基于 abp vNext 和 .NET Core 开发博客项目 – 定时任务最佳实战(二)
- 2020 年 5 月 30 日
- 筆記
- .NET Core, abp vnext, HtmlAgilityPack, xpath
上一篇(//www.cnblogs.com/meowv/p/12971041.html)使用HtmlAgilityPack抓取壁纸数据成功将图片存入数据库,本篇继续来完成一个全网各大平台的热点新闻数据的抓取。
同样的,可以先预览一下我个人博客中的成品://meowv.com/hot 😝😝😝,和抓取壁纸的套路一样,大同小异。

本次要抓取的源有18个,分别是博客园、V2EX、SegmentFault、掘金、微信热门、豆瓣精选、IT之家、36氪、百度贴吧、百度热搜、微博热搜、知乎热榜、知乎日报、网易新闻、GitHub、抖音热点、抖音视频、抖音正能量。
还是将数据存入数据库,按部就班先将实体类和自定义仓储创建好,实体取名HotNews。贴一下代码:
//HotNews.cs
using System;
using Volo.Abp.Domain.Entities;
namespace Meowv.Blog.Domain.HotNews
{
public class HotNews : Entity<Guid>
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
/// <summary>
/// SourceId
/// </summary>
public int SourceId { get; set; }
/// <summary>
/// 创建时间
/// </summary>
public DateTime CreateTime { get; set; }
}
}
剩下的大家自己完成,最终数据库生成一张空的数据表,meowv_hotnews 。
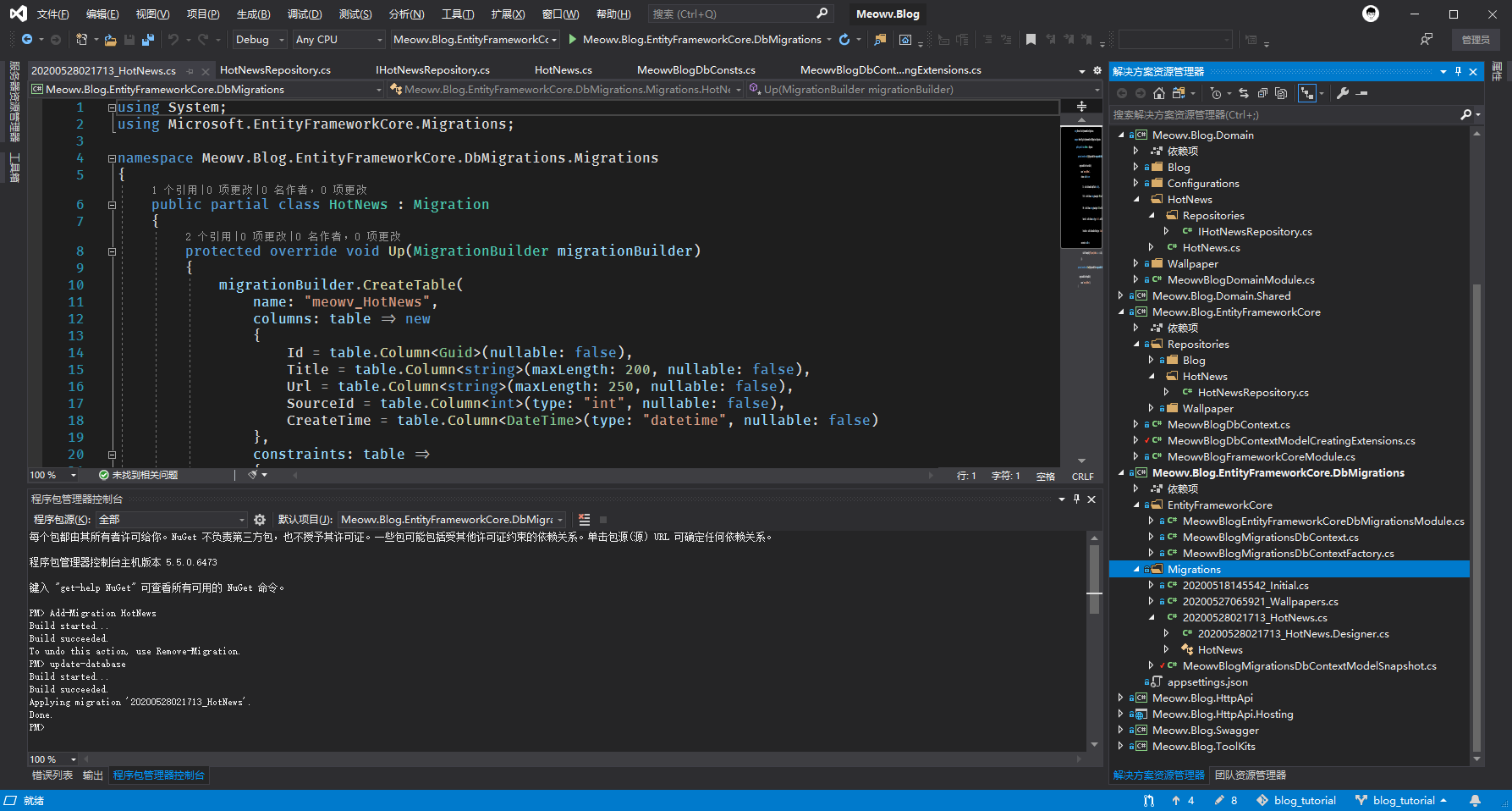
然后还是将我们各大平台放到一个枚举类HotNewsEnum.cs中。
//HotNewsEnum.cs
using System.ComponentModel;
namespace Meowv.Blog.Domain.Shared.Enum
{
public enum HotNewsEnum
{
[Description("博客园")]
cnblogs = 1,
[Description("V2EX")]
v2ex = 2,
[Description("SegmentFault")]
segmentfault = 3,
[Description("掘金")]
juejin = 4,
[Description("微信热门")]
weixin = 5,
[Description("豆瓣精选")]
douban = 6,
[Description("IT之家")]
ithome = 7,
[Description("36氪")]
kr36 = 8,
[Description("百度贴吧")]
tieba = 9,
[Description("百度热搜")]
baidu = 10,
[Description("微博热搜")]
weibo = 11,
[Description("知乎热榜")]
zhihu = 12,
[Description("知乎日报")]
zhihudaily = 13,
[Description("网易新闻")]
news163 = 14,
[Description("GitHub")]
github = 15,
[Description("抖音热点")]
douyin_hot = 16,
[Description("抖音视频")]
douyin_video = 17,
[Description("抖音正能量")]
douyin_positive = 18
}
}
和上一篇抓取壁纸一样,做一些准备工作。
在.Application.Contracts层添加HotNewsJobItem<T>,在.BackgroundJobs层添加HotNewsJob用来处理爬虫逻辑,用构造函数方式注入仓储IHotNewsRepository。
//HotNewsJobItem.cs
using Meowv.Blog.Domain.Shared.Enum;
namespace Meowv.Blog.Application.Contracts.HotNews
{
public class HotNewsJobItem<T>
{
/// <summary>
/// <see cref="Result"/>
/// </summary>
public T Result { get; set; }
/// <summary>
/// 来源
/// </summary>
public HotNewsEnum Source { get; set; }
}
}
//HotNewsJob.CS
using Meowv.Blog.Domain.HotNews.Repositories;
using System;
using System.Net.Http;
using System.Threading.Tasks;
namespace Meowv.Blog.BackgroundJobs.Jobs.HotNews
{
public class HotNewsJob : IBackgroundJob
{
private readonly IHttpClientFactory _httpClient;
private readonly IHotNewsRepository _hotNewsRepository;
public HotNewsJob(IHttpClientFactory httpClient,
IHotNewsRepository hotNewsRepository)
{
_httpClient = httpClient;
_hotNewsRepository = hotNewsRepository;
}
public async Task ExecuteAsync()
{
throw new NotImplementedException();
}
}
}
接下来明确数据源地址,因为以上数据源有的返回是HTML,有的直接返回JSON数据。为了方便调用,我这里还注入了IHttpClientFactory。
整理好的待抓取数据源列表是这样的。
...
var hotnewsUrls = new List<HotNewsJobItem<string>>
{
new HotNewsJobItem<string> { Result = "//www.cnblogs.com", Source = HotNewsEnum.cnblogs },
new HotNewsJobItem<string> { Result = "//www.v2ex.com/?tab=hot", Source = HotNewsEnum.v2ex },
new HotNewsJobItem<string> { Result = "//segmentfault.com/hottest", Source = HotNewsEnum.segmentfault },
new HotNewsJobItem<string> { Result = "//web-api.juejin.im/query", Source = HotNewsEnum.juejin },
new HotNewsJobItem<string> { Result = "//weixin.sogou.com", Source = HotNewsEnum.weixin },
new HotNewsJobItem<string> { Result = "//www.douban.com/group/explore", Source = HotNewsEnum.douban },
new HotNewsJobItem<string> { Result = "//www.ithome.com", Source = HotNewsEnum.ithome },
new HotNewsJobItem<string> { Result = "//36kr.com/newsflashes", Source = HotNewsEnum.kr36 },
new HotNewsJobItem<string> { Result = "//tieba.baidu.com/hottopic/browse/topicList", Source = HotNewsEnum.tieba },
new HotNewsJobItem<string> { Result = "//top.baidu.com/buzz?b=341", Source = HotNewsEnum.baidu },
new HotNewsJobItem<string> { Result = "//s.weibo.com/top/summary/summary", Source = HotNewsEnum.weibo },
new HotNewsJobItem<string> { Result = "//www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true", Source = HotNewsEnum.zhihu },
new HotNewsJobItem<string> { Result = "//daily.zhihu.com", Source = HotNewsEnum.zhihudaily },
new HotNewsJobItem<string> { Result = "//news.163.com/special/0001386F/rank_whole.html", Source = HotNewsEnum.news163 },
new HotNewsJobItem<string> { Result = "//github.com/trending", Source = HotNewsEnum.github },
new HotNewsJobItem<string> { Result = "//www.iesdouyin.com/web/api/v2/hotsearch/billboard/word", Source = HotNewsEnum.douyin_hot },
new HotNewsJobItem<string> { Result = "//www.iesdouyin.com/web/api/v2/hotsearch/billboard/aweme", Source = HotNewsEnum.douyin_video },
new HotNewsJobItem<string> { Result = "//www.iesdouyin.com/web/api/v2/hotsearch/billboard/aweme/?type=positive", Source = HotNewsEnum.douyin_positive },
};
...
其中有几个比较特殊的,掘金、百度热搜、网易新闻。
掘金需要发送Post请求,返回的是JSON数据,并且需要指定特有的请求头和请求数据,所有使用IHttpClientFactory创建了HttpClient对象。
百度热搜、网易新闻两个老大哥玩套路,网页编码是GB2312的,所以要专门为其指定编码方式,不然取到的数据都是乱码。
...
var web = new HtmlWeb();
var list_task = new List<Task<HotNewsJobItem<object>>>();
hotnewsUrls.ForEach(item =>
{
var task = Task.Run(async () =>
{
var obj = new object();
if (item.Source == HotNewsEnum.juejin)
{
using var client = _httpClient.CreateClient();
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36 Edg/83.0.478.13");
client.DefaultRequestHeaders.Add("X-Agent", "Juejin/Web");
var data = "{\"extensions\":{\"query\":{ \"id\":\"21207e9ddb1de777adeaca7a2fb38030\"}},\"operationName\":\"\",\"query\":\"\",\"variables\":{ \"first\":20,\"after\":\"\",\"order\":\"THREE_DAYS_HOTTEST\"}}";
var buffer = data.SerializeUtf8();
var byteContent = new ByteArrayContent(buffer);
byteContent.Headers.ContentType = new MediaTypeHeaderValue("application/json");
var httpResponse = await client.PostAsync(item.Result, byteContent);
obj = await httpResponse.Content.ReadAsStringAsync();
}
else
{
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
obj = await web.LoadFromWebAsync(item.Result, (item.Source == HotNewsEnum.baidu || item.Source == HotNewsEnum.news163) ? Encoding.GetEncoding("GB2312") : Encoding.UTF8);
}
return new HotNewsJobItem<object>
{
Result = obj,
Source = item.Source
};
});
list_task.Add(task);
});
Task.WaitAll(list_task.ToArray());
循环 hotnewsUrls ,可以看到HotNewsJobItem我们返回的是object类型,因为有JSON又有HtmlDocument对象。所以这里为了能够统一接收,就是用了object。
针对掘金做了单独处理,使用HttpClient发送Post请求,返回JSON字符串数据。
针对百度热搜和网易新闻,使用Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);注册编码提供程序,然后在web.LoadFromWebAsync(...)加载网页数据的时候指定网页编码,我使用了一个三元表达式来处理。
完成上面这一步,就可以循环 list_task,使用XPath语法,或者解析JSON数据,去拿到数据了。
...
var hotNews = new List<HotNews>();
foreach (var list in list_task)
{
var item = await list;
var sourceId = (int)item.Source;
...
if (hotNews.Any())
{
await _hotNewsRepository.DeleteAsync(x => true);
await _hotNewsRepository.BulkInsertAsync(hotNews);
}
}
这个爬虫同样很简单,只要拿到标题和链接即可,所以主要目标是寻找到页面上的a标签列表。这个我觉得也没必要一个个去分析了,直接上代码。
// 博客园
if (item.Source == HotNewsEnum.cnblogs)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='post_item_body']/h3/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// V2EX
if (item.Source == HotNewsEnum.v2ex)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//span[@class='item_title']/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = $"//www.v2ex.com{x.GetAttributeValue("href", "")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// SegmentFault
if (item.Source == HotNewsEnum.segmentfault)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='news__item-info clearfix']/a").Where(x => x.InnerText.IsNotNullOrEmpty()).ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.SelectSingleNode(".//h4").InnerText,
Url = $"//segmentfault.com{x.GetAttributeValue("href", "")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 掘金
if (item.Source == HotNewsEnum.juejin)
{
var obj = JObject.Parse((string)item.Result);
var nodes = obj["data"]["articleFeed"]["items"]["edges"];
foreach (var node in nodes)
{
hotNews.Add(new HotNews
{
Title = node["node"]["title"].ToString(),
Url = node["node"]["originalUrl"].ToString(),
SourceId = sourceId,
CreateTime = DateTime.Now
});
}
}
// 微信热门
if (item.Source == HotNewsEnum.weixin)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//ul[@class='news-list']/li/div[@class='txt-box']/h3/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 豆瓣精选
if (item.Source == HotNewsEnum.douban)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='channel-item']/div[@class='bd']/h3/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// IT之家
if (item.Source == HotNewsEnum.ithome)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='lst lst-2 hot-list']/div[1]/ul/li/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 36氪
if (item.Source == HotNewsEnum.kr36)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='hotlist-main']/div[@class='hotlist-item-toptwo']/a[2]|//div[@class='hotlist-main']/div[@class='hotlist-item-other clearfloat']/div[@class='hotlist-item-other-info']/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = $"//36kr.com{x.GetAttributeValue("href", "")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 百度贴吧
if (item.Source == HotNewsEnum.tieba)
{
var obj = JObject.Parse(((HtmlDocument)item.Result).ParsedText);
var nodes = obj["data"]["bang_topic"]["topic_list"];
foreach (var node in nodes)
{
hotNews.Add(new HotNews
{
Title = node["topic_name"].ToString(),
Url = node["topic_url"].ToString().Replace("amp;", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
}
}
// 百度热搜
if (item.Source == HotNewsEnum.baidu)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//table[@class='list-table']//tr/td[@class='keyword']/a[@class='list-title']").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 微博热搜
if (item.Source == HotNewsEnum.weibo)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//table/tbody/tr/td[2]/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = $"//s.weibo.com{x.GetAttributeValue("href", "").Replace("#", "%23")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 知乎热榜
if (item.Source == HotNewsEnum.zhihu)
{
var obj = JObject.Parse(((HtmlDocument)item.Result).ParsedText);
var nodes = obj["data"];
foreach (var node in nodes)
{
hotNews.Add(new HotNews
{
Title = node["target"]["title"].ToString(),
Url = $"//www.zhihu.com/question/{node["target"]["id"]}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
}
}
// 知乎日报
if (item.Source == HotNewsEnum.zhihudaily)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='box']/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = $"//daily.zhihu.com{x.GetAttributeValue("href", "")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 网易新闻
if (item.Source == HotNewsEnum.news163)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//div[@class='area-half left']/div[@class='tabBox']/div[@class='tabContents active']/table//tr/td[1]/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText,
Url = x.GetAttributeValue("href", ""),
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// GitHub
if (item.Source == HotNewsEnum.github)
{
var nodes = ((HtmlDocument)item.Result).DocumentNode.SelectNodes("//article[@class='Box-row']/h1/a").ToList();
nodes.ForEach(x =>
{
hotNews.Add(new HotNews
{
Title = x.InnerText.Trim().Replace("\n", "").Replace(" ", ""),
Url = $"//github.com{x.GetAttributeValue("href", "")}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
});
}
// 抖音热点
if (item.Source == HotNewsEnum.douyin_hot)
{
var obj = JObject.Parse(((HtmlDocument)item.Result).ParsedText);
var nodes = obj["word_list"];
foreach (var node in nodes)
{
hotNews.Add(new HotNews
{
Title = node["word"].ToString(),
Url = $"#{node["hot_value"]}",
SourceId = sourceId,
CreateTime = DateTime.Now
});
}
}
// 抖音视频 & 抖音正能量
if (item.Source == HotNewsEnum.douyin_video || item.Source == HotNewsEnum.douyin_positive)
{
var obj = JObject.Parse(((HtmlDocument)item.Result).ParsedText);
var nodes = obj["aweme_list"];
foreach (var node in nodes)
{
hotNews.Add(new HotNews
{
Title = node["aweme_info"]["desc"].ToString(),
Url = node["aweme_info"]["share_url"].ToString(),
SourceId = sourceId,
CreateTime = DateTime.Now
});
}
}
将item.Result转换成指定类型,最终拿到数据后,我们先删除所有数据后再批量插入。
然后新建扩展方法UseHotNewsJob(),在模块类中调用。
//MeowvBlogBackgroundJobsExtensions.cs
...
/// <summary>
/// 每日热点数据抓取
/// </summary>
/// <param name="context"></param>
public static void UseHotNewsJob(this IServiceProvider service)
{
var job = service.GetService<HotNewsJob>();
RecurringJob.AddOrUpdate("每日热点数据抓取", () => job.ExecuteAsync(), CronType.Hour(1, 2));
}
...
指定定时任务为每2小时运行一次。
...
public override void OnApplicationInitialization(ApplicationInitializationContext context)
{
...
var service = context.ServiceProvider;
...
service.UseHotNewsJob();
}
编译运行,此时周期性作业就会出现我们的定时任务了。
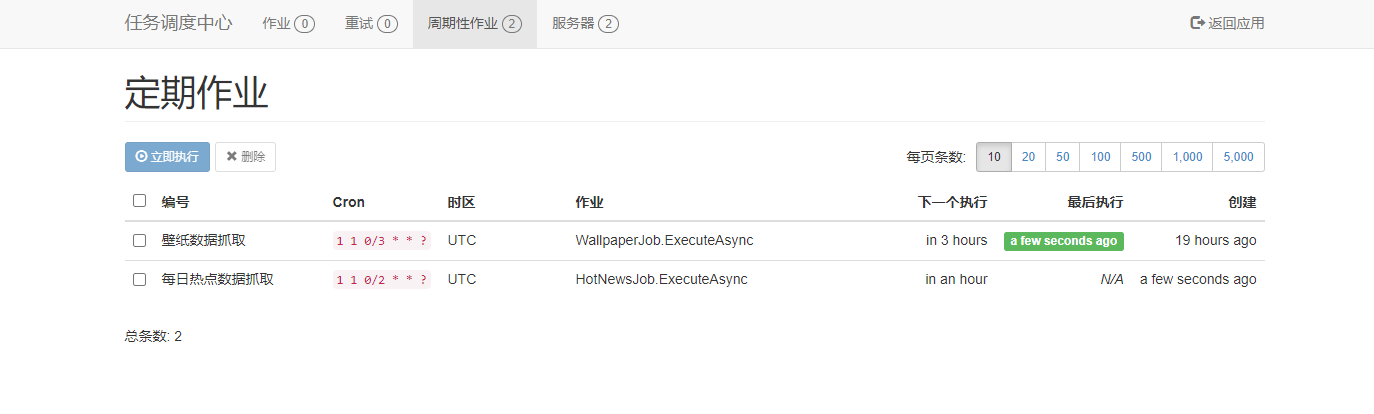
默认时间没到是不会执行的,我们手动执行等待一会看看效果。
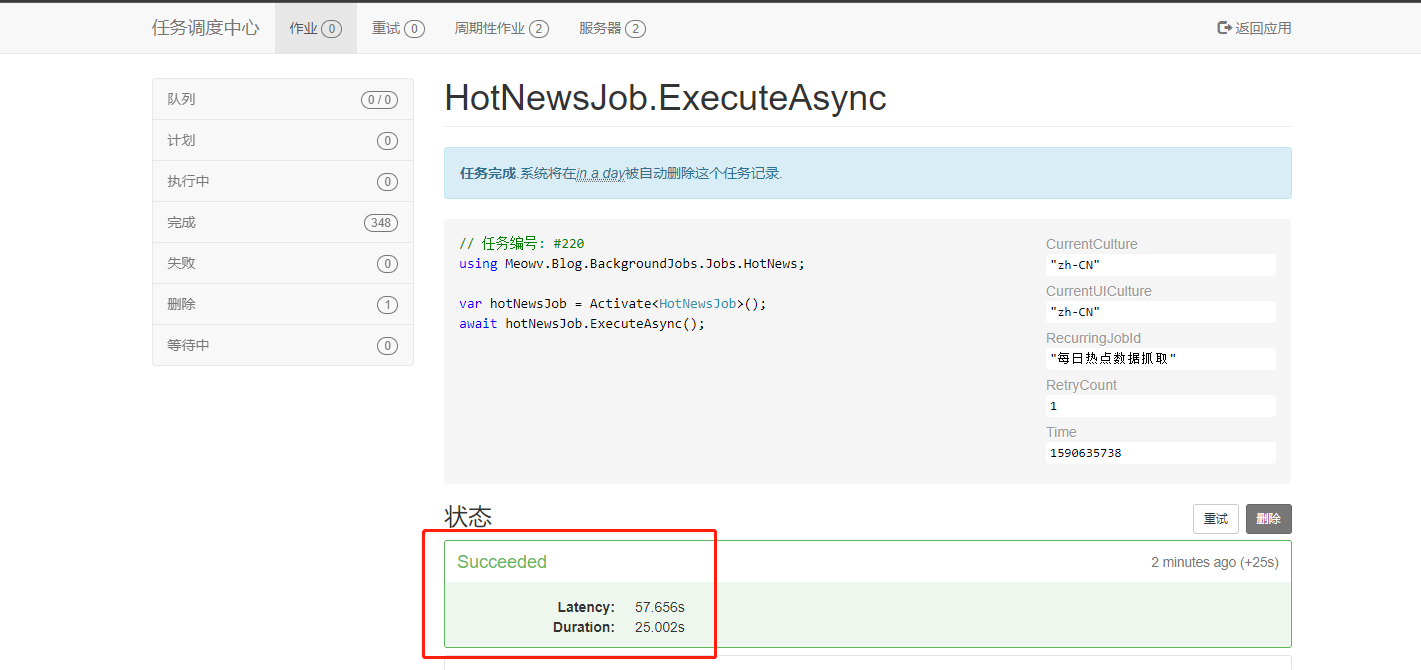
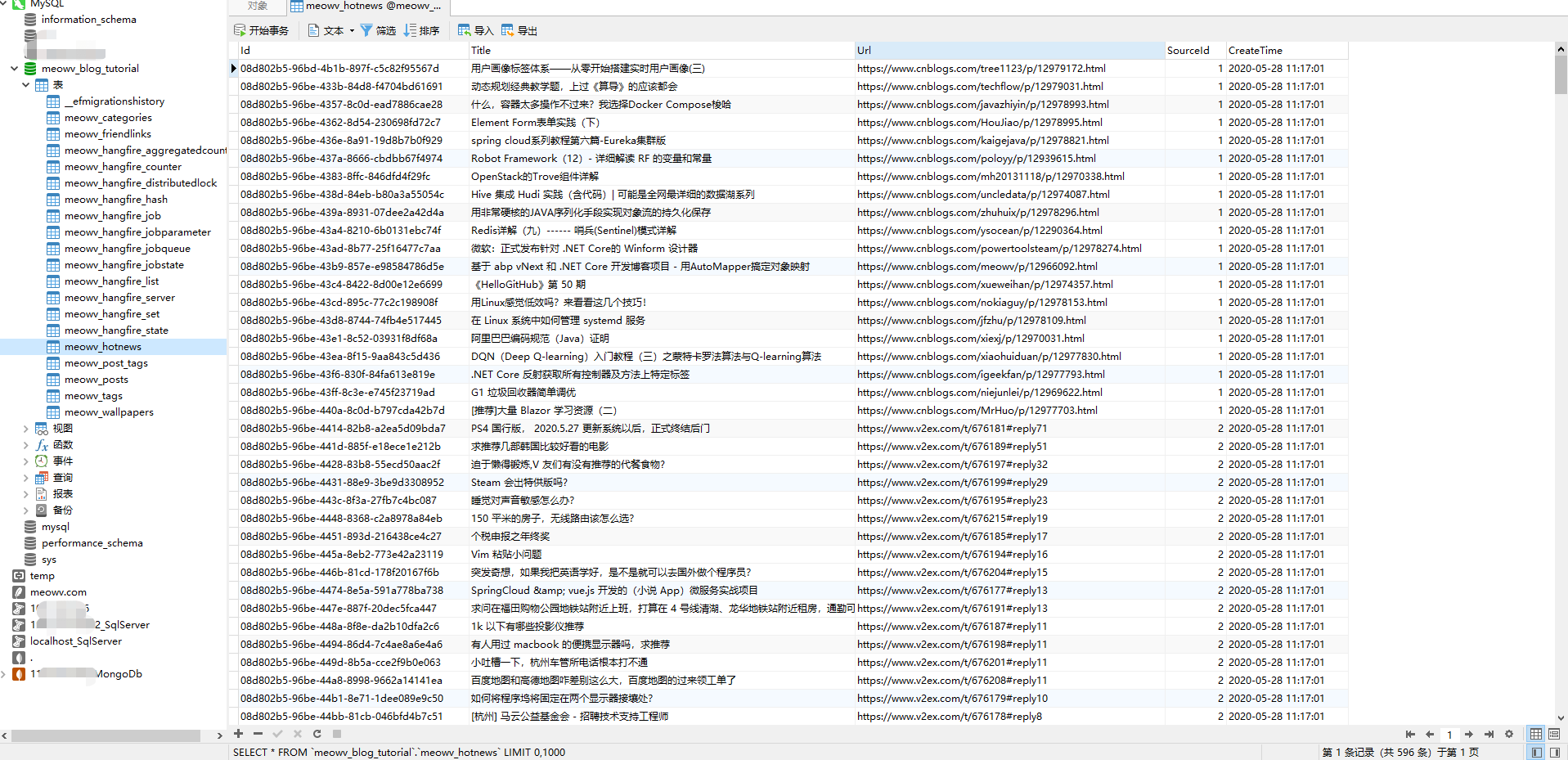
执行完成后,成功将所有热点数据保存在数据库中,说明我们的爬虫已经搞定了,并且Hangfire会按照给定的规则去循环执行,你学会了吗?😁😁😁
开源地址://github.com/Meowv/Blog/tree/blog_tutorial

