Python机器学习笔记:K-Means算法,DBSCAN算法
- 2020 年 4 月 28 日
- 筆記
- 机器学习常用算法及笔记
K-Means算法
K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化 elkan K-Means 算法和大数据情况下的优化 Mini Batch K-Means算法。
聚类问题的一些概念:
- 无监督问题:我们的手里没有标签了
- 聚类:就是将相似的东西分到一组
- 聚类问题的难点:如何评估,如何调参
1,K-Means原理
K-Means 算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。

如果用数据表达式表示,假设簇划分为(C1, C2, ….Ck),则我们的目标是最小化平方误差E:
 其中μi 是簇Ci的均值向量,有时也称为质心,表达式为:
其中μi 是簇Ci的均值向量,有时也称为质心,表达式为:
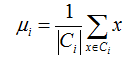
如果我们想直接求上式的最小值并不容易,这是一个 NP 难的问题,因此只能采用启发式的迭代方法。
K-Means采用的启发式方法很简单,用下面一组图就可以形象的描述。

上图a表达了初始的数据集,假设k=2,在图b中,我们随机选择了两个 k 类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图C所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图d所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f 重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心,最终我们得到了两个类别如图f。
当然在实际K-Means算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
2, 传统的K-Means算法流程
在上一节我们对K-Means的原理做了初步的探讨,这里我们对K-Means的算法做一个总结。
首先我们看看K-Means算法的一些要点:
- 1)对于K-Means算法,首先要注意的是 k 值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的 k 值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的 k 值。
- 2)在确定了 k 的个数后,我们需要选择 k 个初始化的质心,就像上图 b 中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的 k个质心,最后这些质心不能太近。
下面我们来总结一下传统的K-Means算法流程:
输入:样本集D = {x1, x2, … xm} 聚类的簇树k,最大迭代次数 N
输出:簇划分 C = {C1, C2, ….Ck}
1) 从数据集D中随机选择 k 个样本作为初始的 k 个质心向量:{ μ1, μ2, …μk }
2)对于 n=1, 2, ,,,, N
a) 将簇划分C初始化为Ct = Ø t=1,2,….k
b)对于i=1, 2, ….m,计算样本 xi 和各个质心向量 μj(j = 1, 2, … k)的距离:dij = || xi – μj ||22 ,将 xi 标记最小的为 dij 所对应的类别 λi 。此时更新 Cλi = Cλi υ {xi}
c)对于 j=1,2,…k,对Cj中所有的样本点重新计算新的质心 :
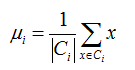
d)如果所有的k个质心向量都没有发生变换,则转到步骤3。
3)输出簇划分 C = {C1, C2, … Ck}
3,K-Means 初始化优化 K-Means ++
2007年由D.Arthur等人提出的K-Means++针对上面第一步做了改进://ilpubs.stanford.edu:8090/778/1/2006-13.pdf
上面我们提到,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的 k 个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means ++ 算法就是对K-Means随机初始化质心的方法的优化。
K-Means ++ 的对于初始化质心的优化策略也很简单,如下:
- a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心 μ1
- b) 对于数据集中的每一个点 xi,计算它与已选择的聚类中心中最近聚类中心的距离

其中 r=1,2,….Kselected
- c)选择一个新的数据点作为新的聚类中心,选择的原则是:D(x) 较大的点,被选取作为聚类中心的概率较大
- d)重复b和c 直到选择出k个聚类质心
- e)利用这k个质心来作为初始化质心去运行标准的 K-Means算法

下面结合一个简单的例子说明K-Means++是如何选取初始聚类中心的。数据集中共有8个样本,分布以及对应序号如下图所示:
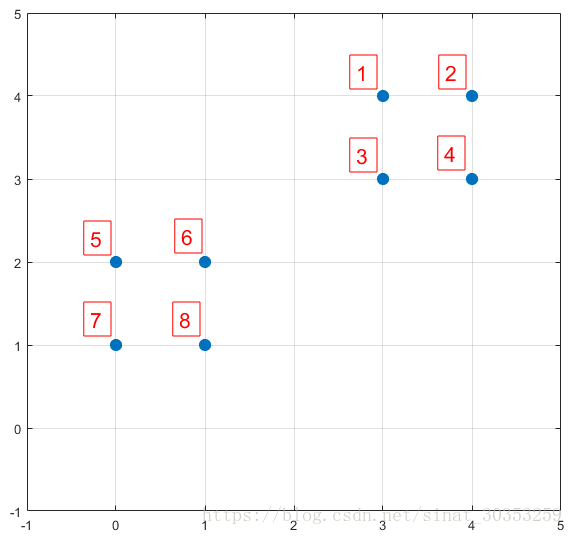
假设经过K-Means++算法的步骤1后,6号点被选择为第一个初始聚类中心,那在进行步骤2时每个样本的D(x) 和被选择为第二个聚类中心的概率如下表所示:
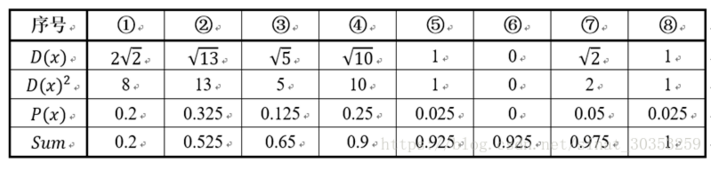
其中P(x)就是每个样本被选为下一个聚类中心的概率。最后一行的Sum是概率P(x) 的累加和。用于轮盘法选择出第二个聚类中心。方法是随机产生出一个0~1之间的随机数,判断他属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。例如1号点的区间为[0, 0.2] ,2号点的区间为[0.2, 0.525]。
从上表可以直观的看出第二个初始聚类中心时1号,2号,3号,4号中的一个的概率为0.9。而这四个点正好是离第一个初始聚类中心6号点较远的四个点。这也验证了K-Means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。可以看出,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为D(x)。
4,K-Means 距离计算优化 elkan K-Means
在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有质心的距离,这样会比较的耗时。那么,对于距离的计算有没有能够简化的地方呢?elkan K-Means算法就是从这块入手加以改进。它的目标是减少不必要的距离的计算。那么那些距离不需要计算呢?
elkan K-Means 利用了两边之和大于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算。
第一种规律是对于一个样本点 x 和两个质心 μj1, μj2。如果我们预先计算出了这两个质心之间的距离D(j1, j2),则如果计算发现 2D(x, j1) <= D(j1, j2),我们立即就可以知道 D(x, j1) <= D(x, j2)。此时我们不需要计算D(x, j2),也就是说省了一步距离计算。
第二种规律是对于一个样本点 x 和两个质心 μj1, μj2。我们可以计算得到 D(x, j2) >= max {0, D(x, j1) – D(j1, j2)}。这个从三角形的性质也很容易得到。
如果利用上面的两个规律,elkan K-Means 比起传统的K-Means迭代速度有很大的提升。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法。
5,大样本优化 Mini Batch K-Means
在传统的K-Means算法中,要计算所有的样本点到所有的质心的距离。如果样本量非常大。比如达到10万以上,特征由100以上,此时用传统的K-Means算法非常的耗时,就算加上 elkan K-Means 优化也是如此。在大数据时代,这样的场景越来越多。此时Mini Batch K-Means 应运而生。
顾名思义,Mini Batch,也就是用样本集中的一部分样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在Mini Batch K-Means中,我们会选择一个合适的批样本大小 batch size,我们仅仅用 batch size 个样本来做K-means聚类。那么这 batch size 个样本怎么来的呢?一般是通过无放回的随机采样得到的。
为了增加算法的准确性,我们一般会多跑几次 Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
6,K-Means与KNN的对比
我们很容易将K-Means与KNN搞混,但是两者差别还是很大的。
K-Means是无监督学习的聚类算法,没有样本输出;而KNN则是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。
当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点,两者都利用了最近邻(nearest neighbors)的思想。
而KNN算法可以参考我的博客:
Python机器学习笔记:K-近邻(KNN)算法
7,K-Means小结
K-Means是个简单实用的聚类算法,这里对K-Means的优缺点做一个总结。
7.1 K-Means的主要优点:
- 1,原理比较简单,实现也是很容易,收敛速度快
- 2,聚类效果较优(依赖K的选择)
- 3,算法的可解释度比较强
- 4,主要需要调参的参数仅仅是簇数 k
7.2 K-Means的主要缺点:
- 1,K值的选取不好把握
- 2,对于不是凸的数据集比较难收敛
- 3,如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳
- 4,采用迭代方法,得到的结果只能保证局部最优,不一定是全局最优(与K的个数及初值选取有关)
- 5,对噪音和异常点比较的敏感(中心点易偏移)
sklearn实现K-Means算法
1,K-Means类概述
在scikit-learn中,包括两个K-Means的算法,一个是传统的K-Means算法,对应的类时K-Means。另一个是基于采样的 Mini Batch K-Means算法,对应的类是 MiniBatchKMeans。一般来说,使用K-Means的算法调参是比较简单的。
用K-Means类的话,一般要注意的仅仅就是 k 值的选择,即参数 n_clusters:如果是用MiniBatch K-Means 的话,也仅仅多了需要注意调参的参数 batch_size,即我们的 Mini Batch 的大小。
当然K-Means类和MiniBatch K-Means类可以选择的参数还有不少,但是大多不需要怎么去调参。下面看看K-Means类和 MiniBatch K-Means类的一些主要参数。
2,K-Means类的主要参数
参数源码如下:

1) n_clusters: 即我们的k值,一般需要多试一些值以获得较好的聚类效果。k值好坏的评估标准在下面会讲。
2)max_iter: 最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。
3)n_init:用不同的初始化质心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。如果你的k值较大,则可以适当增大这个值。
4)init: 即初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++’或者自己指定初始化的k个质心。一般建议使用默认的’k-means++’。
5)algorithm:有“auto”, “full” or “elkan”三种选择。”full”就是我们传统的K-Means算法, “elkan”是我们原理篇讲的elkan K-Means算法。默认的”auto”则会根据数据值是否是稀疏的,来决定如何选择”full”和“elkan”。一般数据是稠密的,那么就是 “elkan”,否则就是”full”。一般来说建议直接用默认的”auto”
3,MiniBatch K-Means类的主要参数
参数源码如下:
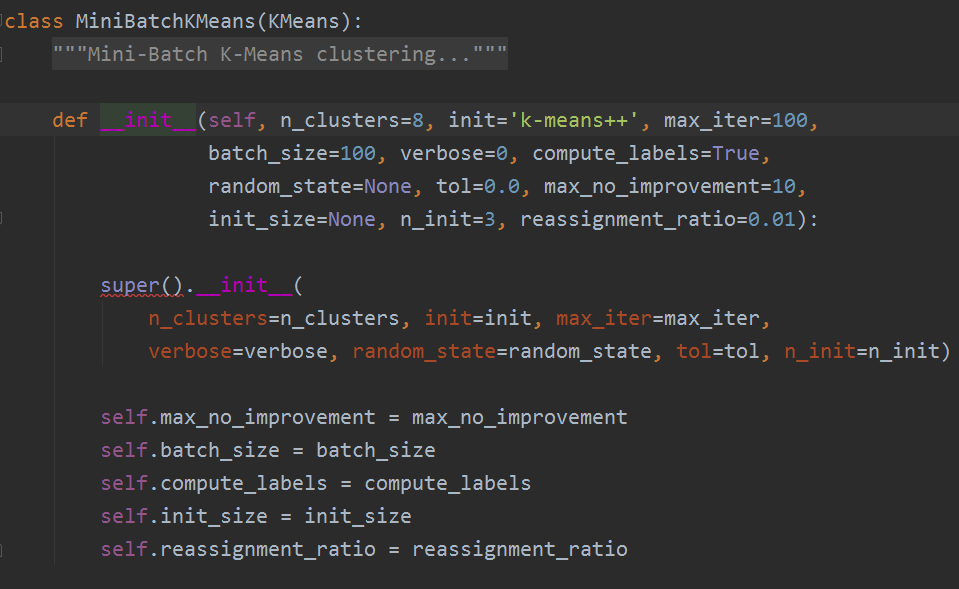
1) n_clusters: 即我们的k值,和KMeans类的n_clusters意义一样。
2)max_iter:最大的迭代次数, 和KMeans类的max_iter意义一样。
3)n_init:用不同的初始化质心运行算法的次数。这里和KMeans类意义稍有不同,KMeans类里的n_init是用同样的训练集数据来跑不同的初始化质心从而运行算法。而MiniBatchKMeans类的n_init则是每次用不一样的采样数据集来跑不同的初始化质心运行算法。
4)batch_size:即用来跑Mini Batch KMeans算法的采样集的大小,默认是100.如果发现数据集的类别较多或者噪音点较多,需要增加这个值以达到较好的聚类效果。
5)init: 即初始值选择的方式,和KMeans类的init意义一样。
6)init_size: 用来做质心初始值候选的样本个数,默认是batch_size的3倍,一般用默认值就可以了。
7)reassignment_ratio: 某个类别质心被重新赋值的最大次数比例,这个和max_iter一样是为了控制算法运行时间的。这个比例是占样本总数的比例,乘以样本总数就得到了每个类别质心可以重新赋值的次数。如果取值较高的话算法收敛时间可能会增加,尤其是那些暂时拥有样本数较少的质心。默认是0.01。如果数据量不是超大的话,比如1w以下,建议使用默认值。如果数据量超过1w,类别又比较多,可能需要适当减少这个比例值。具体要根据训练集来决定。
8)max_no_improvement:即连续多少个Mini Batch没有改善聚类效果的话,就停止算法, 和reassignment_ratio, max_iter一样是为了控制算法运行时间的。默认是10.一般用默认值就足够了。
4,K值的评估标准
不像监督学习的分类问题和回归问题,我们的无监督聚类没有样本输出,也就没有比较直接的聚类评估方法。但是我们可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。常见的方法有轮廓稀疏Silhouette Coefficient和 Calinski Harabasz Index。个人比较喜欢Calinski-Harabasz Index,这个计算简单直接,得到的Calinski-Harabasz分数值 s 越大则聚类效果越好。
Calinski-Harabasz 分数值 s 的数学计算公式是:
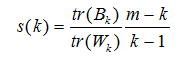
其中 m 为训练集样本数,k为类别数。Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵。tr为矩阵的迹。
也就是说,类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的 Calinski-Harabasz 分数会高。在scikit-learn 中, Calinski-Harabasz Index对应的方法就是 metrics.calinski_harabaz_score。
5,K-Means 应用实例
下面用一个示例来学习KMeans类和MiniBatchKMeans 类来聚类。我们观察在不同的k值下Calinski-Harabasz 分数。
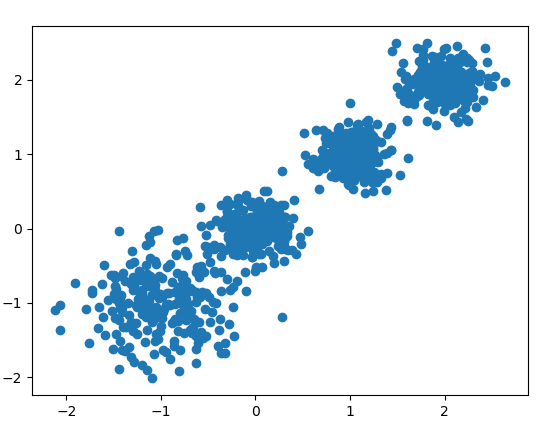
首先我们需要随机创建一些二维数据作为训练集,选择二维特征数据,主要是方便可视化,如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
# sklearn 中的make_blobs方法常被用来生成聚类算法的测试数据
# X为样本特征,Y为样本簇类别,共1000个样本,每个样本2个特征,共4个簇
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
# n_samples表示产生多少个数据 n_features表示数据是几维的
# centers表示数据点中心,可以输入整数,代表有几个中心,也可以输入几个坐标
# cluster_std表示分布的标准差
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
生成的图如下:
下面我们用K-Means聚类方法来做聚类,首先选择 k=2,代码如下:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs from sklearn.cluster import KMeans clf = KMeans(n_clusters=2, random_state=9) y_pred = clf.fit_predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_pred, marker='o') plt.show()
k=2聚类的效果图输出如下:
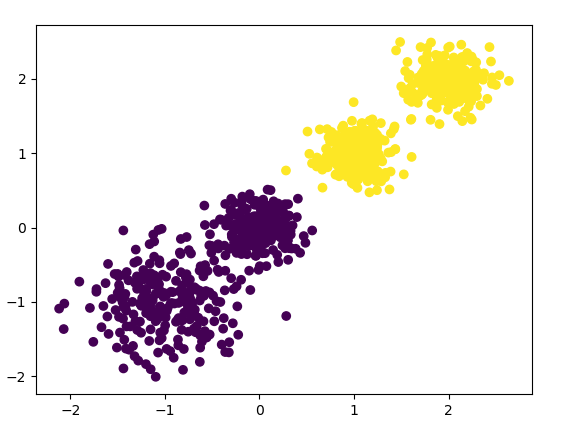
下面使用Calinski-Harabasz Index 评估的聚类分数:
from sklearn import metrics metrics.calinski_harabaz_score(X, y_pred) # 3116.1706763322227
下面再来看看 k=3的聚类效果,代码微调即可:
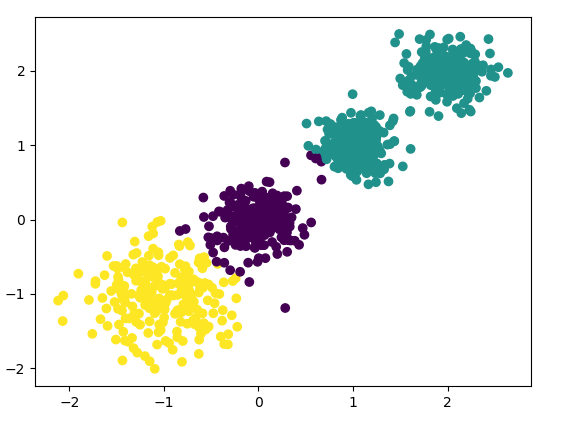
Calinski-Harabaz Index评估的 k=3 时聚类分数为:
2931.625030199556
最后看看 K=4的聚类效果:
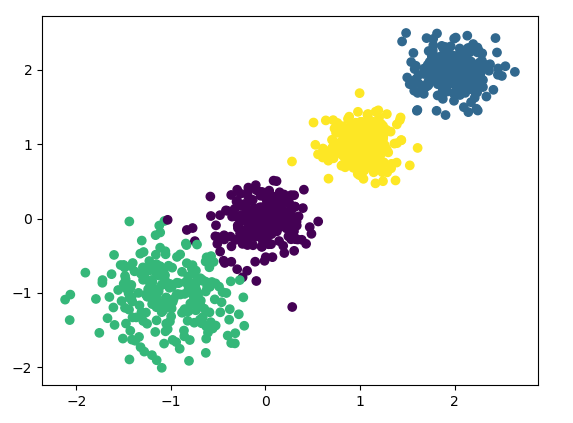
Calinski-Harabaz Index评估的 k=4 时聚类分数为:
5924.050613480169
这个分数是这样的,当聚类分数越大,则说明效果越好,我们可以看到上面k=3的聚类分数比k=2的差,但是k=4的聚类分数比k=2和k=3的都要高,而我们开始设定的随机数据集就是四个簇,所以这符合我们的预期,当特征维度大于2,我们无法直接可视化聚类效果来肉眼观察时,用Calinski-Harabaz Index评估是一个很实用的方法。
下面我们再看看用 MiniBatch K-Means 的效果,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans, MiniBatchKMeans
from sklearn import metrics
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9)
for index, k in enumerate((2, 3, 4, 5)):
plt.subplot(2, 2, index + 1)
clf = MiniBatchKMeans(n_clusters=k, batch_size=200, random_state=9)
y_pred = clf.fit_predict(X)
score = metrics.calinski_harabaz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.text(.99, .01, ('k=%d, score: %.2f' % (k, score)),
transform=plt.gca().transAxes, size=10,
horizontalalignment='right')
plt.show()
对于k=2,3,4,5 对应的输出图为:
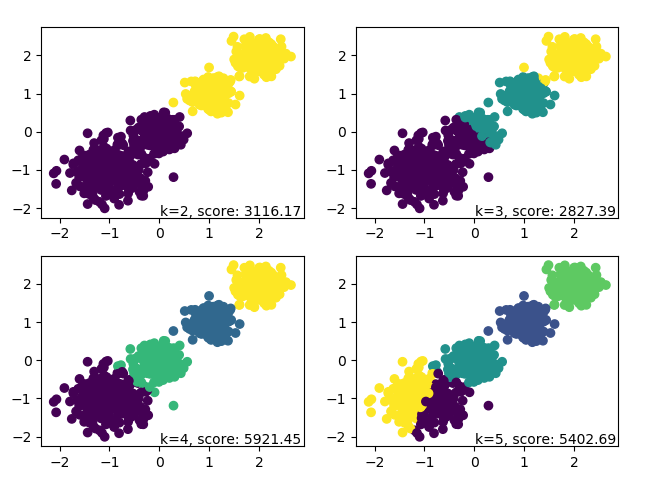
可见使用MiniBatchKMeans的聚类效果也不错,当然由于使用Mini Batch的原因,同样是k=4最优,KMeans类的Calinski-Harabasz Index分数为5924.05,而MiniBatchKMeans的分数稍微低一些,为5921.45。这个差异损耗并不大。
DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Appliactions with Noise,具有噪音的基于密度的聚类方法)是一种很典型的密度聚类算法,是数据挖掘中最经典基于密度的聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。下面学习一下DBSCAN算法的原理
1,密度聚集原理
基于密度的聚类寻找被低密度区域分离的高密度区域。DBSCAN是一种简单,有效的基于密度的聚类算法,它解释了基于密度的聚类方法的许多重要概念,在这里我们仅关注DBSCAN。
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间是紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
如图所示:A为核心对象 ; BC为边界点 ; N为离群点; 圆圈代表 ε-邻域
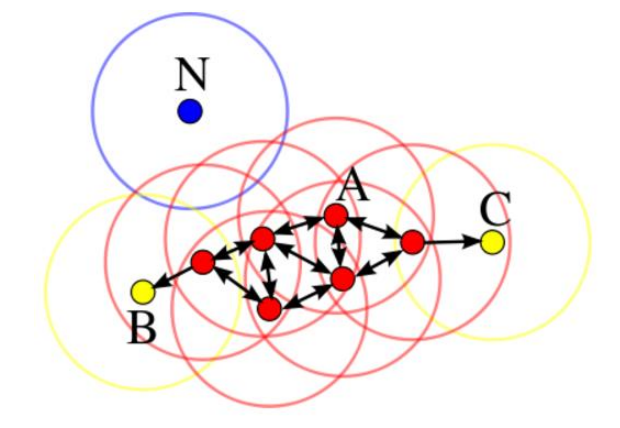
DBSCAN算法的本质是一个发现类簇并不断扩展类簇的过程。对于任意一点q,若他是核心点,则在该点为中心,r为半径可以形成一个类簇 c。而扩展的方法就是,遍历类簇c内所有点,判断每个点是否是核心点,若是,则将该点的 ε-邻域也划入类簇c,递归执行,知道不能太扩展类簇C。
假设上图中 minPts为3,r为图中圆圈的半径,算法从A开始,经计算其为核心点,则将点A及其邻域内的所有点(共四个)归为类Q,接着尝试扩展类Q。查询可知类Q内所有的点均为核心点(红点),故皆具有扩展能力,点C也被划入类Q。在递归扩展的过程中,查询得知C不是核心点,类Q不能从点C出扩充,称C为边界点。边界点被定义为属于某一个类的非核心点。在若干次扩展以后类Q不能再扩张,此时形成的类为图中除N外的所有的点,点N则称为噪声点。即不属于任何一个类簇的点,等价的可以定义为从任何一个核心点出发都是密度不可达的。在上图中数据点只能聚成一个类,在实际使用中往往会有多个类,即在某一类扩展完成后另外选择一个未被归类的核心点形成一个新的类簇并扩展,算法结束的标志是所有的点都已被划入某一类或噪声,且所有的类都是不可再扩展。
上面提到了几个概念,下面细说一下:
核心点(core point):这些点在基于密度的簇内部。点的邻域由距离函数和用户指定的距离参数 Eps 决定。核心点的定义是,如果该点的给定邻域内的点的个数超过给定的阈值MinPts,其中MinPts也是一个用户指定的参数。
边界点(border point):边界点不是核心点,但它落在某个核心点的邻域内。如上图B点。
噪声点(noise point):噪声点是即非核心点也是非边界点的任何点。如上图N点。
2,DBSCAN密度定义
在上面我们定性描述了密度聚类的基本思想,下面我们看看DBSCAN是如何描述密度聚类的。DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ε,MinPts)用来描述邻域的样本分布紧密程度。其中 ε 描述了某一样本的邻域距离阈值,MinPts 描述了某一样本的距离为 ε的邻域中样本个数的阈值。
假设我的样本集是D=(x1, x2,…,Xm) 则DBSCAN 具体的密度描述定义如下:
1) ε-邻域:对于xj € D,其 ε- 邻域包含样本集D中与 xj 的距离不大于 ε 的子样本集,即Nε(xj)={xi € D| distance(xi, xj) <= ε},这个子样本集的个数记为 | Nε(xj)|
2)核心对象:对于任一样本xj € D ,如果其 ε- 邻域对应的 Nε(xj) 至少包含 MinPts个样本,即如果 | Nε(xj)| >= MinPts,则xj是核心对象。简单来说就是若某个点的密度达到算法设定的阈值则其为核心点
3)密度直达:如果 xi 位于 xj 的 ε- 邻域中,且 xj是核心对象,则称 xi 由 xj 密度直达。注意反之不一定成立,即此时不能说 xj 由 xi 密度直达,除非且 xi 也是核心对象
4)密度可达:对于 xi 和 xj ,如果存在样本序列 p1, p2, …pT,满足p1=xi, pT=xj,且pt+1由 pt 密度直达,则称xj 由 xi 密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本 p1, p2,…..pT-1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于xi和xj ,如果存在核心对象样本 xk,使 xi 和 xj 均由 xk 密度可达,则称 xi 和 xj 密度相连。注意密度相连关系是满足对称性的。
从下图可以很容易理解上述定义,图中 MinPts=5,红色的点都是核心对象,因为其 ε- 邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列 ε-邻域内所有的样本相互都是密度相连的。
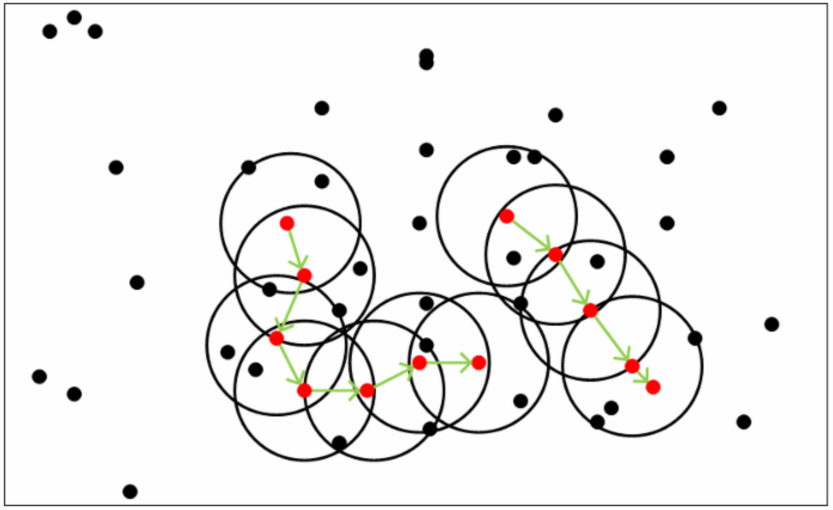
这是一个老师的PPT:

参数选择:

3,DBSCAN密度聚类思想
DBSCAN的聚类定义很简单:由密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的 ε- 邻域里;如果有多个核心对象,则簇里的任意一个核心对象的 ε- 邻域中一定有一个其他的核心对象。否则这两个核心对象无法密度可达。这些核心对象的 ε- 邻域里所有的样本的集合组成的一个 DBSCAN聚类簇。
那么怎么才能找到这样的簇样本集合呢?DBSCAN使用方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到了另一个聚类簇。一直运行到所有核心对象都有类别为止。
基本上这就是DBSCAN算法的主要内容了,但是我们还有三个问题没有考虑。
第一是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
第二是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧氏距离。这种和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一半采用KD树或者球树来快速的搜索最近邻。如果对最近邻的思想不熟悉,可以看KNN算法。
第三种问题比较特殊,某些样本可能到两个核心对象的距离都小于 ε ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说DBSCAN算法不是完全稳定的算法。
4,DBSCAN聚类算法
下面对DBSCAN聚类算法的流程做一个总结:

输入:样本集D=(x1, x2, …xm),邻域参数(ε, MinPts),样本距离度量方法
输出:簇划分C
1)初始化核心对象集合 Ω = Φ ,初始化聚类簇数 k=0,初始化未访问样本集合 Γ = D,簇划分 C = Φ
2) 对于j=1,2,…m,按下面的步骤找出所有的核心对象:
a)通过距离度量方法,找到样本 xj 的 ε-邻域子样本集 Nε(xj)
b)如果子样本集样本个数满足 | Nε(xj)| >= MinPts,将样本 xj 加入到核心对象样本集合:Ω = Ω υ {xj}
3)如果核心对象集合 Ω = Φ,则算法结束,否则转入步骤4.
4)在核心对象集合Ω 中,随机选择一个核心对象 o, 初始化当前簇核心对象队列 Ωcur ={o},初始化类别序号 k=k+1,初始化当前簇样本集合 Ck={o},更新未访问样本集合 Γ = Γ – {o}
5)如果当前簇核心对象队列 Ωcur = Φ,则当前聚类簇Ck 生成完毕,更新簇划分 C={C1, C2, …Ck},更新核心对象集合 Ω = Ω – Ck,转入步骤3,否则更新核心对象集合 Ω = Ω – Ck
6)在当前簇核心对象队列 Ω cur 中取出一个核心对象 o’,通过邻域距离阈值 ε 找出所欲的 ε-邻域子样本集 Nε(o’),令 Δ = Nε(o’) n Γ ,更新当前簇样本集合Ck = Ck υ Δ ,更新未访问样本集合 Γ = Γ – Δ,更新 Ωcur = Ωcur υ (Δ n Ω) – o’,转入步骤5
输出结果为:簇划分C={C1,C2,…Ck}
如果上面解释太复杂,我们可以看下面DBSCAN的步骤:
- 1,将所有点标记为核心点,边界点或噪声点
- 2,删除噪声点
- 3,为距离在Eps内的所有核心点之间赋予一条边
- 4,每组连通的核心点形成一个簇
- 5,将每个边界点指派到一个与之无关的核心点的簇中
5,DBSCAN 小结
和传统的K-Means算法相比,DBSCAN最大的不同激素不需要输入类别k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类,同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐使用DBSCAN来聚类。
下面对DBSCAN算法的优缺点做一个总结:
5.1 DBSCAN优点:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3)聚类结果没有偏倚,相对的K,K-Means之类的聚类算法那初始值对聚类结果有很大的影响。
5.2 DBSCAN缺点:
1)如果样本集的密度不均匀,聚类间距离相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2)如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3)调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值 ε ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。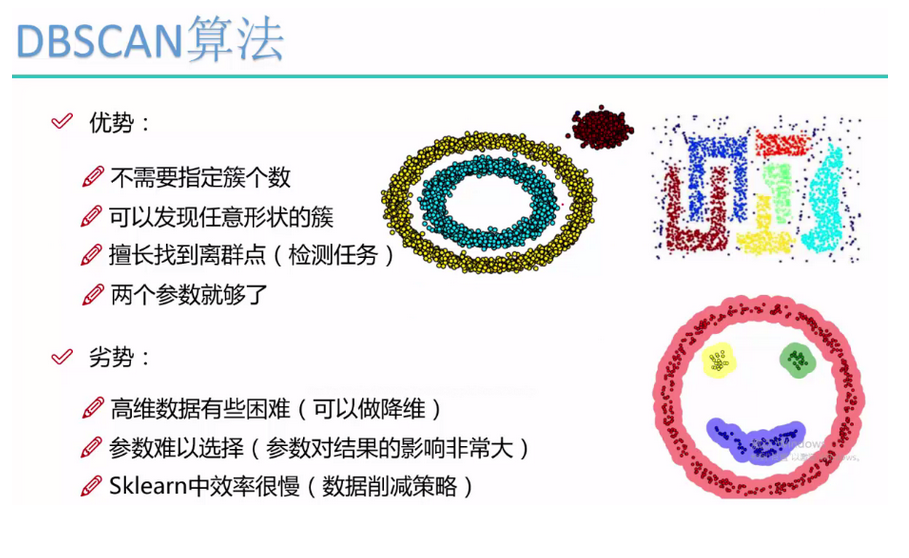
5.3 DBSCAN和K-Means算法的区别:
- 1,可以不需要事先指定cluster的个数
- 2,可以找出不规则形状的cluster
sklearn实现DBSCAN算法
在sklearn中,DBSCAN算法类为sklearn.cluster.DBSCAN。要熟练的掌握用DBSCAN类来聚类,除了对DBSCAN本身的原理有较深的理解之外,还要对最近邻的思想有一定的理解。结合这两者,就可以熟练应用DBSCAN。
1,DBSCAN类重要参数
参数部分源码:
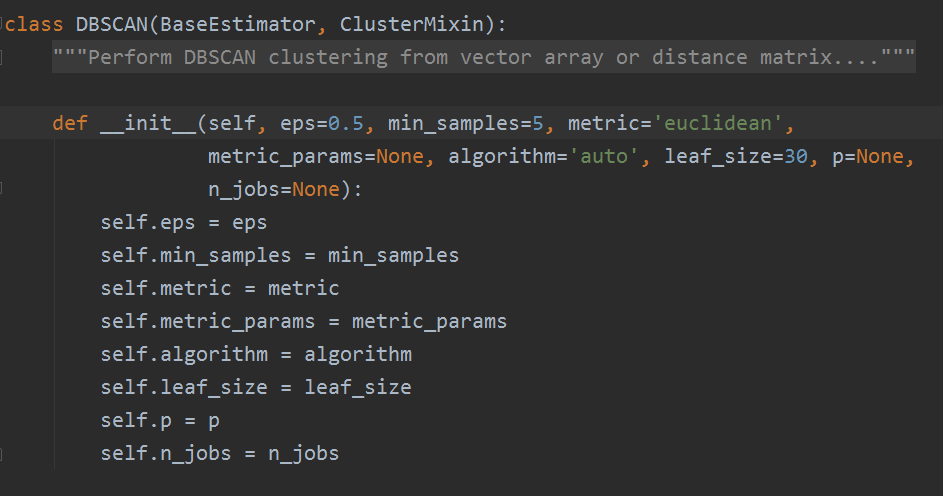
1)eps:DBSCAN算法参数,即我们的 ε- 邻域的距离阈值,和样本距离超过ε- 的样本点不在ε- 邻域内,默认值是0.5。一般需要通过在多组值里面选择一个合适的阈值,eps过大,则更多的点会落在核心对象的ε- 邻域,此时我们的类别数可能会减少,本来不应该是一类的样本也会被划分为一类。反之则类别数可能会增大,本来是一类的样本却被划分开。
2)min_samples:DBSCAN算法参数,即样本点要成为核心对象所需要的ε- 邻域的样本数阈值,默认是5。一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下,min_smaples过大,则核心对象会过少,此时簇内部分本来是一类的样本可能会被标为噪音点,类别数也会变多。反之 min_smaples过小的话,则会产生大量的核心对象,可能会导致类别数过少。
3)metric:最近邻距离度量参数,可以使用的距离度量较多,一般来说DBSCAN使用默认的欧式距离(即 p=2 的闵可夫斯基距离)就可以满足我们的需求。可以使用的距离度量参数有:欧式距离,曼哈顿距离,切比雪夫距离,闵可夫斯基距离,马氏距离等等。
4)algorithm:最近邻搜索算法参数,算法一共有三种,第一种是蛮力实现,第二种是KD树实现,第三种是球树实现,对于这个参数,一共有4种可选输入,‘brute’对应第一种蛮力实现,‘kd_tree’对应第二种KD树实现,‘ball_tree’对应第三种的球树实现, ‘auto’则会在上面三种算法中做权衡,选择一个拟合最好的最优算法。需要注意的是,如果输入样本特征是稀疏的时候,无论我们选择哪种算法,最后scikit-learn都会去用蛮力实现‘brute’。个人的经验,一般情况使用默认的 ‘auto’就够了。 如果数据量很大或者特征也很多,用”auto”建树时间可能会很长,效率不高,建议选择KD树实现‘kd_tree’,此时如果发现‘kd_tree’速度比较慢或者已经知道样本分布不是很均匀时,可以尝试用‘ball_tree’。而如果输入样本是稀疏的,无论你选择哪个算法最后实际运行的都是‘brute’。
5)leaf_size: 最近邻搜索算法参数,为使用KD树或者球树时,停止建子树的叶子节点数量的阈值。这个值越小,则生成的KD树或者球树就越大,层数越深,建树时间越长,反之,则生成的KD树或者球树会小,层数较浅,建树时间较短。默认是30,因为这个值一般只影响算法的运行速度和使用内存大小,因此一般情况可以不管它。
6)p:最近邻距离度量参数。只用于闵可夫斯基距离和带权值闵可夫斯基距离中 p 值的选择, p=1为曼哈顿距离,p=2为欧式距离,如果使用默认的欧式距离就不需要管这个参数。
以上就是DBSCAN类的主要参数介绍,其实需要调参的就是两个参数eps和min_samples,这两个值的组合对最终的聚类效果有很大的影响。
2,Sklearn DBSCAN聚类实例
首先,我们随机生成一组数据,为了体现DBSCAN在非凸数据的聚类有点,我们生成了两簇数据,然后再将这两簇结合起来,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_circles
# 下面我们生成三组数据
X1, y1 = make_circles(n_samples=5000, factor=0.6, noise=0.05)
X2, y2 = make_blobs(n_samples=1000, n_features=2, centers=[[1.2, 1.2]],
cluster_std=[[0.1]], random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
将这两簇数据结合起来,图如下:
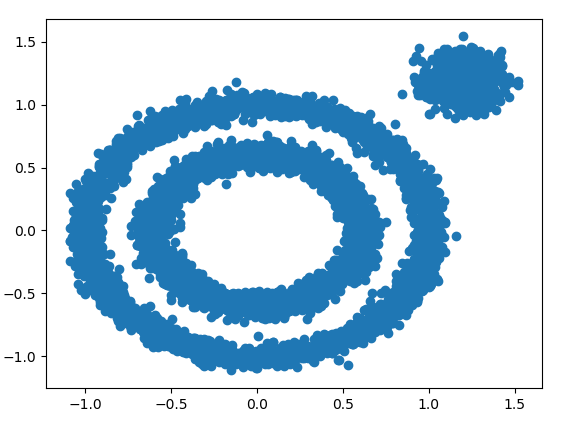
下面我们先看看K-Means的聚类效果,代码如下:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()
结果图如下:
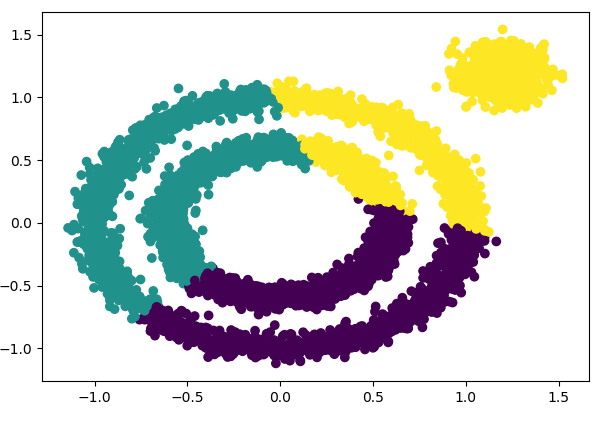
从上面代码输出的聚类效果图可以明显看出:K-Means对于非凸数据集的聚类表现不好。
那么如果使用DBSCAN效果如何呢?我们先不调参,直接使用默认参数,看看聚类效果,代码如下:
from sklearn.cluster import DBSCAN
y_pred = DBSCAN().fit_predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()
结果图如下:

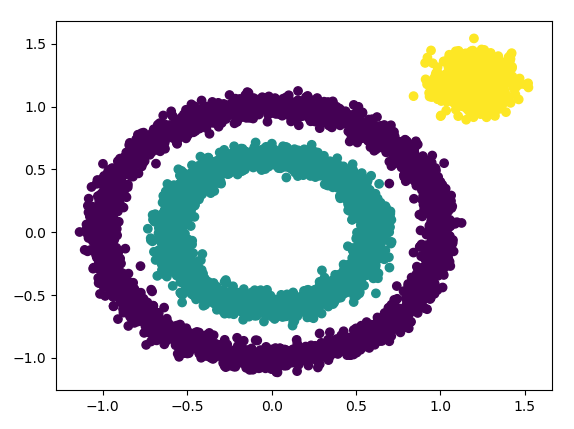
我们发现输出结果不好,DBSCAN居然认为所有的数据都是一类。
下面我们尝试调参,我们需要对DBSCAN的两个关键的参数eps和min_samples进行调参!从上图我们可以发现,类别数太少,我们需要增加类别数,那么我们可以减少 ε- 邻域的大小,默认是0.5,我们减少到0.1看看效果,代码如下:
y_pred = DBSCAN(eps = 0.1).fit_predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()
对应的聚类效果图如下:
可以看到聚类效果有了很大的改进。此时我们可以继续调参增加类别,有两个方向都是可以的,一个是继续减少eps,另一个是增加min_samples。我们现在将min_samples从默认的5增加到10,代码如下:
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X) plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()
效果图如下:
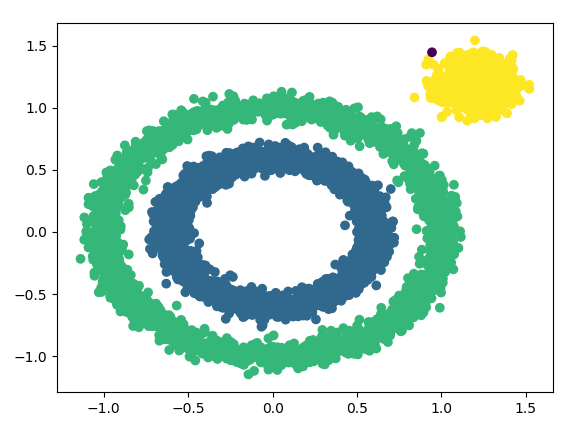
出现了一个异常点。。。。不过我们可以使用不调参的模型,聚类效果比较好。
上面这个例子只是帮大家理解DBSCAN调参的一个基本思路,在实际运用中可能要考虑很多问题,以及更多的参数组合,希望这个例子可以给大家一些启发。
聚类案例实战
1,聚类算法评估方法:轮廓系数(Silhouette Coefficient)
Silhouette 系数是对聚类结果有效性的解释和验证,由Peter J. Rousseeuw 于 1986年提出。
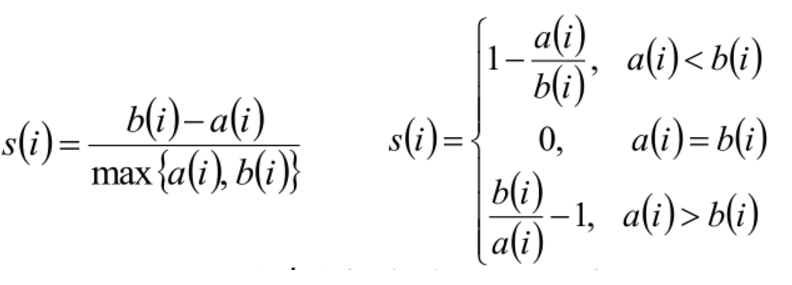
- 计算样本 i 到同簇其他样本的平均距离ai,ai越小,说明样本 i 越应该被聚类到该簇,将 ai 称为样本 i 的簇内不相似度。
- 计算样本 i 到其他某簇 Cj 的所有样本的平均距离 bij,称为样本 i 与簇 Cj 的不相似度。定义为样本 i 的簇间不相似度:bi = min{bi1, bi2, …bik}
- si 接近1,则说明样本 i 聚类合理
- si 接近 -1 ,则说明样本 i 更应该分类到另外的簇
- 若 si 近似为0,则说明样本 i 在两个簇的边界上
2,四种聚类算法的对比图
这里使用了BIRCH,DBSCAN,K-Means,MEAN-SHIFT四种算法那,横轴表示各个特征,宗轴表示预测特征的准确率。而且横轴对数据特征进行了增强。
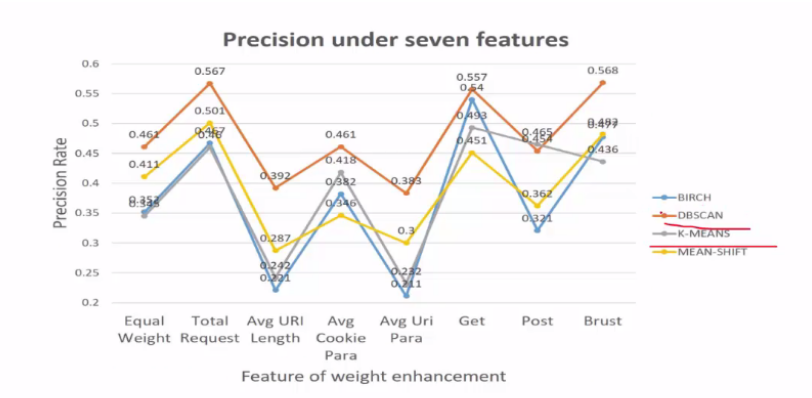
总体的趋势表示了算法的差异,也就是说DBSCAN的能力比其他算法普遍都好。它可以让我们的准确率更高,其他的三个算法都差不多。所以一般情况最好使用DBSCAN算法。
3,聚类算法实战
数据去我的GitHub上拿,GitHub地址://github.com/LeBron-Jian/MachineLearningNote
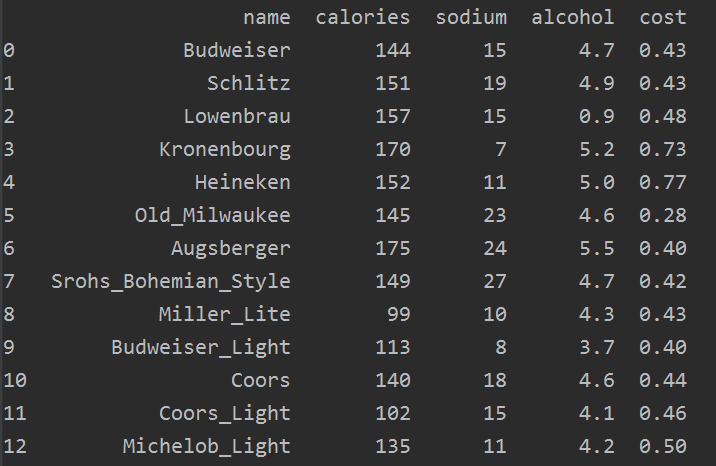
数据是简单的啤酒数据,包含了四个特征分别是卡路里,钠,酒精,价格。包含了20种不同的啤酒品牌。
我们的目的是使用sklearn演示聚类算法如何实现,下面对数据做简单的分析
# beer dataset from my github import pandas as pd beer = pd.read_csv(filename, sep=' ') print(beer)
我们首先可以看看数据,数据只有一点点:
我们拿出特征,也就是上面提到的四个变量:
X = beer[['calories', 'sodium', 'alcohol', 'cost']]
因为聚类算法是无监督的算法,所以不需要lables,只要特征即可。我们拿到特征后,就可以进行K-Means算法训练。sklearn中的聚类算法都在cluster类里面。下面分别用两个堆,三个堆做聚类。
# beer dataset from my github import pandas as pd from sklearn.cluster import KMeans, DBSCAN km1 = KMeans(n_clusters=3) clf1 = km1.fit(features) km2 = KMeans(n_clusters=2) clf2 = km2.fit(features) print(clf1.labels_) print(clf2.labels_)
我们可以先查看一下其预测出来的标签,下面lables表明数据属于那个类别,如果是两类,则为0,1;如果是三类则为0, 1, 2,最后预测结果如下:
[0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 2 0 0 2 1] [0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 0 1 1]
我们也可以把分好的类,加入到源数据中查看分类结果(因为数据比较小,所以可以这样做)
beer['cluster1'] = clf1.labels_
beer['cluster2'] = clf2.labels_
res = beer.sort_values('cluster1')
print(res)
结果如下:

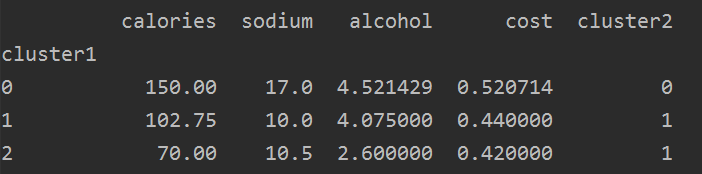
下面我们找聚类的中心,可以使用groupby查看其均值,看看不同含量的差异性。
from pandas.plotting import scatter_matrix
cluster_centers1 = clf1.cluster_centers_
cluster_centers2 = clf2.cluster_centers_
group_res1 = beer.groupby('cluster1').mean()
group_res2 = beer.groupby('cluster2').mean()
print(group_res1)
print(group_res2)
结果如下:

下面我们画图看:
centers1 = group_res1.reset_index()
plt.rcParams['font.size'] = 14
colors = np.array(['red', 'green', 'blue', 'yellow'])
plt.scatter(beer['calories'], beer['alcohol'], c=colors[beer['cluster1']])
plt.scatter(centers1.calories, centers1.alcohol, linewidths=3, marker='+', s=300, c='black')
plt.xlabel('Calories')
plt.ylabel('Alcohol')
图如下:
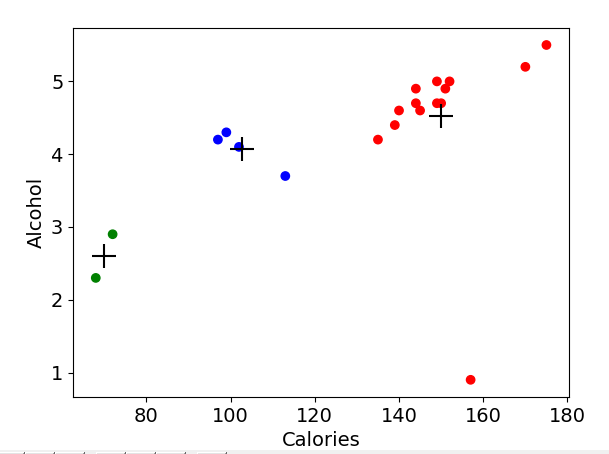
上图是聚类的效果,左边绿色的是一簇,中间蓝色的是一簇,右边红色的是一簇。
下面我们可以对这四个特征,两两进行比较,看看每两个指标在二维图上的聚类效果,代码如下:
scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']],
s=100, alpha=1, c=colors[beer['cluster1']], figsize=(10, 10))
plt.title('With 3 centroids initialized')
scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']],
s=100, alpha=1, c=colors[beer['cluster2']], figsize=(10, 10))
plt.title('With 3 centroids initialized')
图如下:(第一个是簇为3的,第二个是簇为2的)
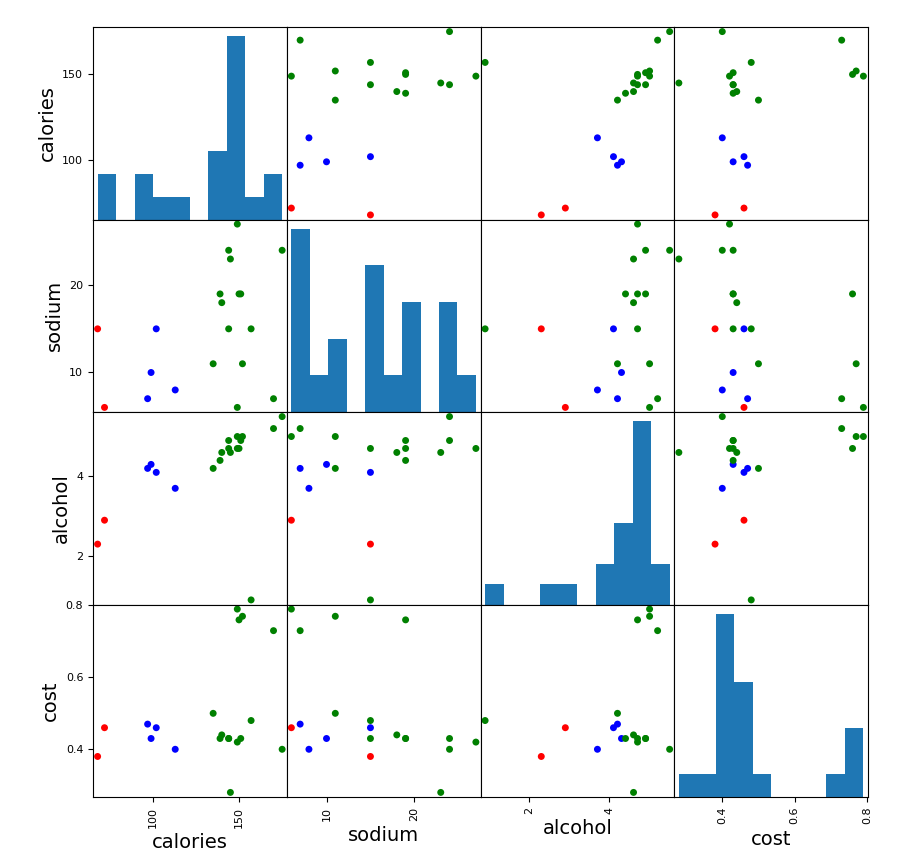

从图中可以看出,簇为三的效果更好一些。
下面我们对数据进行预处理,一般情况下我们都会对数据先做处理,因为这里数据量太小,所以数据预处理之前和处理之后的效果可能不明显,但是我们还是走一遍过程演示一下。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(features)
这里我们将数据归一化,基本数据都在-1到1之间,我们看看部分数据的效果:
下面我们也看看他归一化后的簇:
km1 = KMeans(n_clusters=3)
clf1 = km1.fit(features)
beer['scaled_cluster'] = clf1.labels_
sort_res = beer.sort_values('scaled_cluster')
print(sort_res)
如下:
下面我们看看归一化后的每个簇的聚类中心:
group_res3 = beer.groupby('scaled_cluster').mean()
print(group_res3)
结果如下:
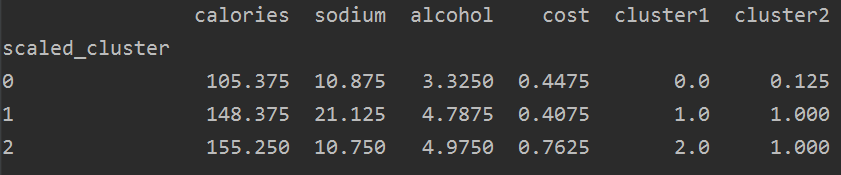
注意:有些特征本来就比较重要,而有些特征本来就不重要,所以归一化的效果不是一定很好的,假如特征本来就没有用,即使做了数据预处理效果也不会有提升的。
下面看看画图代码(两个代码效果一样):
scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']],
s=100, alpha=1, c=colors[beer['scaled_cluster']], figsize=(10, 10))
# scatter_matrix(features,
# s=100, alpha=1, c=colors[beer.scaled_cluster], figsize=(10, 10))
结果如下:
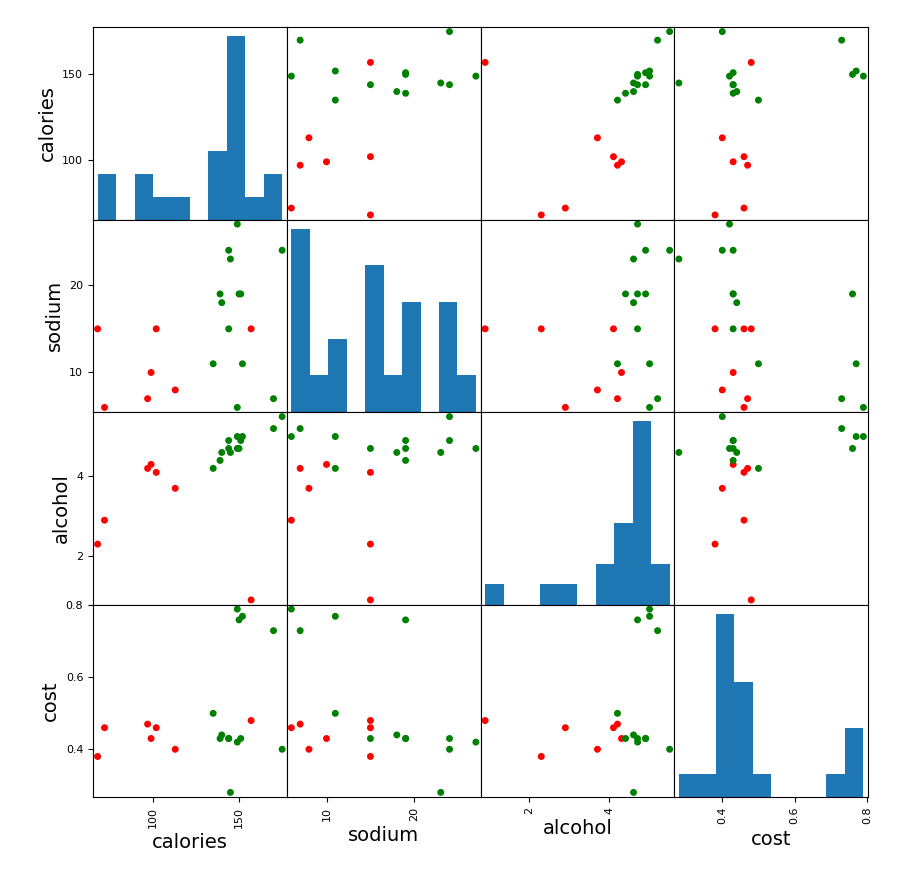
我们聚类做完了,那么如何评估那个参数的效果好呢?上面也提到了聚类的评估方法:轮廓系数。轮廓系数在sklearn中也有。
下面看看评估系数的代码:
score_scaled = metrics.silhouette_score(features, beer.scaled_cluster)
score1 = metrics.silhouette_score(features, beer.cluster1)
score2 = metrics.silhouette_score(features, beer.cluster2)
print(score_scaled, score1, score2)
结果如下:
0.45777415910909475 0.45777415910909475 0.33071506469818307
我们可以看到,做归一化,和不做归一化的效果一样,而且分为3簇效果比分为2簇的效果更好。
我们还可以调参,看看n_clusters为几的时候,效果最好。
下面我们可以看看不归一化数据,我们的簇选择从2到20,调参看看结果:
scores = []
for k in range(2, 20):
clf = KMeans(n_clusters=k).fit(features)
lables = clf.labels_
score = metrics.silhouette_score(features, lables)
scores.append(score)
print(scores)
结果如下:
[0.33071506469818307, 0.45777415910909475, 0.47546412252215964, 0.44406582701642483, 0.3653901114020658, 0.3390763170371786, 0.29766539203489123, 0.2935513325548086, 0.26720480054972856, 0.25495898824119195, 0.2681342271735249, 0.2580624498560809, 0.19510367184524083, 0.1839776940060746, 0.12332923155351708, 0.13272517919240542, 0.09795391063666276, 0.053572348458556004]
我们画图展示:
plt.plot(list(range(2, 20)), scores)
plt.xlabel('Number of Clusters Initialized')
plt.ylabel('Sihouette Score')
结果如下:
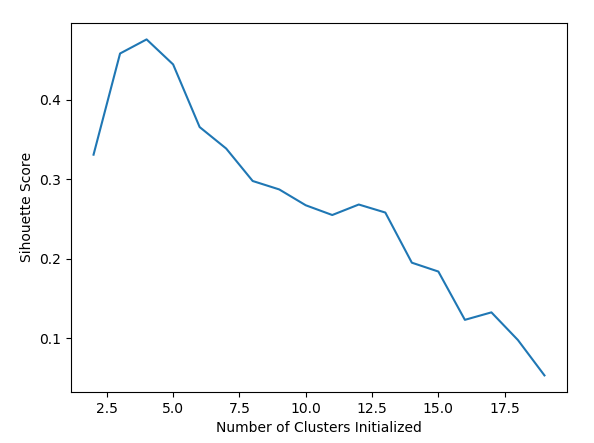
从图中,显而易见可以看出其效果。我们也直接能得出clusters的最佳值。
下面看看DBSCAN 聚类。
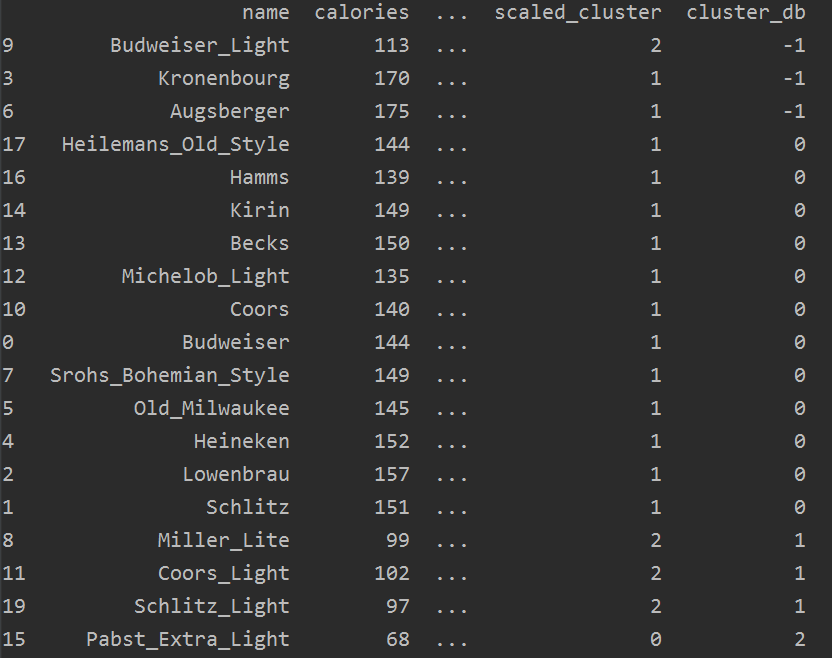
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=10, min_samples=2).fit(features)
labels = db.labels_
beer['cluster_db'] = labels
sort_res = beer.sort_values('cluster_db')
print(sort_res)
结果如下(上图是未归一化的数据的分类效果,下图是归一化的数据的分类效果):
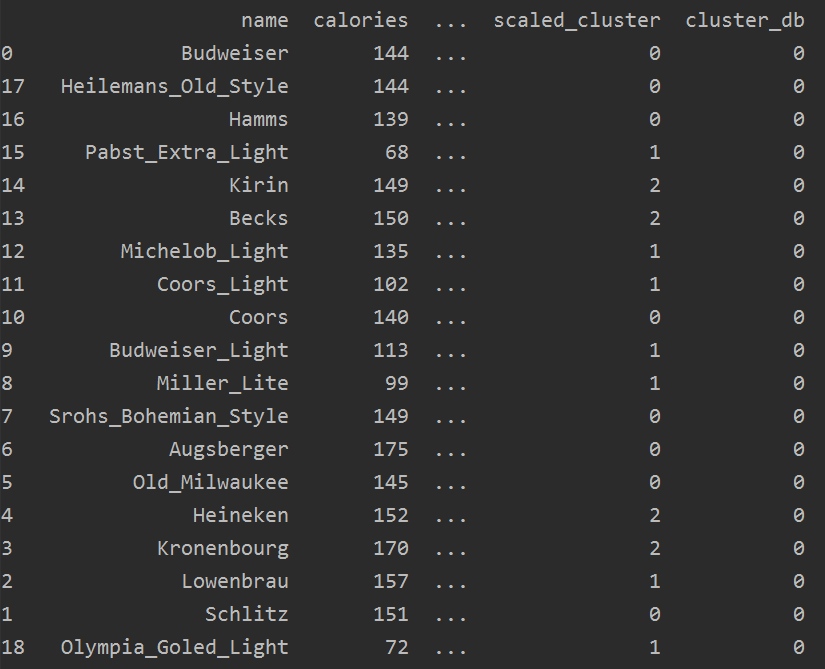
我们看看其均值:
group_res = beer.groupby('cluster_db').mean()
print(group_res)
结果如下:
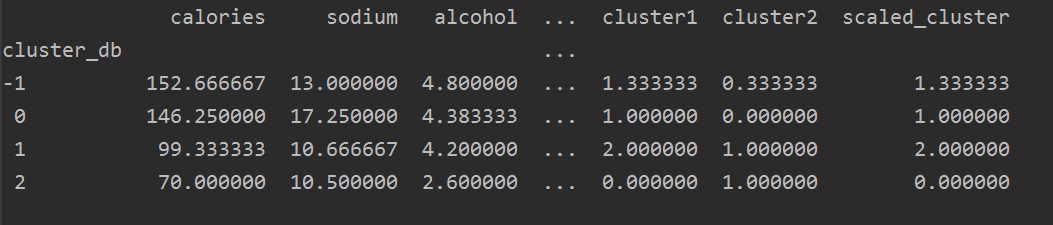
画图,对特征两两比较,代码如下:
plt.rcParams['font.size'] = 14
colors = np.array(['red', 'green', 'blue', 'yellow'])
scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']],
s=100, alpha=1, c=colors[beer['cluster_db']], figsize=(10, 10))
图如下:
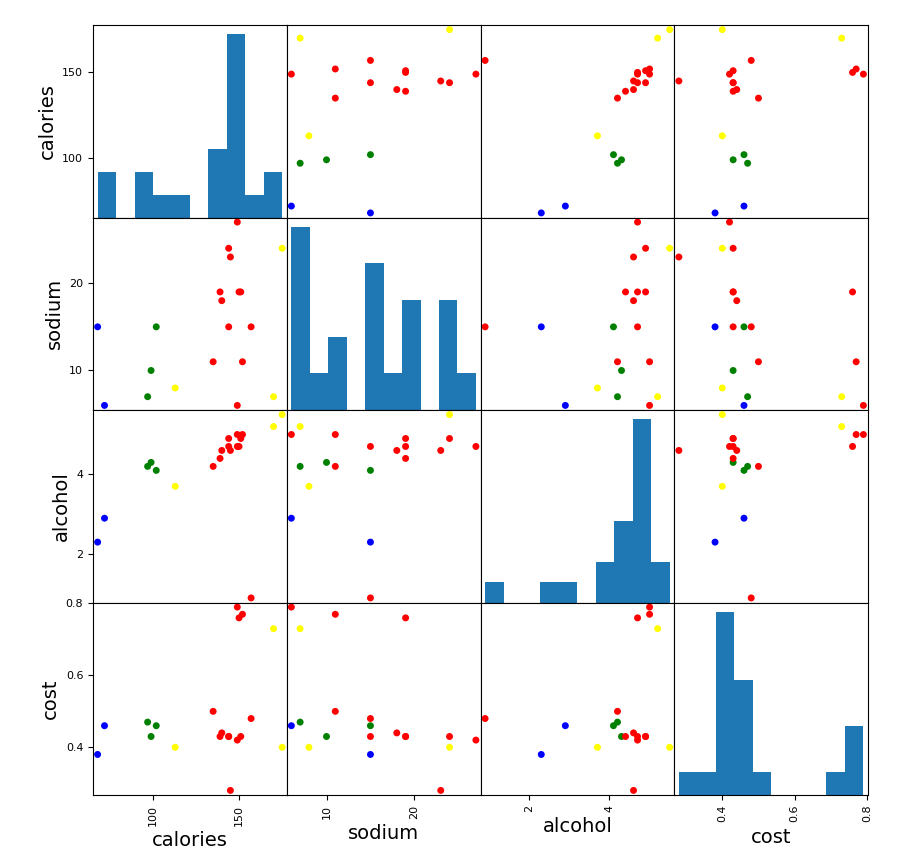
下面使用归一化后的数据,看看图效果:
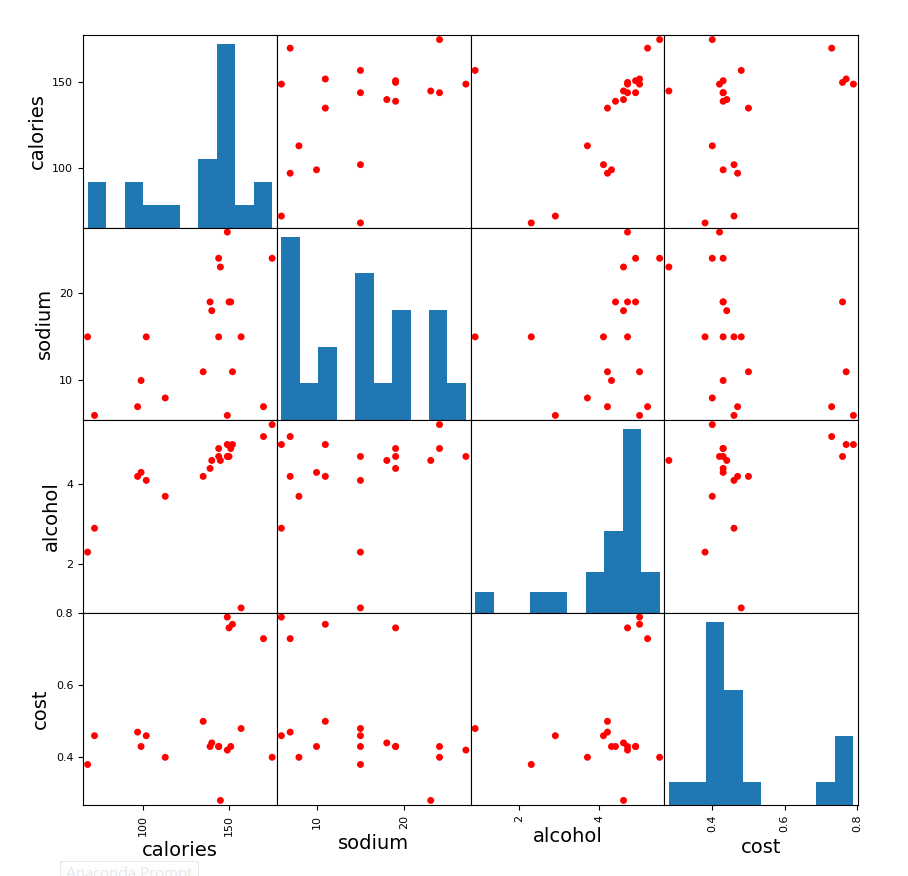
很明显归一化后的效果不好。
既然归一化的效果不好,所以我们只需要评估未归一化的训练结果,下面使用轮廓稀疏进行评估:
score1 = metrics.silhouette_score(features, beer.cluster_db)
print(score1)
# 0.49530955296776086
效果还可以,下面我们可以和K-Means一样,调参选择最佳参数。
这里我们固定一个参数,调另一个参数,当然也可以两两组合,只不过稍占内存。
scores = []
for k in range(5, 10, 1):
clf = DBSCAN(eps=10, min_samples=k).fit(features)
lables = clf.labels_
score = metrics.silhouette_score(features, lables)
scores.append(score)
print(scores)
# [0.4767963143919395, 0.4767963143919395, 0.390839395721598, 0.390839395721598, 0.21891774205673578]
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误://github.com/LeBron-Jian/MachineLearningNote
可视化工具://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
PS:这个是参考学习刘建平老师的博客,做了笔记,目的是学习K-Means算法和DBSCAN算法。
参考文献:
//www.cnblogs.com/pinard/p/6217852.html
//www.cnblogs.com/pinard/p/6208966.html
//www.cnblogs.com/pinard/p/6169370.html
//www.cnblogs.com/pinard/p/6164214.html
//blog.csdn.net/sinat_30353259/article/details/80887779