HashMap 底層探索
其實HashMap就是一個Node數組,只是這個數組很奇怪它的每一個Node節點都有自己的下一個Node;這個是hashMap的Node的源碼;


static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
View Code
HashMap中的數組
第一個結構是它的數組,看下源碼是怎麼定義它的。
// 數組,又叫作桶(bucket) transient Node<K,V>[] table;
是定義了一個Node類型的數組對象,Node類型等下再說,其實它就HaspMap的鏈表結構,在看它的構造方法;
HashMap提供了四種構造方法;
這裡我們以第一個構造器參數
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }
View Code
主要注意最後一個方法,在我們new HashMap時,如果沒有傳參,那麼initialCapacity就是默認值,默認值是1 << 4 依舊是16,那麼現在就可以得出第一個結論,HashMap的默認大小是16。
至於initialCapacity為什麼是11我現在還是不明白?
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
桶的大小
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
View Code
這段代碼主要就是描述HashMap在進行變化的時候總是選擇2的n次方的最近的一個。
小總結:
- HashMap中數組長度最大為MAXIMUM_CAPACITY = 1 << 30 即2的30次方
- HashMap中,桶的個數總是2的n次方。但是這又引出了一個問題,為什麼HashMap桶的個數為什麼一定要是2的n次方,等下說鏈表就清楚了。
桶的擴容
final Node<K, V>[] resize() { // 舊數組 Node<K, V>[] oldTab = table; // 舊容量 int oldCap = (oldTab == null) ? 0 : oldTab.length; // 舊擴容門檻 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { // 如果舊容量達到了最大容量,則不再進行擴容 threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) // 如果舊容量的兩倍小於最大容量並且舊容量大於默認初始容量(16),則容量擴大為兩部,擴容門檻也擴大為兩倍 newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold // 使用非默認構造方法創建的map,第一次插入元素會走到這裡 // 如果舊容量為0且舊擴容門檻大於0,則把新容量賦值為舊門檻 newCap = oldThr; else { // zero initial threshold signifies using defaults // 調用默認構造方法創建的map,第一次插入元素會走到這裡 // 如果舊容量舊擴容門檻都是0,說明還未初始化過,則初始化容量為默認容量,擴容門檻為默認容量*默認裝載因子 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { // 如果新擴容門檻為0,則計算為容量*裝載因子,但不能超過最大容量 float ft = (float) newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ? (int) ft : Integer.MAX_VALUE); } // 賦值擴容門檻為新門檻 threshold = newThr; // 新建一個新容量的數組 @SuppressWarnings({"rawtypes", "unchecked"}) Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap]; .... }
View Code
根據桶擴容的代碼,我們可以得出下面三個點:(擴容門檻就是指當數組容量為多少時候進行擴容)
- 如果使用是默認構造方法,則第一次插入元素時初始化為默認值,容量為16,擴容門檻為12,擴容門檻=當前容量*擴容因子,擴容因子默認為0.75;
- 如果使用的是非默認構造方法,則第一次插入元素時初始化容量等於擴容門檻,擴容門檻在構造方法里等於傳入容量向上最近的2的n次方;
- 如果舊容量大於0,則新容量等於舊容量的2倍,但不超過最大容量2的30次方,新擴容門檻為舊擴容門檻的2倍;
在桶方面,就是這些了。繼續看看關於它的鏈表。
HashMap中的鏈表
首先對鏈表要進行一下回憶,什麼是鏈表?鏈表就是一個結構體,有頭有尾。有Next指向。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; }
View Code
HashMap裏面用的就是單鏈表節點,但是它除了存入節點值value外,還有一個變量,就是int類型的hash值。
都清楚HashMap中,鏈表是存放在桶中,那麼,問題來了,關於這個鏈表,是通過什麼標記來存入桶中的。
通過隨機數來隨機存??那樣太不嚴謹了,同時在查找的時候,怎麼才能找到這個key呢?這又是一個問題。那麼,關鍵點就在於這個int類型的hash變量的。
1.int類型的hash值,我們看下源碼hash(Object key)
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
View Code
小總結:通過key的hash值,並讓高16位與整個hash異或
這樣做是為了使計算出的hash更分散。在看它是怎麼put進桶內,
查看put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K, V>[] tab; Node<K, V> p; int n, i; // 如果桶的數量為0,則初始化 if ((tab = table) == null || (n = tab.length) == 0) // 調用resize()初始化 n = (tab = resize()).length; // (n - 1) & hash 計算元素在哪個桶中 // 如果這個桶中還沒有元素,則把這個元素放在桶中的第一個位置 if ((p = tab[i = (n - 1) & hash]) == null) // 新建一個節點放在桶中 tab[i] = newNode(hash, key, value, null); .... .... }
View Code
通過代碼(n-1)&hash。現在就是以我們上一步得到的高16位和整個hash異或運算得到的值在於桶內長度進行與運算,解釋就是如下。假如我們桶的長度是16,異或運算得出的值為11011
其實,這個算法就是取模運算,11011十進制就是27,27%16 = 11,使用位運算就是因為位運算比取模運算快很多很多。
現在又得出了另一個知識點,HashMap在確定node存放的數組位置是通過位運算通過與來得到取模的值來確定桶的位置。
同時,解決了一個疑問:為什麼HashMap桶的容量總是2的n次方。因為2的n次方可以保證,每次的取模運算與上的桶大小值用二進制表示都是1111111…比如桶個數為16,那它就是(16-1)的二進制是1111,32就是(32-1)的二進制是11111
同時在為空的桶中,創建一條node。
那問題又來了,key的值雖然不同,但是他們的hash值可以相同,那麼這樣又是怎麼解決。那麼這就是HashMap使用鏈表的理由。(hash值相同,哈希衝突)
hash相等怎麼辦
查看put方法
else { // 如果桶中已經有元素存在了 Node<K, V> e; K k; // 如果桶中第一個元素的key與待插入元素的key相同,保存到e中用於後續修改value值 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) // 如果第一個元素是樹節點,則調用樹節點的putTreeVal插入元素 e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value); else { // 遍歷這個桶對應的鏈表,binCount用於存儲鏈表中元素的個數 for (int binCount = 0; ; ++binCount) { // 如果鏈表遍歷完了都沒有找到相同key的元素,說明該key對應的元素不存在,則在鏈表最後插入一個新節點 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 如果插入新節點後鏈表長度大於8,則判斷是否需要樹化,因為第一個元素沒有加到binCount中,所以這裡-1 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } .... .... }
View Code
這個源碼涉及到了樹化和key相等的情況,稍後再講。
但是根據這上面那串源碼,發現如果確定的桶位置中已有鏈表,那直接在尾部插入元素。這裡又是HashMap在1.8的一個優化,在1.8以前,插入的算法是使用的頭插法,可以想想,如果使用頭插法,每次新插入的node都需要移位。那在並髮狀態下必然會發生問題。而使用尾插法,就可以直接在尾部插入,不需要其他node移位。
所以,這一步,得出結論,在hashMap中如果hash相同,那麼就使用的鏈表結構,通過尾插法在鏈表中保存元素。
key相同怎麼辦
還是看put方法
// 如果待插入的key在鏈表中找到了,則退出循環 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 如果找到了對應key的元素 if (e != null) { // existing mapping for key // 記錄下舊值 V oldValue = e.value; // 判斷是否需要替換舊值 if (!onlyIfAbsent || oldValue == null) // 替換舊值為新值 e.value = value; .... .... }
View Code
所以,這就是HashMap中key不能重複的原因。
自己測試,寫的代碼如下
測試結果如下:

擴容鏈表的變化 (jdk1.8)
看resize()源碼
table = newTab; // 如果舊數組不為空,則搬移元素 if (oldTab != null) { // 遍歷舊數組 for (int j = 0; j < oldCap; ++j) { Node<K, V> e; // 如果桶中第一個元素不為空,賦值給e if ((e = oldTab[j]) != null) { // 清空舊桶,便於GC回收 oldTab[j] = null; // 如果這個桶中只有一個元素,則計算它在新桶中的位置並把它搬移到新桶中 // 因為每次都擴容兩倍,所以這裡的第一個元素搬移到新桶的時候新桶肯定還沒有元素 if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) // 如果第一個元素是樹節點,則把這顆樹打散成兩顆樹插入到新桶中去 ((TreeNode<K, V>) e).split(this, newTab, j, oldCap); else { // preserve order // 如果這個鏈表不止一個元素且不是一顆樹 // 則分化成兩個鏈表插入到新的桶中去 // 比如,假如原來容量為4,3、7、11、15這四個元素都在三號桶中 // 現在擴容到8,則3和11還是在三號桶,7和15要搬移到七號桶中去 // 也就是分化成了兩個鏈表 Node<K, V> loHead = null, loTail = null; Node<K, V> hiHead = null, hiTail = null; Node<K, V> next; do { next = e.next; // (e.hash & oldCap) == 0的元素放在低位鏈表中 // 比如,3 & 4 == 0 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { // (e.hash & oldCap) != 0的元素放在高位鏈表中 // 比如,7 & 4 != 0 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // 遍歷完成分化成兩個鏈表了 // 低位鏈表在新桶中的位置與舊桶一樣(即3和11還在三號桶中) if (loTail != null) { loTail.next = null; newTab[j] = loHead; } // 高位鏈表在新桶中的位置正好是原來的位置加上舊容量(即7和15搬移到七號桶了) if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
View Code
在看看 jdk1.7
簡單點說,就是通過高低位來完成鏈表的遷移。然後分成兩個新鏈表,一次性的存放到對應的桶中。這也是HashMap在1.8的優化,在遷移鏈表,是一次性遷移的,再看看1.7,hashMap是怎麼遷移元素的
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; //尋找到下一個節點.. if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); //重新獲取hashcode e.next = newTable[i]; newTable[i] = e; e = next; } } }
View Code
遍歷node,然後重新獲取hash,一個一個遷移鏈表元素,並髮狀態下,也會出現問題。
那麼關於HashMap中的鏈表,可以總結以下幾點:
- HashMap中,通過key的hash值與桶大小進行與運算確定的元素位置。
- HashMap在遇到hash值相等的情況,是使用的鏈表尾插法來存儲新key的值,這也算是對之前的優化。
- HashMap中key不能重複,因為如果key重複,會覆蓋舊值。
- HashMap擴容遷移元素,原鏈表分化成兩個鏈表,低位鏈表存儲在原來桶的位置,高位鏈表搬移到原來桶的位置加舊容量的位置。
現在,我們的HashMap就是這樣一個結構了。
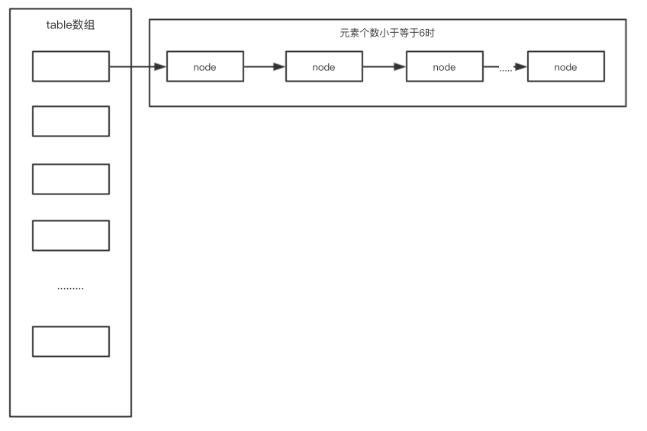
HashMap中的紅黑樹
紅黑樹是jdk1.8新加入的,當桶的數量大於64且單個桶中元素的數量大於8時,進行樹化;當單個桶中元素數量小於6時,進行反樹化。
不妨想想為什麼要加入紅黑樹這樣一個結構。
因為node是鏈表類型,鏈表這種數據結構,我們都知道,它增刪快,但是查找慢。假如我們的node鏈表長度很長,那查找耗時是必然的,所以引入了紅黑樹這樣一個結構。
後面介紹為什麼桶的數量是64的時候進行樹化(看源碼即可)。
紅黑樹介紹
紅黑樹的本質上就是一顆二叉樹,更確切的來說,紅黑樹是一顆平衡二叉樹。叫它紅黑樹的原因是紅黑樹的每個節點上都有存儲位表示節點的顏色,可以是紅或黑。
梳理下紅黑樹的特性吧
紅黑樹具有以下5種性質:
- 節點是紅色或黑色。
- 根節點是黑色。
- 每個葉節點(NIL節點,空節點)是黑色的。
- 每個紅色節點的兩個子節點都是黑色。(從每個葉子到根的所有路徑上不能有兩個連續的紅色節點)
- 從任一節點到其每個葉子的所有路徑都包含相同數目的黑色節點。
這裡要關於它的5中性質要注意兩個
特性3中的葉子節點,是只為空(NIL或null)的節點。
特性5,確保沒有一條路徑會比其他路徑長出倆倍。因而,紅黑樹是相對是接近平衡的二叉樹
紅黑樹的時間複雜度為O(log n),與樹的高度成正比。
紅黑樹在查找元素的效率比鏈表高,但是增刪元素的效率不如鏈表。這也算是一種取捨的。數組在增刪慢,鏈表在查找慢,而樹這種結構的特點夾在他們的中間。
hashMap中的紅黑樹定義
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; }
View Code
樹化
.... .... if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 如果插入新節點後鏈表長度大於8,則判斷是否需要樹化,因為第一個元素沒有加到binCount中,所以這裡-1 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } .... ....
View Code
樹化的代碼在這裡。TREEIFY_THRESHOLD的默認值是8
static final int TREEIFY_THRESHOLD = 8;
所以,HashMap在鏈表元素大於等於8時,會開始進行樹化。
final void treeifyBin(Node<K, V>[] tab, int hash) { int n, index; Node<K, V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) // 如果桶數量小於64,直接擴容而不用樹化 // 因為擴容之後,鏈表會分化成兩個鏈表,達到減少元素的作用 // 當然也不一定,比如容量為4,裏面存的全是除以4餘數等於3的元素 // 這樣即使擴容也無法減少鏈表的長度 resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K, V> hd = null, tl = null; // 把所有節點換成樹節點 do { TreeNode<K, V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); // 如果進入過上面的循環,則從頭節點開始樹化 if ((tab[index] = hd) != null) hd.treeify(tab); } }
View Code
還記得另外一個條件嘛,就是桶的數量要大於64,這也是MIN_TREEIFY_CAPACITY的默認值。
static final int MIN_TREEIFY_CAPACITY = 64;
反樹化
反樹化只有在擴容和remove元素時才會發生,先看resize方法
else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
這就是判斷它是否需要反樹化的方法
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) { TreeNode<K,V> b = this; // Relink into lo and hi lists, preserving order TreeNode<K,V> loHead = null, loTail = null; TreeNode<K,V> hiHead = null, hiTail = null; int lc = 0, hc = 0; for (TreeNode<K,V> e = b, next; e != null; e = next) { next = (TreeNode<K,V>)e.next; e.next = null; if ((e.hash & bit) == 0) { if ((e.prev = loTail) == null) loHead = e; else loTail.next = e; loTail = e; ++lc; } else { if ((e.prev = hiTail) == null) hiHead = e; else hiTail.next = e; hiTail = e; ++hc; } } if (loHead != null) { if (lc <= UNTREEIFY_THRESHOLD) tab[index] = loHead.untreeify(map); else { tab[index] = loHead; if (hiHead != null) // (else is already treeified) loHead.treeify(tab); } } if (hiHead != null) { if (hc <= UNTREEIFY_THRESHOLD) tab[index + bit] = hiHead.untreeify(map); else { tab[index + bit] = hiHead; if (loHead != null) hiHead.treeify(tab); } } }
View Code
主要還是根據高低位判斷,來切割樹,然後判斷樹中元素是不是<=UNTREEIFY_THRESHOLD
其實UNTREEIFY_THRESHOLD的默認值就是6。
if (root == null || (movable && (root.right == null || (rl = root.left) == null || rl.left == null))) { tab[index] = first.untreeify(map); // too small return; }
View Code
看源碼的注釋。太小了,所以反樹化,根據判斷條件樹的高度不超過3,就反樹化了。
那麼,總的來說,Jdk1.8的HashMap長的就是這個樣子。
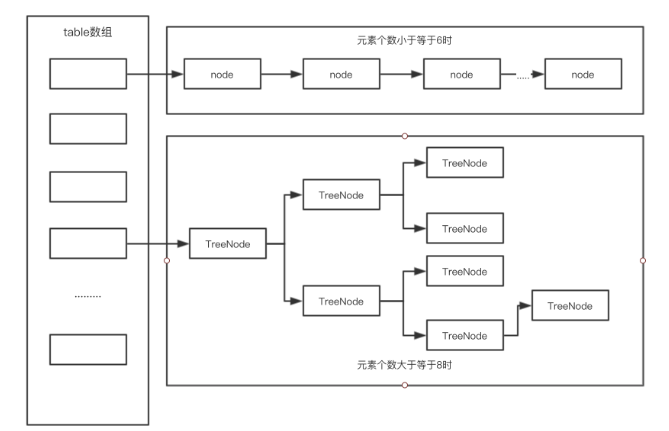
總結
總的來說,hashMap在Jdk就是數組+鏈表+紅黑樹的結構。
關於hashMap數組:
- HashMap的默認初始容量為16(1<<4),默認裝載因子為0.75f,容量總是2的n次方;
- HashMap擴容時每次容量變為原來的兩倍;
關於hashMap鏈表:
- HashMap鏈表在增加元素是通過尾插法實現的
- HashMap鏈表擴容是採用高低位來分割鏈表一次性遷移到新的桶
關於hashMap紅黑樹:
- 當桶的數量小於64時不會進行樹化,只會擴容;
- 當桶的數量大於64且單個桶中元素的數量大於8時,進行樹化;
- 當單個桶中元素數量小於6時,進行反樹化;
hashMap在Jdk 1.8的更新:
- 插入鏈表的方式採用尾插法插入。舊的方法是頭插法。
- 遷移元素根據高低位分割元素一次性遷移。舊的方法是遍歷鏈表,一次一次重新計算桶位置然後一個一個遷移。
- 加入了紅黑樹的結構。


