MASA DCN(可变形卷积) 算法笔记
1. 前言
Deformable Convlolutional Networks 是 ICCV 2017 一篇用在检测任务上的论文,它的出发点是在图像任务中目标的尺寸,形状变化不一,虽然目前(指代论文发表以前)的 CNN 对这些变化有一定的鲁棒性,但并不太够。因此论文以此为切入点,通过在卷积层中插入 offset(可变形卷积)和在 ROI Pooling 层中插入 offset(可变形 ROI Pooling)来增强网络的特征提取能力。这个 offset 的作用是使网络在提取特征时更多的把注意力聚焦到和训练目标有关的位置上,可以更好的覆盖不同尺寸和形状的目标,并且 offset 也是在监督信息的指导下进行学习的,因此不用像数据增强一样需要大量先验知识才可以获得更好的效果,整体结构也保持了 end2end。
2. 算法原理
2.1 可变形卷积示意图
下面的 Figure2 展示了可变形卷积的示意图:

可以看到可变形卷积的结构可以分为上下两个部分,上面那部分是基于输入的特征图生成 offset,而下面那部分是基于特征图和 offset 通过可变形卷积获得输出特征图。
假设输入的特征图宽高分别为w,h,下面那部分的卷积核尺寸是k_h和k_w,那么上面那部分卷积层的卷积核数量应该是2\times k_h\times k_w,其中2代表x,y两个方向的 offset。
并且,这里输出特征图的维度和输入特征图的维度一样,那么 offset 的维度就是[batch, 2\times k_h\times k_w, h, w],假设下面那部分设置了group参数(代码实现中默认为4),那么第一部分的卷积核数量就是2\times kh \times kw \times group,即每一个group共用一套 offset。下面的可变形卷积可以看作先基于上面那部分生成的 offset 做了一个插值操作,然后再执行普通的卷积。
2.2 普通卷积和可变形卷积的差异
下面的 Figure5 形象的展示了普通的卷积和可变形卷积的差异:
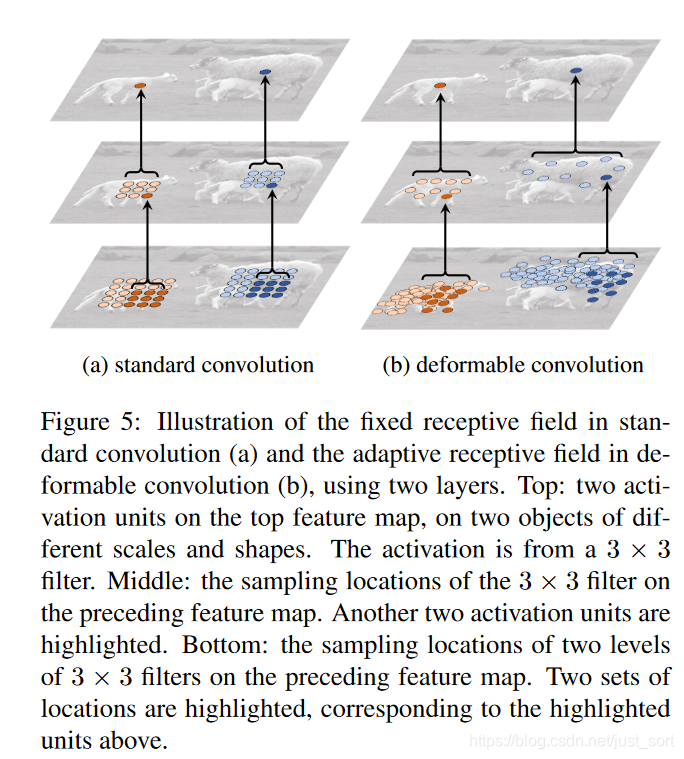
图中以两个3\times 3卷积为例,可以看到对于普通卷积来说,卷积操作的位置都是固定的。而可变形卷积因为引入了 offset,所以卷积操作的位置会在监督信息的指导下进行选择,可以较好的适应目标的各种尺寸,形状,因此提取的特征更加丰富并更能集中到目标本身。
2.3 可变形卷积的可视化效果
下面的 Fiugure6 展示了可变形卷积的可视化效果。

可以看到每张图像中都有红色和绿色的点,并且绿色点只有一个,这个点表示的是conv5输出特征图上的一个位置,往前3个卷积层理论上可以得到9^3=729个红点,也即是卷积计算的区域,但是这729个点中有一些是越界的,所以图中显示的点会少于729个。
可以看到当绿色点在目标上时,红色点所在区域也集中在目标位置,并且基本能够覆盖不同尺寸的目标,因此可变形卷积可以提取更有效的特征。
而当绿色点在背景上时,红色点所在的区域比较发散,这应该是不断向外寻找并确认该区域是否为背景区域的过程。
2.4 可变形 ROI Pooling
下面的 Figure3 展示了可变形 ROI Pooling 的示意图:

整体上仍然可以分成上下两部分,上面那部分是基于输入特征图生成 offset,下面的部分是基于输入特征图和 offset 通过可变形 RoI Pooling 生成输出 RoI 特征图。
上面部分先通过常规的 ROI Pooling 获得 ROI 特征图,这里假设每个 RoI 划分成k\times k个 bin,Figure3 中是划分成3\times 3个 bin,然后通过一个输出节点数为k\times k\times 2的全连接层获得 offset 信息,最后再 reshape 成维度为[batch, 2, k, k]的 offset。
下面部分仍然先基于 offset 进行插值操作,然后再执行普通的 ROI Pooling,这样就完成了可变形 ROI Pooling。可以看出可变形 ROI Pooling 相对于普通 ROI Pooling 来说,ROI 中的每个 bin 的位置都是根据监督信息来学习的,而不是固定划分的。
2.5 可变形 PSROI Pooling
下面的 Figure4 展示了可变形 PSROI Pooling 的示意图:

PSROI Pooling 是 R-FCN 中提出来,文章见目标检测算法之NIPS 2016 R-FCN(来自微软何凯明团队) 。这里仍然分成上下两部分。
上面那部分先通过卷积核数量为2\times k\times k\times (C+1)的卷积层获得输出特征图,其中k\times k表示 bin 的数量,C表示目标类别数,1表示背景,然后基于该特征图通过 PS RoI pooling 操作得到输出维度为[batch, 2\times(C+1), k, k]的 offset。
下面那部分先通过卷积核数量为k\times k\times (C+1)的卷积层获得输出特征图,这是 R-FCN 中的操作,然后基于该特征图和第一部分输出的 offset 执行可变形 PSROI Pooling 操作。可变形 PSROI Pooling 也可以看做是先插值再进行 PS ROIPooling 操作。
Figure7 展示了可变形 PSROI Pooling 在实际图像上的效果,每张图中都有一个 ROI 框(黄色框)和3\times 3个 bin(红色框),在普通的 PSROI Pooling 中这9个 bin 的位置应该是均匀划分的,但在可变形 PSROI Pooling 中这些区域是集中在目标区域的,这说明可变形结构可以让网络的注意力更集中于目标区域。

2.6 代码实现细节
在代码实现时,主网络使用了 ResNet101,但是原本stride=32的res5部分修改为stride=16,同时可变形卷积也只在res5部分的3\times 3卷积添加,另外为了弥补修改stride带来的感受野减小,在res5的可变形卷积部分将dilate参数设置为 2。
本来想在这里贴代码理解的,但介于篇幅原因,我就后面的推文再介绍一下 Pytorch 代码理解和实现吧。(逃)
3. 实验结果
下面的 Table1 是 PASCAL VOC 上的实验结果,包含在多种图像任务和网络的不同阶段添加可变形卷积层的差异。
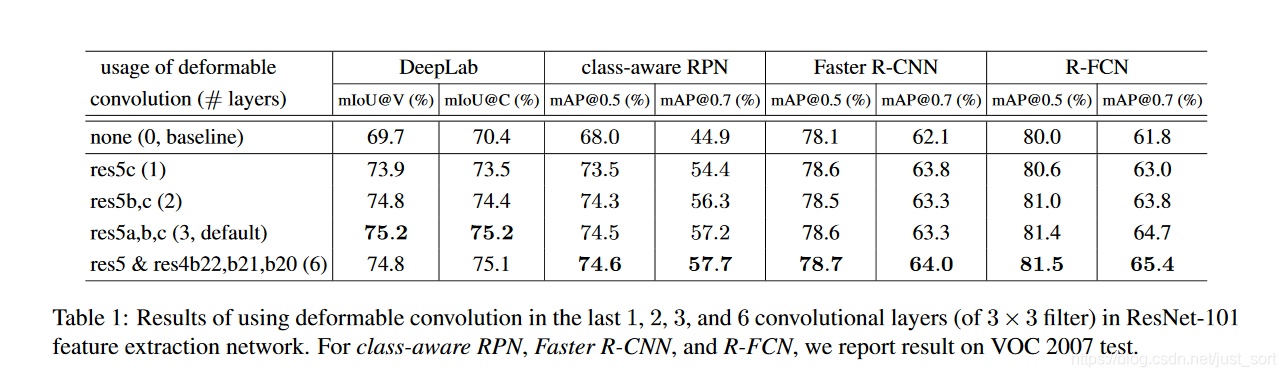
可以看到,将res5-3的三个卷积层换成可变形卷积层就有明显的效果提升并且效果基本饱和了。
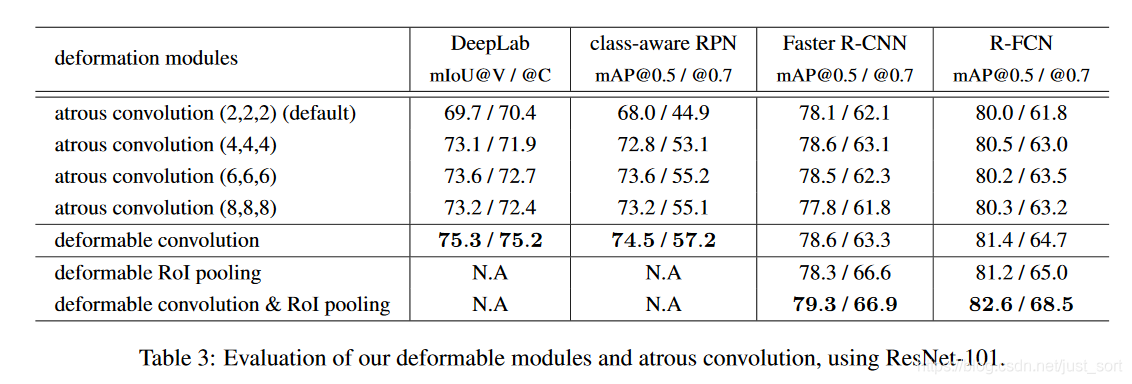
Table3 主要是和 atrous convolution 作对比,因为 atrous convolution 也是增加了普通卷积操作的感受野,所以这个对比实验是在证明都增加感受野的同时,以固定方式扩大感受野和更加灵活地聚焦到目标区域谁更优。
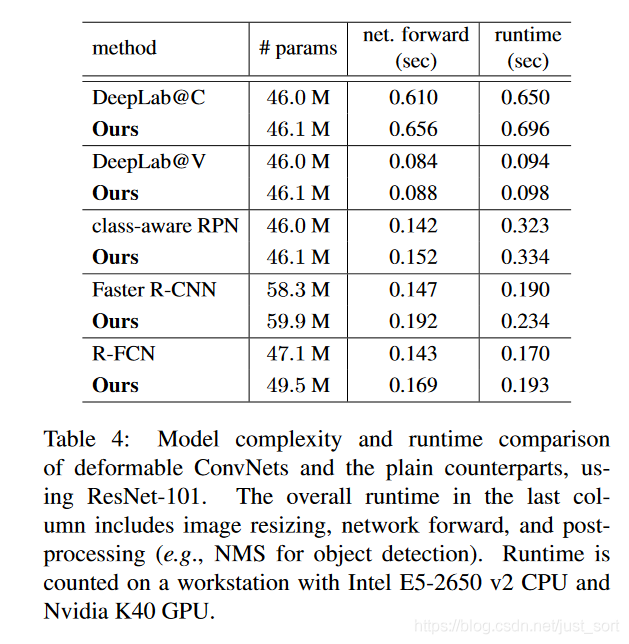
接下来 Table4 展示了模型的大小和速度对比,可以看到可变形卷积并没有带来太大的计算复杂度增长。
最后,Table5 展示了在 COCO 数据集上关于添加可变形卷积结构的效果对比,可以看到可变形卷积的提升还是非常明显的。

4. 结论
看完这篇论文只能说 MASA 果然名不虚传,实际上我理解的 DCN 也是在调感受野,只不过它的感受野是可变的,这就对图像数据中的目标本身就有大量变化的情况有很大好处了。个人感觉,这确实是目标检测领域近年来非常 solid 的一个工作了。
5. 参考
- 论文原文://arxiv.org/pdf/1703.06211.pdf
- 代码://github.com/msracver/Deformable-ConvNets
- 参考博客://blog.csdn.net/u014380165/article/details/84894089
欢迎关注 GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加 BBuf 微信:

为了方便读者获取资料以及我们公众号的作者发布一些 GitHub 工程的更新,我们成立了一个 QQ 群,二维码如下,感兴趣可以加入。



