应用角度看kafka的术语和功能
- 2019 年 10 月 10 日
- 筆記
kafka的术语(Terminology)
Topic 和Consumer Group
Topic 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)
对应用来说,生产者要发布消息,必须指定一个主题topic。以确定发到哪里了。
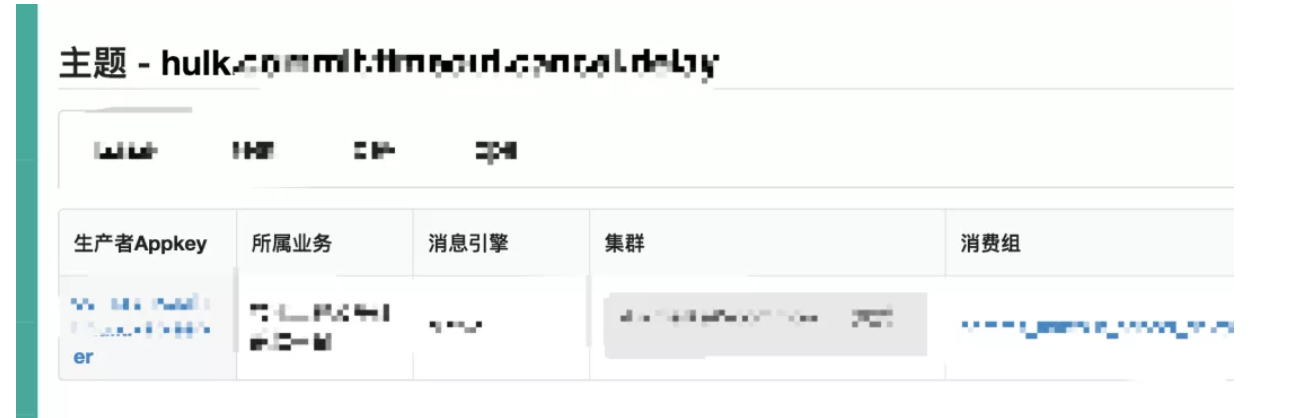
Consumer Group 消费组,每个Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
这个概念是和Topic对应的。
一个topic可以有多个消费组进行消费。
一般一个服务创建一个消费组。
如下图
上面两个的使用可以用下图来表示:

Producer和Consumer
Producer 负责发布消息到 Kafka broker
从应用上来说,就是写代码的时候用工厂模式简历生产者,基本上保证一个服务就是一个生产者往队列里发送数据。
一般来说,一台服务器会起一个生产者。但是也不一定,某个大神写个死循环建立一堆生产者直到内存溢出也是可以实现的。
Consumer 消息消费者,向 Kafka broker 读取消息的客户端。
和生产者相对应,一台服务器会起一个消费者。同理,写个死循环建立一堆消费者直到内存溢出也是可以实现的。

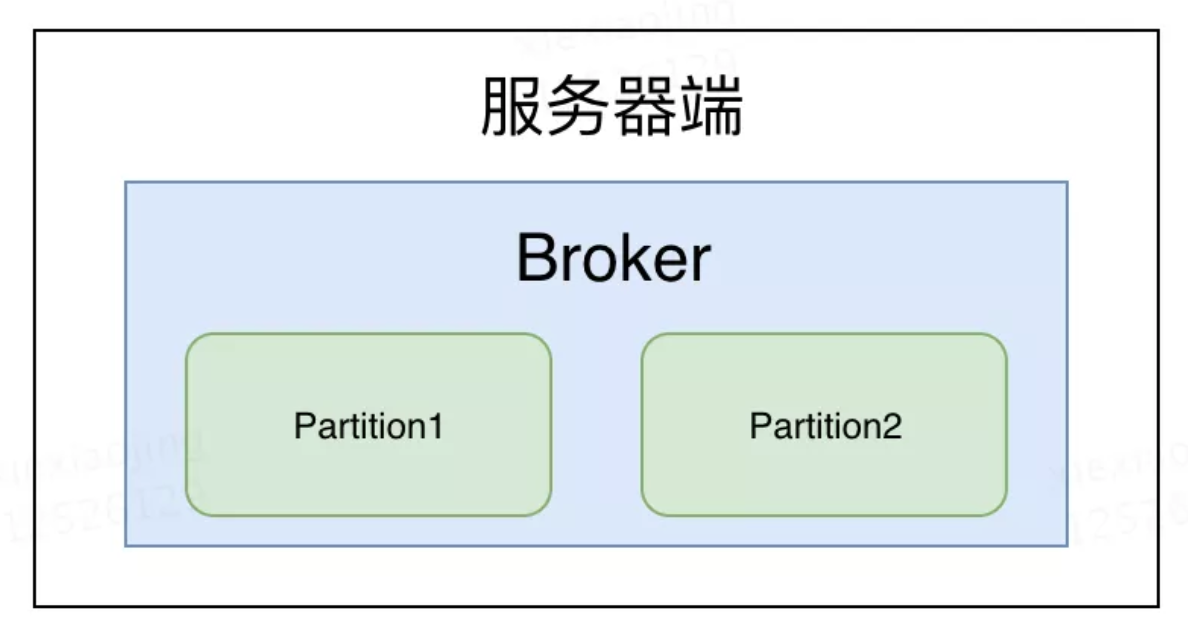
Partition和Broker
Partition 物理上的概念,每个 Topic 包含一个或多个 Partition。这种服务就是这么设计,数据太大了,就分成小片。所有的小片合起来完成一个功能,这里完成一个topic。
Broker 集群包含一个或多个服务器,这种服务器被称为 broker。
对应用来说,生产者把消费发出去了,就不管了。消费者慢条斯理的按照自己的速率来消费。这段时间可能有大量消息产生,消费者压力还是在一定范围内。做生产者和消费者之间解耦的就是一个缓存服务broker。
以上用一张图表示如下:
应用场景
基本应用
-
用于解耦生产端和消费端。比如两个团队需要共享相同的数据,但是数据只能由一方来存储。另一方需要的数据可以通过作为消息的一个消费者进行消息消费。
-
用于增加并发度。一个http调用内部逻辑复杂。可以将这个调用分为两阶段处理。第一阶段校验调用的合法性。将校验结果和查询号返回客户端。这个阶段处理简单,可以支撑很高的并发度。如果校验合法发送消息进行执行阶段处理。因为MQ消息消费速率相对恒定,不会压垮服务。客户端可以通过单号查询结果。
高级应用
死信
消息队列里的消息如果设定延时消费,则这条消息就会阻塞后面正常的消息直到这条消息被消费。解决办法是使用另外的队列来存放这些会阻塞的消息。这就是死信队列。
