浅谈图数据库
- 2020 年 4 月 1 日
- 筆記

本文主要讨论图数据库背后的设计思路、原理还有一些适用的场景,以及在生产环境中使用图数据库的具体案例。
从社交网络谈起
下面这张图是一个社交网络场景,每个用户可以发微博、分享微博或评论他人的微博。这些都是最基本的增删改查,也是大多数研发人员对数据库做的常见操作。而在研发人员的日常工作中除了要把用户的基本信息录入数据库外,还需找到与该用户相关联的信息,方便去对单个的用户进行下一步的分析,比如说:我们发现张三的账户里有很多关于 AI 和音乐的内容,那么我们可以据此推测出他可能是一名程序员,从而推送他可能感兴趣的内容。
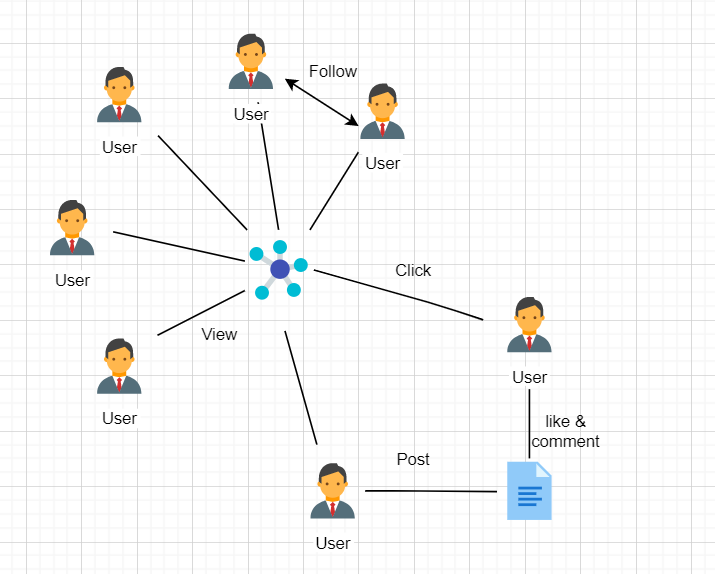
这些数据分析每时每刻都会发生,但有时候,一个简单的数据工作流在实现的时候可能会变得相当复杂,此外数据库性能也会随着数据量的增加而锐减,比如说获取某管理者下属三级汇报关系的员工,这种统计查询在现在的数据分析中是一种常见的操作,而这种操作往往会因为数据库选型导致性能产生巨大差异。
传统数据库的解决思路
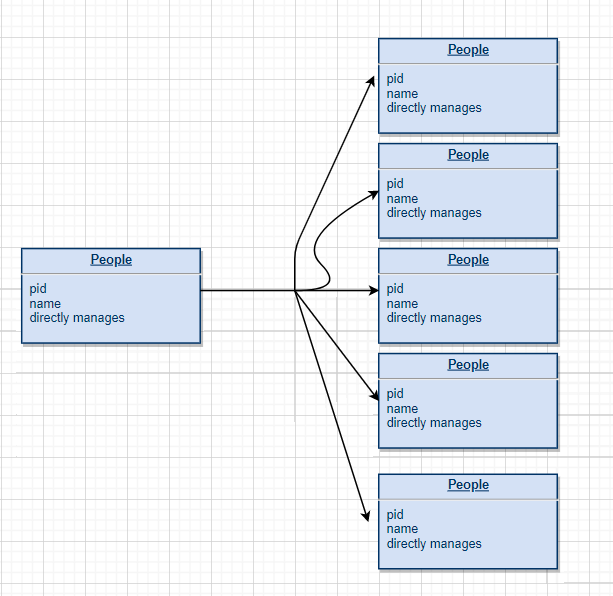
传统数据库的概念模型及查询的代码
传统解决上述问题最简单的方法就是建立一个关系模型,我们可以把每个员工的信息录入表中,存在诸如 MySQL 之类的关系数据库,下图是最基本的关系模型:
但是基于上述的关系模型,要实现我们的需求,就不可避免地涉及到很多关系数据库 JOIN 操作,同时实现出来的查询语句也会变得相当长(有时达到上百行):
(SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM ( SELECT manager.pid AS directReportees, 0 AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") UNION SELECT manager.pid AS directReportees, count(manager.directly_manages) AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT manager.pid AS directReportees, count(reportee.directly_manages) AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT manager.pid AS directReportees, count(L2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM ( SELECT manager.directly_manages AS directReportees, 0 AS count FROM person_reportee manager WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") UNION SELECT reportee.pid AS directReportees, count(reportee.directly_manages) AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT depth1Reportees.pid AS directReportees, count(depth2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT T.directReportees AS directReportees, sum(T.count) AS count FROM( SELECT reportee.directly_manages AS directReportees, 0 AS count FROM person_reportee manager JOIN person_reportee reportee ON manager.directly_manages = reportee.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees UNION SELECT L2Reportees.pid AS directReportees, count(L2Reportees.directly_manages) AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") GROUP BY directReportees ) AS T GROUP BY directReportees) UNION (SELECT L2Reportees.directly_manages AS directReportees, 0 AS count FROM person_reportee manager JOIN person_reportee L1Reportees ON manager.directly_manages = L1Reportees.pid JOIN person_reportee L2Reportees ON L1Reportees.directly_manages = L2Reportees.pid WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName") ) 这种 glue 代码对维护人员和开发者来说就是一场灾难,没有人想写或者去调试这种代码,此外,这类代码往往伴随着严重的性能问题,这个在之后会详细讨论。
传统关系数据库的性能问题
性能问题的本质在于数据分析面临的数据量,假如只查询几十个节点或者更少的内容,这种操作是完全不需要考虑数据库性能优化的,但当节点数据从几百个变成几百万个甚至几千万个后,数据库性能就成为了整个产品设计的过程中最需考虑的因素之一。
随着节点的增多,用户跟用户间的关系,用户和产品间的关系,或者产品和产品间的关系都会呈指数增长。
以下是一些公开的数据,可以反映数据、数据和数据间关系的一些实际情况:
- 推特:用户量为 5 亿,用户之间存在关注、点赞关系
- 亚马逊:用户量 1.2 亿,用户和产品间存在购买关系
- AT&T(美国三大运营商之一): 1 亿个号码,电话号码间可建立通话关系
如下表所示,开源的图数据集往往有着上千万个节点和上亿的边的数据:
| Data set name | nodes | edges |
|---|---|---|
| YahooWeb | 1.4 Billion | 6 Billion |
| Symantec Machine-File Graph | 1 Billion | 37 Billion |
| 104 Million | 3.7 Billion | |
| Phone call network | 30 Million | 260 Million |
在数据量这么大的场景中,使用传统 SQL 会产生很大的性能问题,原因主要有两个:
- 大量 JOIN 操作带来的开销:之前的查询语句使用了大量的 JOIN 操作来找到需要的结果。而大量的 JOIN 操作在数据量很大时会有巨大的性能损失,因为数据本身是被存放在指定的地方,查询本身只需要用到部分数据,但是 JOIN 操作本身会遍历整个数据库,这样就会导致查询效率低到让人无法接受。
- 反向查询带来的开销:查询单个经理的下属不需要多少开销,但是如果我们要去反向查询一个员工的老板,使用表结构,开销就会变得非常大。表结构设计得不合理,会对后续的分析、推荐系统产生性能上的影响。比如,当关系从_老板 -> 员工 _变成 用户 -> 产品,如果不支持反向查询,推荐系统的实时性就会大打折扣,进而带来经济损失。
下表列出的是一个非官方的性能测试(社交网络测试集,一百万用户,每个大概有 50 个好友),体现了在关系数据库里,随着好友查询深度的增加而产生的性能变化:
| levels | RDBMS execution time(s) |
|---|---|
| 2 | 0.016 |
| 3 | 30.267 |
| 4 | 1543.595 |
传统数据库的常规优化策略
策略一:索引
索引:SQL 引擎通过索引来找到对应的数据。
常见的索引包括 B- 树索引和哈希索引,建立表的索引是比较常规的优化 SQL 性能的操作。B- 树索引简单地来说就是给每个人一个可排序的独立 ID,B- 树本身是一个平衡多叉搜索树,这个树会将每个元素按照索引 ID 进行排序,从而支持范围查找,范围查找的复杂度是 O(logN) ,其中 N 是索引的文件数目。
但是索引并不能解决所有的问题,如果文件更新频繁或者有很多重复的元素,就会导致很大的空间损耗,此外索引的 IO 消耗也值得考虑,索引 IO 尤其是在机械硬盘上的 IO 读写性能上来说非常不理想,常规的 B- 树索引消耗四次 IO 随机读,当 JOIN 操作变得越来越多时,硬盘查找更可能发生上百次。
策略二:缓存
缓存:缓存主要是为了解决有具有空间或者时间局域性数据的频繁读取带来的性能优化问题。一个比较常见的使用缓存的架构是 lookaside cache architecture。下图是之前 Facebook 用 Memcached + MySQL 的实例(现已被 Facebook 自研的图数据库 TAO 替代):
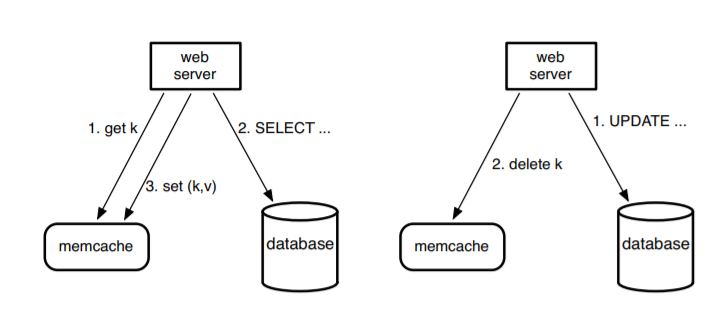
在架构中,设计者假设用户创造的内容比用户读取的内容要少得多,Memcached 可以简单地理解成一个分布式的支持增删改查的哈希表,支持上亿量级的用户请求。基本的使用流程是当客户端需读数据时,先查看一下缓存,然后再去查询 SQL 数据库。而当用户需要写入数据时,客户端先删除缓存中的 key,让数据过期,再去更新数据库。但是这种架构有几个问题:
- 首先,键值缓存对于图结构数据并不是一个好的操作语句,每次查询一条边,需要从缓存里把节点对应的边全部拿出来;此外,当更新一条边,原来的所有依赖边要被删除,继而需要重新加载所有对应边的数据,这些都是并发的性能瓶颈,毕竟实际场景中一个点往往伴随着几千条边,这种操作带来的时间、内存消耗问题不可忽视。
- 其次,数据更新到数据读取有一个过程,在上面架构中这个过程需要主从数据库跨域通信。原始模型使用了一个外部标识来记录过期的键值对,并且异步地把这些读取的请求从只读的从节点传递到主节点,这个需要跨域通信,延迟相比直接从本地读大了很多。(类似从之前需要走几百米的距离而现在需要走从北京到深圳的距离)
使用图结构建模
上述关系型数据库建模失败的主要原因在于数据间缺乏内在的关联性,针对这类问题,更好的建模方式是使用图结构。
假如数据本身就是表格的结构,关系数据库就可以解决问题,但如果你要展示的是数据与数据间的关系,关系数据库反而不能解决问题了,这主要是在查询的过程中不可避免的大量 JOIN 操作导致的,而每次 JOIN 操作却只用到部分数据,既然反复 JOIN 操作本身会导致大量的性能损失,如何建模才能更好的解决问题呢?答案在点和点之间的关系上。
点、关联关系和图数据模型
在我们之前的讨论中,传统数据库虽然运用 JOIN 操作把不同的表链接了起来,从而隐式地表达了数据之间的关系,但是当我们要通过 A 管理 B,B 管理 A 的方式查询结果时,表结构并不能直接告诉我们结果。
如果我们想在做查询前就知道对应的查询结果,我们必须先定义节点和关系。
节点和关系先定义是图数据库和别的数据库的核心区别。打个比方,我们可以把经理、员工表示成不同的节点,并用一条边来代表他们之前存在的管理关系,或者把用户和商品看作节点,用购买关系建模等等。而当我们需要新的节点和关系时,只需进行几次更新就好,而不用去改变表的结构或者去迁移数据。
根据节点和关联关系,之前的数据可以根据下图所示建模:
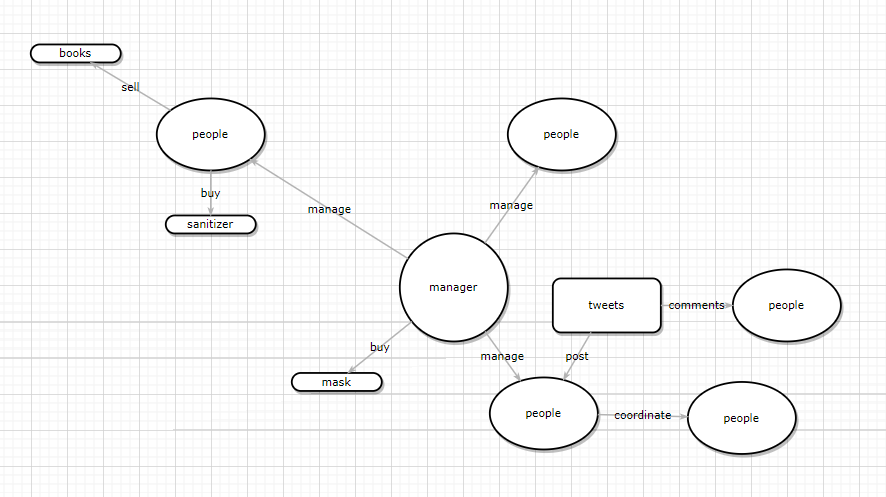
通过图数据库 Nebula Graph 原生 nGQL 图查询语言进行建模,参考如下操作:
-- Insert People INSERT VERTEX person(ID, name) VALUES 1:(2020031601, ‘Jeff’); INSERT VERTEX person(ID, name) VALUES 2:(2020031602, ‘A’); INSERT VERTEX person(ID, name) VALUES 3:(2020031603, ‘B’); INSERT VERTEX person(ID, name) VALUES 4:(2020031604, ‘C’); -- Insert edge INSERT EDGE manage (level_s, level_end) VALUES 1 -> 2: ('0', '1') INSERT EDGE manage (level_s, level_end) VALUES 1 -> 3: ('0', '1') INSERT EDGE manage (level_s, level_end) VALUES 1 -> 4: ('0', '1') 而之前超长的 query 语句也可以通过 Cypher / nGQL 缩减成短短的 3、4 行代码。
下面为 nGQL 语句
GO FROM 1 OVER manage YIELD manage.level_s as start_level, manage._dst AS personid | GO FROM $personid OVER manage where manage.level_s < start_level + 3 YIELD SUM($$.person.id) AS TOTAL, $$.person.name AS list 下面为 Cypher 版本
MATCH (boss)-[:MANAGES*0..3]->(sub), (sub)-[:MANAGES*1..3]->(personid) WHERE boss.name = “Jeff” RETURN sub.name AS list, count(personid) AS Total 从近百行代码变成 3、4 行代码可以明显地看出图数据库在数据表达能力上的优势。
图数据库性能优化
图数据库本身对高度连接、结构性不强的数据做了专门优化。不同的图数据库根据不同的场景也做了针对性优化,笔者在这里简单介绍以下几种图数据库,BTW,这些图数据库都支持原生图建模。
Neo4j
Neo4j 是最知名的一种图数据库,在业界有微软、ebay 在用 Neo4j 来解决部分业务场景,Neo4j 的性能优化有两点,一个是原生图数据处理上的优化,一个是运用了 LRU-K 缓存来缓存数据。
原生图数据处理优化
我们说一个图数据库支持原生图数据处理就代表这个数据库有能力去支持 index-free adjacency。
index-free adjancency 就是每个节点会保留连接节点的引用,从而这个节点本身就是连接节点的一个索引,这种操作的性能比使用全局索引好很多,同时假如我们根据图来进行查询,这种查询是与整个图的大小无关的,只与查询节点关联边的数目有关,如果用 B 树索引进行查询的复杂度是 O(logN),使用这种结构查询的复杂度就是 O(1)。当我们要查询多层数据时,查询所需要的时间也不会随着数据集的变大而呈现指数增长,反而会是一个比较稳定的常数,毕竟每次查询只会根据对应的节点找到连接的边而不会去遍历所有的节点。
主存缓存优化
在 2.2 版本的 Neo4j 中使用了 LRU-K 缓存,这种缓存简而言之就是将使用频率最低的页面从缓存中弹出,青睐使用频率更高的页面,这种设计保证在统计意义上的缓存资源使用最优化。
JanusGraph
JanusGraph 本身并没有关注于去实现存储和分析,而是实现了图数据库引擎与多种索引和存储引擎的接口,利用这些接口来实现数据和存储和索引。JanusGraph 主要目的是在原来框架的基础上支持图数据的建模同时优化图数据序列化、图数据建模、图数据执行相关的细节。JanusGraph 提供了模块化的数据持久化、数据索引和客户端的接口,从而更方便地将图数据模型运用到实际开发中。
此外,JanusGraph 支持用 Cassandra、HBase、BerkelyDB 作为存储引擎,支持使用 ElasticSearch、Solr 还有 Lucene 进行数据索引。
在应用方面,可以用两种方式与 JanusGraph 进行交互:
- 将 JanusGraph 变成应用的一部分进行查询、缓存,并且这些数据交互都是在同一台 JVM 上执行,但数据的来源可能在本地或者在别的地方。
- 将 JanusGraph 作为一个服务,让客户端与服务端分离,同时客户端提交 Gremlin 查询语句到服务器上执行对应的数据处理操作。
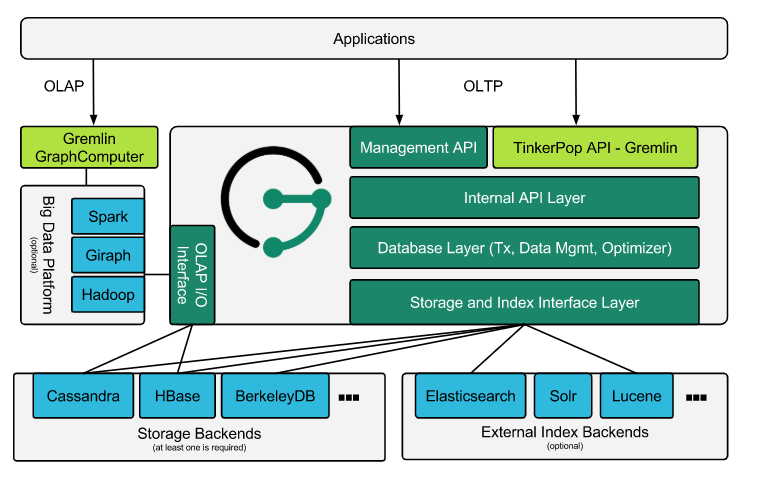
Nebula Graph
下面简单地介绍了一下 Nebula Graph 的系统设计。
使用 KV 对来进行图数据处理
Nebula Graph 使用了 vertexID + TagID 作为键在不同的 partition 间存储 in-key 和 out-key 相关的数据,这种操作可以确保在大规模集群上的高可用,使用分布式的 partition 和 sharding 也增加了 Nebula Graph 的吞吐量和容错的能力。
Shared-noting 分布式存储层
Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。Nebula 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxo 更简洁,我们选用了 Raft)。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
图数据(点和边)通过 Hash 的方式存储在不同 partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 partition 数。在 Nebula Graph 中,partition 表示一个虚拟的数据集,这些 partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
无状态计算层
每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡(balance),第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
图数据库是当今的趋势
在当今,图数据库收到了更多分析师和咨询公司的关注
Graph analysis is possibly the single most effective competitive differentiator for organizations pursuing data-driven operations and decisions after the design of data capture. ————–Gartner
“Graph analysis is the true killer app for Big Data.” ——————–Forrester
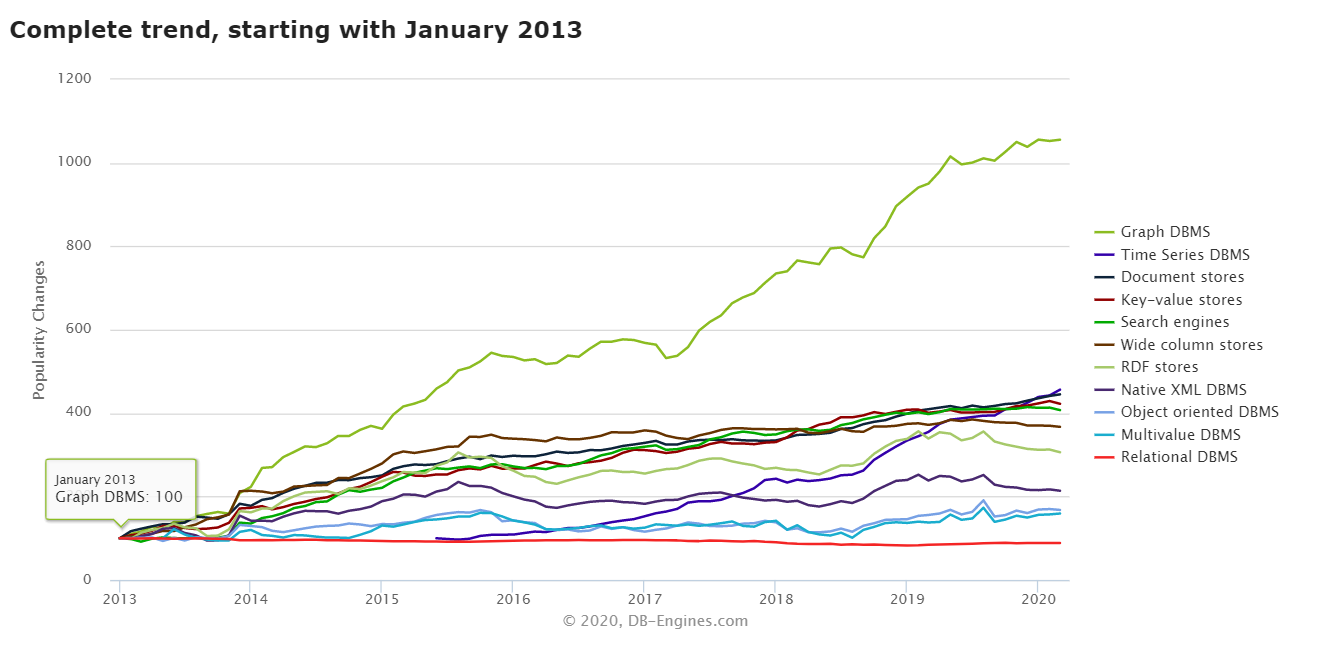
同时图数据库在 DB-Ranking 上的排名也呈现出上升最快的趋势,可见需求之迫切:
图数据库实践:不仅仅是社交网络
Netflix 云数据库的工程实践
Netflix 采用了JanusGraph + Cassandra + ElasticSearch 作为自身的图数据库架构,他们运用这种架构来做数字资产管理。
节点表示数字产品比如电影、纪录片等,同时这些产品之间的关系就是节点间的边。
当前的 Netflix 有大概 2 亿的节点,70 多种数字产品,每分钟都有上百条的 query 和数据更新。
此外,Netflix 也把图数据库运用在了授权、分布式追踪、可视化工作流上。比如可视化 Git 的 commit,jenkins 部署这些工作。
Adobe 的技术迭代
一般而言,新技术往往在开始的时候大都不被大公司所青睐,图数据库并没有例外,大公司本身有很多的遗留项目,而这些项目本身的用户体量和使用需求又让这些公司不敢冒着风险来使用新技术去改变这些处于稳定的产品。Adobe 在这里做了一个迭代新技术的例子,用 Neo4j 图数据库替换了旧的 NoSQL Cassandra 数据库。
这个被大改的系统名字叫 Behance,是 Adobe 在 15 年发布的一个内容社交平台,有大概 1 千万的用户,在这里人们可以分享自己的创作给百万人看。
这样一个巨大的遗留系统本来是通过 Cassandra 和 MongoDB 搭建的,基于历史遗留问题,系统有不少的性能瓶颈不得不解决。
MongoDB 和 Cassandra 的读取性能慢主要因为原先的系统设计采用了 fan-out 的设计模式——受关注多的用户发表的内容会单独分发给每个读者,这种设计模式也导致了网络架构的大延迟,此外 Cassandra 本身的运维也需要不小的技术团队,这也是一个很大的问题。
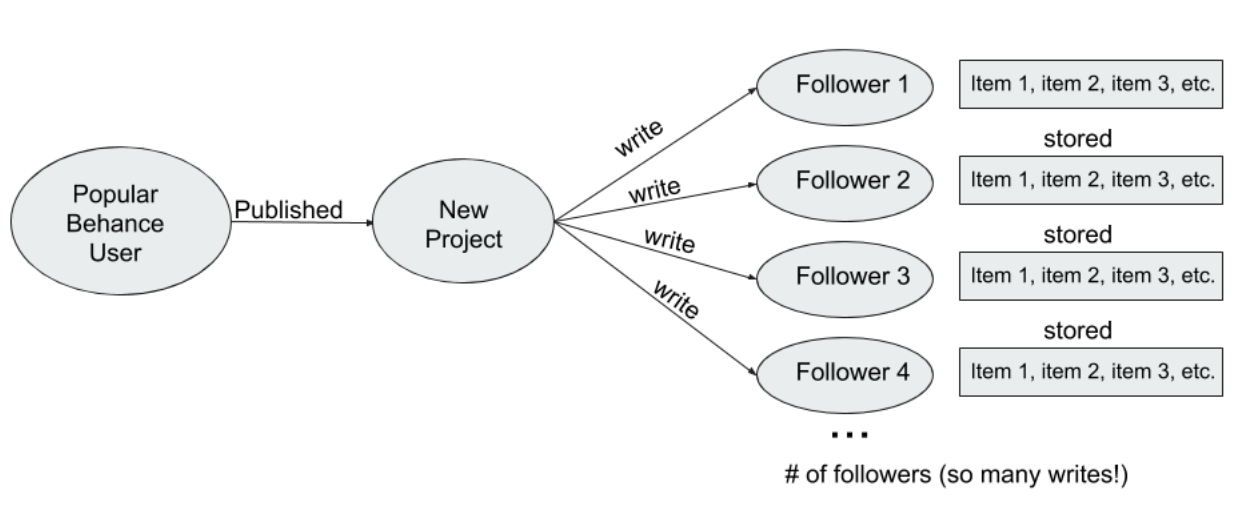
在这里为了搭建一个灵活、高效、稳定的系统来提供消息 feeding 并最小化数据存储的规模,Adobe 决定迁移原本的 Cassandra 数据库到 Neo4j 图数据库。
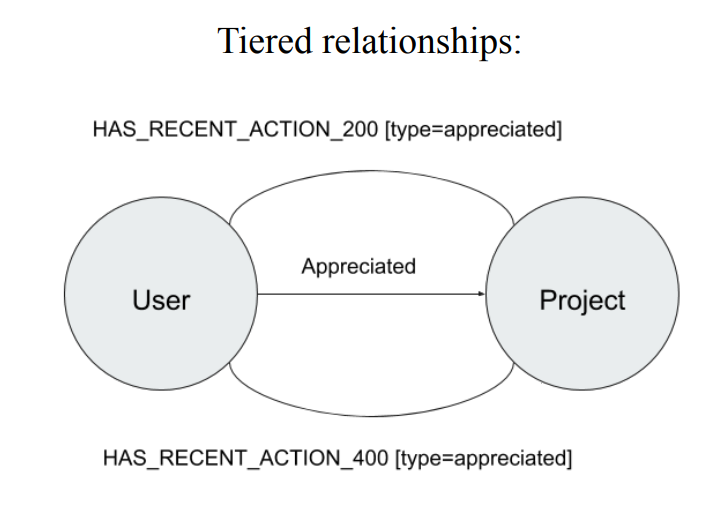
在 Neo4j 图数据库中采用一种所谓的 Tiered relationships 来表示用户之间的关系,这个边的关系可以去定义不同的访问状态,比如:仅部分用户可见,仅关注者可见这些基本操作。
数据模型如图所示
使用这种数据模型并使用 Leader-follower 架构来优化读写,这个平台获得了巨大的性能提升:
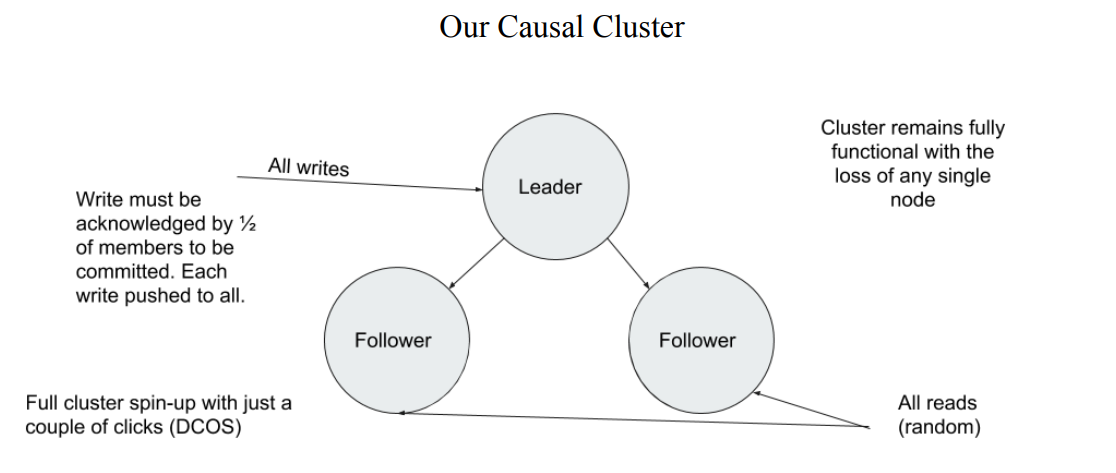
- 运维需求的时长在使用了 Neo4j 以后下降了 300%。
- 存储需求降低了 1000 倍, Neo4j 仅需 50G 存储数据, 而 Cassandra 需要 50TB。
- 仅仅需要 3 个服务实例就可以支持整个服务器的流畅运行,之前则需要 48 个。
- 图数据库本身就提供了更高的可扩展性。
结论
在当今的大数据时代,采用图数据库可以用小成本在原有架构上获得巨大的性能提升。图数据库不仅仅可以在 5G、AI、物联网领域发挥巨大的推动作用,同时也可以用来重构原本的遗留系统。
虽然不同的图数据库可能有着截然不同的底层实现,但这些都完全支持用图的方式来构建数据模型从而让不同的组件之间相互联系,从我们之前的讨论来看,这一种数据模型层次的改变会极大地简化很多日常数据系统中所面临的问题,增大系统的吞吐量并且降低运维的需求。
图数据库的介绍就到此为止了,如果你对图数据库 Nebula Graph 有任何想法或其他要求,欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.io/ 的 Feedback 分类下提建议 ?;加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot
Reference
- [1] An Overview Of Neo4j And The Property Graph Model Berkeley, CS294, Nov 2015 https://people.eecs.berkeley.edu/~istoica/classes/cs294/15/notes/21-neo4j.pdf
- [2] several original data sources from talk made by Duen Horng (Polo) Chau ( Geogia tech ) www.selectscience.net www.phonedog.com、www.mediabistro.com www.practicalecommerce.com/
- [3] Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo) Chau(Georgia tech)
- [4] Graph databases, 2nd Edition: New Oppotunities for Connected Data
- [5] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C.Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook.In Proceedings of the 10th USENIX conference on Networked
Systems Design and Implementation, NSDI, 2013. - [6] Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov Dmitri Petrov, Lovro Puzar, Yee Jiun Song, Venkat Venkataramani TAO: Facebook’s Distributed Data Store for the Social Graph USENIX 2013
- [7] Janus Graph Architecture https://docs.janusgraph.org/getting-started/architecture/
- [8] Nebula Graph Architecture — A Bird’s View https://nebula-graph.io/en/posts/nebula-graph-architecture-overview/
- [9] database engine trending https://db-engines.com/en/ranking_categories
- [10] Netflix Content Data Management talk https://www.slideshare.net/RoopaTangirala/polyglot-persistence-netflix-cde-meetup-90955706#86
- [11] Harnessing the Power of Neo4j for Overhauling Legacy Systems at Adobe https://neo4j.com/graphconnect-2018/session/overhauling-legacy-systems-adobe
推荐阅读
作者有话说:Hi,我是 Johhan。目前在 Nebula Graph 实习,研究和实现大型图数据库查询引擎和存储引擎组件。作为一个图数据库及开源爱好者,我在博客分享有关数据库、分布式系统和 AI 公开可用学习资源。