,这么大的模型还是不适合在现实场景中使用的。比如,必须分配数十个GPU才能有足够的内存存储最大版本的GPT-3。在很多现实场景中,标注数据要么是很稀疏,要么完全得不到。而比GPT-3小很多的模型,如BERT,已经展示出具备以encode的方式把数据中的大量信息存入模型权重的能力(Petroni et al. 2019)。似乎如果我们有足够玄妙的技巧,就可以采用某种技术以充分利用潜在信息的方式把这些模型应用于下游任务,而不需要太多与具体任务相关的标注数据。
当然,在这一领域已经有一些研究了。在本文中,我将介绍一些使用最优NLP模型进行文本序列分类而不需要大量已标注训练语料的技术,这些技术既包括已发表的研究成果也有我们在Hugging Face的实验结果。
什么是零样本学习?
传统上讲,零样本学习常用于一个非常具体的任务:在一组标签集合上学习一个分类器,接着在一组分类器从未见过的标签上预测。最近,特别是在NLP领域,它的意思更多是指:构造一个模型,做它从未被显式针对该任务训练的任务。GPT-2 论文 中就有一个著名的例子:作者评估一个语言模型在下游任务(如机器翻译)上的性能,而不需要在这些任务上对这一模型进行fine tune。
这一定义并不总是那么重要,但是我们有必要意识到这一名词适用于很多种情况,因此当对比不同的方法时,我们应当充分分析进行相关实验时设置的条件。比如,传统的零样本学习要求对未知类别(比如一组可观察到的属性或仅仅是类名)提供某种描述符(Romera-Paredes et al. 2015),从而使得模型能够不需要这些类别的训练数据却能预测到它们。不同的零样本学习方法可能对于使用哪一种类别描述符采取不同的规则,意识到这一点就能为我们分析这些技术提供相关的上下文。
一种对潜在信息嵌入的方法
在计算机视觉领域的一种常见零样本学习方法是使用一个现有的特征提取器把一张图片与所有可能的类名都嵌入一种对应的潜在表示(比如 Socher et al. 2013)。然后选取一些训练集,并使用可用标签中的一部分子集学习一个线性投影,从而将图像与标签对齐。在测试的时候,这一框架可把任何一种标签以及任何一张图片嵌入同一个潜在变量的表示空间并测量它们的距离。
在文本领域有一个好处,就是我们几乎不需要一个单独的模型将数据和类名嵌入同一个空间,从而消避免了需要大量训练数据进行对齐的步骤。这并不是新出现的技术——研究员与从业者已经使用类似池化词向量的操作有相当长的时间了(比如Veeranna et al. 2016)。然而最近我们发现了句嵌入模型效果的显著提升。因此我们决定使用Sentence-BERT(一种最近出现的对池化的Bert序列表示进行fine-tune以增强语义丰富性的技术)作为一个获得序列及标签的嵌入表示的方法,来展开一些实验。
为了形式化的描述这一方法,假设我们有一个序列嵌入模型\Phi _{sent},以及一个可能的类名集合C。对任意一个序列x,我们使用下面的函数分类:
c\hat = \underset {c \in C} {\argmax} \cos (\Phi _{sent} (x),\Phi _{sent} (c))
其中\cos表示cosine相似度。下面一段代码显示如何使用Sentence-BERT作为我们的embedding 模型\Phi _{sent}:
# load the sentence-bert model from the HuggingFace model hub
!pip install transformers
from transformers import AutoTokenizer, AutoModel
from torch.nn import functional as F
tokenizer = AutoTokenizer.from_pretrained('deepset/sentence_bert')
model = AutoModel.from_pretrained('deepset/sentence_bert')
sentence = 'Who are you voting for in 2020?'
labels = ['business', 'art & culture', 'politics']
# run inputs through model and mean-pool over the sequence
# dimension to get sequence-level representations
inputs = tokenizer.batch_encode_plus([sentence] + labels,
return_tensors='pt',
pad_to_max_length=True)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
output = model(input_ids, attention_mask=attention_mask)[0]
sentence_rep = output[:1].mean(dim=1)
label_reps = output[1:].mean(dim=1)
# now find the labels with the highest cosine similarities to
# the sentence
similarities = F.cosine_similarity(sentence_rep, label_reps)
closest = similarities.argsort(descending=True)
for ind in closest:
print(f'label: {labels[ind]} \t similarity: {similarities[ind]}')
label: politics similarity: 0.21561521291732788 label: business similarity: 0.004524140153080225 label: art & culture similarity: -0.027396833524107933
注:这段代码使用deepset/sentence_bert,是最小版本的S-Bert模型。而我们的实验使用了更大的模型,模型地址在sentence-transformers GitHub repo,我们希望这一模型能尽快在Hugging Face的模型Hub中使用。
这一方法的一个问题是Sentence-BERT被设计成学习有效的句子级表示,而不是与我们的类名相似的单字或多字级表示。因此我们有理由推测我们对标签的嵌入方法在语义上可能不如常见的字级嵌入方法(比如word2vec)显著。从下图的t-SNE 可视化结果可以看出来,依据类名(颜色)对数据聚类的效果很好,但是标签与这些聚类结果的对齐效果很差。然而,如果我们使用词向量作为标签的表示,我们就需要标注语料以学习S-BERT的序列表示与word2vec的标签表示的对齐方式。
 对Yahoo Answers的S-BERT嵌入的t-SNE可视化结果。点表示数据和对应的标签的文本框。可以看出,虽然一些像”Computers & Internet”这样的标签出现在对应的数据的聚类结果的附近,大部分都没有对齐。
对Yahoo Answers的S-BERT嵌入的t-SNE可视化结果。点表示数据和对应的标签的文本框。可以看出,虽然一些像”Computers & Internet”这样的标签出现在对应的数据的聚类结果的附近,大部分都没有对齐。
在我们的一些内部实验中,我们使用下面的方法解决了这一问题:
- 从word2vec 模型的词典中提取前K个频率最大的单词V。
- 对V中的每一个词,获得对应的word2vec嵌入表示\Phi_{word}(V)。
- 对V中的每一个词,获得对应的S-BERT嵌入表示\Phi_{sent}(V)。
- 学习一个以最小均方误差加上L2范式为loss的从\Phi_{sent}(V)到\Phi_{word}(V)的线性投影矩阵Z
因为我们仅仅学习了词汇的嵌入表示的投影矩阵,我们不能期望它学习一个在基于S-BERT的序列表示和基于word2vec的标签嵌入表示之间的有效映射。相反,我们在分类任务中只使用Z来对序列和标签的S-BERT嵌入表示进行额外的转换。
c\hat = \underset {c \in C} {\argmax} \cos (\Phi _{sent} (x)Z,\Phi _{sent} (c)Z)
我们可以把这一操作看作为一种维度下降的方法。正如下图中的t-SNE可视化效果图所示,这一投影使得标签嵌入表示与对应的数据聚类结果更好的对齐,并且与池化的词向量方法相比,它保留了S-BERT的更为卓越的性能。重要的是,除了需要根据词频对word2vec词典进行排序以外,这一操作不需要任何额外数据。
在Yahoo Answers主题分类任务中,我们使用和使用这一投影操作而得到的F1分别为46.946.946.9和31.231.231.2。这里说明一下相关背景,Yahoo Answers有10个类别并且监督学习模型的准确率为75%左右。
 从SBERT到Wordvec的投影的嵌入表示的t-SNE可视化效果图。与上图相比,这一额外的投影操作使得标签出现在离对应的数据聚类结果更近的地方。
从SBERT到Wordvec的投影的嵌入表示的t-SNE可视化效果图。与上图相比,这一额外的投影操作使得标签出现在离对应的数据聚类结果更近的地方。
当有一些标注数据可用的时候
这一技术非常灵活,并且很容易扩展到有一部分有限的已标注数据(少样本学习)的情况,或者是我们仅标注了我们感兴趣的一部分子类数据(传统的零样本学习)。
为此,我们可以仅仅学习一个额外的从数据嵌入表示到任意一种标签的嵌入表示的以最小均方误差为损失函数的投影矩阵。然而有一点很重要,就是我们不能让模型对这些有限的数据产生过拟合。我们的嵌入模型本身性能很好,因此我们需要找到一种这些嵌入表示之间的投影,它既能从训练数据中学习,又能保留这些嵌入表示的丰富的语义。
为此,我们添加一个L2范式的变体,使得投影矩阵中的权重接近单位矩阵,而不是降低它们的范式。如果我们定义我们的训练数据和标签分别为X_{Tr},Y_{Tr},并且我们的嵌入函数为\Phi (x) = \Phi _{sent} (x)Z,那么我们的正则化后的目标函数就是:
W ^* = {\argmin} \lVert \Phi(X) ^T W – \Phi(Y) \rVert ^2 + \lambda \lVert W – \mathbb{I}_d \rVert ^2
这等价于一个带有高斯先验的贝叶斯线性回归,高斯先验的权重均值为单位矩阵,方差由\lambda约束。通过让W接近于单位矩阵,可以有效的将投影后的嵌入表示\Phi(X) W接近\Phi(X),这正是我们的目的。非形式化的说,我们有一个先验的信念,认为数据的最优表示就是我们的嵌入函数\Phi(X) \mathbb{I}_d = \Phi(X),并且仅仅当我们遇到更多训练数据的时候我们更新这一信念。
自然语言推理的分类任务
接下来我们将研究一些其他方法,不仅仅把序列和标签嵌入同一个潜在表示空间,而且能以out of the box(开箱即用)的方式告诉我们两个序列之间的关联性。
快速回顾一下,自然语言推理 (NLI) 考虑两个句子:一个是“前提”和一个是“假设”。该任务根据前提判断假设是真还是假(即前提是否蕴含假设)。
 来自于//nlpprogress.com/english/natural_language_inference.html的样例
来自于//nlpprogress.com/english/natural_language_inference.html的样例
当使用类似BERT的transformer架构,人们通常使用“句子对分类”的方法对NLI数据集建模。也就是说,我们把前提和假设(分别作为单独的segment)一起输入模型,输出一个分类结果的头部(译者注:即BERT最输出层的head),来预测类别是[矛盾, 中立, 蕴含]中的哪一种。
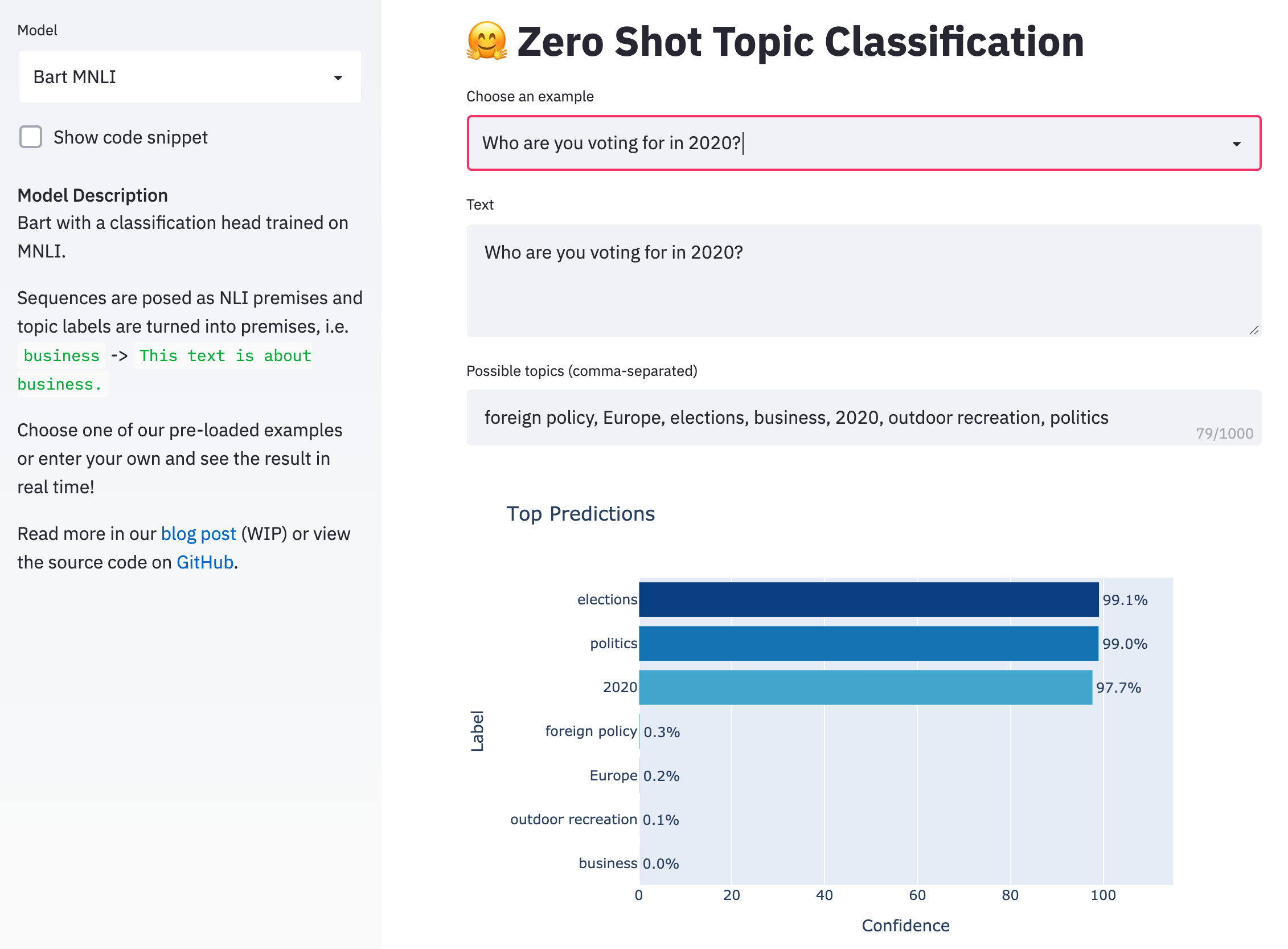
Yin et al. (2019)提出了一种方法,它使用在MNLI数据集上预训练的序列对分类器作为out-of-the-box(开箱即用)的零样本文本分类器,在实际场景中效果很好。它的思想是提取我们想要标注的序列作为“前提”,并把每一个可选标签转化成“假设”。如果这一自然语言推理模型预测到前提“蕴含”假设,就标注为真。下面一段代码展示了使用抱脸叔?的Transformers实现起来是多么容易。
# load model pretrained on MNLI
from transformers import BartForSequenceClassification, BartTokenizer
tokenizer = BartTokenizer.from_pretrained('bart-large-mnli')
model = BartForSequenceClassification.from_pretrained('bart-large-mnli')
# pose sequence as a NLI premise and label (politics) as a hypothesis
premise = 'Who are you voting for in 2020?'
hypothesis = 'This text is about politics.'
# run through model pre-trained on MNLI
input_ids = tokenizer.encode(premise, hypothesis, return_tensors='pt')
logits = model(input_ids)[0]
# we throw away "neutral" (dim 1) and take the probability of
# "entailment" (2) as the probability of the label being true
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
true_prob = probs[:,1].item() * 100
print(f'Probability that the label is true: {true_prob:0.2f}%')
Probability that the label is true: 99.04%
该论文中,作者使用最小版本的BERT,仅在Multi-genre NLI (MNLI)语料上fine-tune模型,在Yahoo Answers数据集上进行测试,以给标签加权重的方式计算出F1值为37.937.937.9。我们仅仅使用更大更新的Bart模型在MNLI数据集上预训练,就将这一数值提升至53.753.753.7。
在我们的在线demo上自己尝试一下!输入你想要分类的一个序列和感兴趣的任何一组标签,来观察Bart的实时效果。
当有一些标注数据可用的时候
使用这一模型在少量的标注数据上fine-tue并没有效果,因此它不太适用于少样本场景。然而,在传统零样本场景中,对一组有限的类别有足够多的数据,这一模型的效果就很显著。我们可以分两次输入序列以训练模型:一次使用正确的标签,一次使用随机选择的错误标签,并最优化交叉熵。
Fine-tuning的结果有一个问题,就是模型对看到过的标签的预测概率要比没有看到的高。为了减轻这一问题,作者提出了一种在测试阶段给在训练阶段看到过的标签添加惩罚的方法。这篇论文里有完整的细节。
在这里点击我们的demo来尝试一个在Yahoo Answers数据集上fine-tune的模型。你也可以找到作者的 GitHub repo here。
把分类当作一个完形填空任务
一个值得关注的正在进行中的方法是来自于Pattern-Exploiting Training (PET)的预印本论文Schick et al. (2020)。该论文的作者把文本分类任务重新形式化表示为一个完形填空任务。一个完形填空的问题分析一个部分被遮盖的序列,从上下文中预测那些缺失的部分。PET需要人工构造几个与任务相关的完形填空形式的模板,比如对于主题分类,可以看到类似下面的文字:
 用于主题分类的完形填空模板的样例。a和b表示Yahoo Answers数据集中的问题和答案,____ 是模型需要预测的类名。
用于主题分类的完形填空模板的样例。a和b表示Yahoo Answers数据集中的问题和答案,____ 是模型需要预测的类名。
该方法使用一个预训练的masked语言模型,对每一个完形填空语句,从可能的类名中选择被遮挡(空白)部分最可能出现的一个。
该方法的输出结果是一组对每个数据点的带噪声的预测值。这一过程本身是被当做一个基础零样本分类器使用的。另外,作者也介绍了一种知识蒸馏的方法。从完形填空任务生成一组预测后,这些预测的值被当做代理类,用于重新训练一个新的分类器。我的直觉是这一步骤是有效的,因为它使得我们可以在整个测试集上推理,从而使得模型可以从它所预测的全部数据上学习,而不是对每一个数据单独处理。我猜测当预测数据所属领域与MLM (译者注:Masked Language Model)模型的训练语料不一致时,这一步骤会特别有效。
在该论文的最新版本中,作者也讨论了一种在PET基础上迭代式的自学习机制,并称在Yahoo Answers数据集上达到了引人注目的70.7%的准确率,这一准确率几乎达到了最优监督学习分类方法的性能。
这让我想起我在早些时候指出的一些在比较不同方法时需要考虑实验参数的观点。虽然PET效果显著高于本文描述的其他方法,但是PET使用了其他方法未假设的可用数据:多个任务相关的,人工生成的完形填空语句以及用于知识蒸馏/自学习的大量未标注数据。我并不是批评PET的意思,而仅仅是为了强调在对比在某种程度上都可被认为是“零样本”的不同方法时,需要谨慎分析的重要性。
当有一些标注数据可用的时候
作者展示了一种当有一些训练数据可用的情况下使用PET的比较成熟的方法,该方法可以有效的最小化任意可用训练数据的完形填空预测损失和标准MLM损失之和。细节有些复杂,因此如果你感兴趣的话,我强烈建议看一下 预印版论文, YouTube tutorial,或者 GitHub repo。
低资源语言
NLP中一个及其重要的数据稀疏场景是低资源语言。幸运的是,这是一个非常活跃的研究领域,有很多文章涉及到它。如果你感兴趣的话,我强烈建议看一下Graham Neubig最近发表的Low Resource NLP Bootcamp。这是一个有趣的资源,它是以GitHub repo的形式展示的,包含8节课(加上练习),主要讲解数据稀疏的语言的NLP方法。除此之外,我强烈建议看一下Sebastian Ruder的文章,包括“A survey of cross-lingual word embedding models”。


