操作系统学习笔记7 | 进程同步与合作
多进程图像除了需要实现切换,还需要处理进程之间的相互影响。本部分介绍进程之间的合作如何变得合理有序。将要涉及信号量、临界区、死锁等经典概念的理解。
参考资料:
-
课程:哈工大操作系统(本部分对应 L16 && L17 && L18 && L19)
-
感觉这部分理解的还是不够深入,需要多复习这部分,在实验五中体会体会。
1. 进程同步与信号量
总的来说,操作系统通过 !信号量! 实现进程同步
1.1 案例引入
两个进程如果需要共同完成一个任务(即进程合作),需要信号来沟通。正如司机需要等待售票员关门后发出信号才可启动车辆。
等待是进程同步的核心,进程同步的基本结构如下:
- 进程A执行到某个环节时,发现某个条件不符合,则不继续向下执行,而是停下来等待;
- 直到进程B运行到一定程度后产生这个条件,向进程A发送信号,进程A继续向下执行。

如上图所示,生活中信号的例子有很多,那么要说的信号量是什么?(从信号到信号量)
发明信号量的迪杰斯特拉因此拿了图灵奖。此外他还发明了进程调度中非常著名的多级反馈队列算法。
- 前面笔记中提到过生产者-消费者实例,我们继续以此为例。

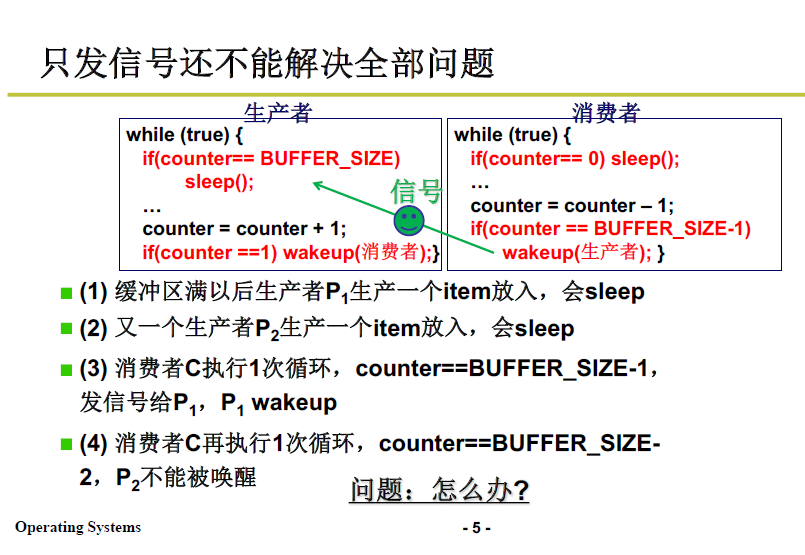
这是一个典型的多进程合作的程序典例,生产者在缓冲区满的时候就不应该继续像缓冲区输入了,所以通过while(counter==BUFFER_SIZE); 进行阻塞,生产者进程开始等待
直到消费者进程运行至缓冲区有空余,生产者才继续执行;同理缓冲区空了,消费者要等待缓冲区中有内容才能继续:
多进程的合作合理有序的关键就是要判断那些地方停(阻塞),哪些地方走(执行)。通过走走停停实现合作有序。

1.2 信号到信号量
然而,上文介绍的信号,其本身的信息量还不能解决全部问题。
-
如果是一个消费者两个生产者的情况:
- 如下图,所有消费者生产者共用一个缓冲区,缓冲区已满;
- 生产者1 生产了一个item,但由于 缓冲区已满
counter == BUFFER_SIZE,所以进入休眠sleep() - 由于缓冲区是公共的,此时如果再来一个生产者2,生产一个item,
counter == BUFFER_SIZE,生产者2也进入休眠 - 由于counter ≠ 0,消费者持续进行,counter-1,这时应当唤醒生产者:
wakeup();这时唤醒了一个生产者1; - 消费者持续循环,此时 counter == BUFFER_SIZE-2,不触发唤醒条件,因此生产者2持续 sleep
补充一个 while 引起的等待 跟 锁 之间的联系:
- while并不一定就是自旋锁,自旋锁要看while内部的代码怎么写,如果内部有调度那就是无等待锁,如果内部没有调度那就是忙锁,也就是自旋锁
- 使用while不会释放对cpu的所有权所以叫自旋,阻塞会释放对cpu的所有权
- 使用while不会释放对cpu的所有权所以叫自旋,阻塞会释放对cpu的所有权
-
这样问题就是 生产者2 永远休眠。
-
-
此处举例也并没有复杂到多个生产者与多个消费者,所以仅用 counter 来进行语义判断是不够的,我们需要再用一个量记录有几个生产者进程在休眠。
如果我们能够记录有两个生产者进程在休眠,消费者进程运行至符合要求时,就可以根据该信息的提醒唤醒两个进程,而不产生遗漏。
-
信号量:能够记录一些信息,并根据信息决定进程的休眠和运行。

下图PPT是在说信号的不足,需要引入信号量。

1.3 信号量的工作过程
-
缓冲区满,生产者1执行,生产者1休眠,赋 sem=-1;
-
生产者2执行,生产者2休眠,赋 sem=-2;
-
消费者一次循环, wakeup 生产者1,赋 sem=-1;
相当于阻塞队列,唤醒先阻塞的。这个算法也可以自己设计。
-
消费者第2次循环,wakeup 生产者2,赋 sem=0;
-
这里 sem 就是信号量,根据信号量来进行进程的等待唤醒。很显然较于counter(信号)表达了更多的信息。
-
消费者第3次循环,赋值 sem = 1;
-
生产者3 执行,sem > 0 ,表明缓冲区还有一个空位;不需要休眠,赋值 sem=0;
-
…(如果接下来还有生产者执行,则 sem <0 ,阻塞)
讲道理,视频这里的弹幕水准相当低。逻辑很简单,非要过度发挥!

1.4 信号量的定义/实现
信号量的核心理念是用量来记录必要信息,用信号来管理进程是否等待/阻塞。下面是一个具体实现。
-
信号量的定义:semaphore结构体
- 1个 int 类型的 value,用于记录资源个数(缓冲区空余);
- 1个 PCB 队列,记录等待在该信号量上的进程;
-
进程(对应上文生产者)调用 P 函数判断是否需要等待
P 的意思就是 test,等价于上面1.3 中手动赋值 sem– 并据此判断的过程
- P 函数中 value – 1,对应 上文的 sem – 1;
- 如果 value < 0,资源不够则进程 s 休眠,放入阻塞队列。
-
进程(对应上问消费者)调用 V 函数来唤醒进程;
V 的意思就是 increment,等价于上面1.3 中手动赋值 sem ++ 并据此判断的过程
-
V 的代码 应当为:
V(semaphore s) { s.value++; if (s.value <= 0) { wakeup(s.queue); } } // 或者 V(semaphore s) { if (s.value < 0) { wakeup(s.queue); } s.value++; } //注意前后加减的区别,并不难理解
-

1.5 用信号量解决生产者-消费者问题
讲到现在,我们是否能用信号量对 1.2 中分析出的 counter 的不足进行改进呢?
我们需要分析 进程 ”停“ 的含义,给出正确的信号量(0为临界):
-
生产者当缓冲区为满时,生产者停,哪一个值为0?
- 于是设计 empty 初值为 BUFFER_SIZE,当 empty 为 0 则满 ;
- 生产者进程每次进行时调用P函数测试empty:
P(empty); - 对应使 empty 增加的进程就是消费者,对应在消费者进程写:
V(empty);
-
消费者当缓冲区空时,消费者停,哪一个值为0?
- 于是设计 full 初值为 0,当 full = 0 时缓冲区空;
- 消费者进程每次进行时调用 P 函数测试 full:
P(full); - 对应使 full 增加的进程就是生产者,对应在生产者进程写:
V(full);
-
缓冲区如何定义:
-
可以是一个文件:buffer.txt
-
由于是对文件进行操作,同一时间只能一个进程进行操作(互斥)
具体我此前有过体会:即Linux环境下打开某个普通文件,再次打开(非管理员权限)时会显示只读,如果修改会有提示。
-
需要定义一个新的信号量 mutex,初值为1,当 mutex = 0 表示有进程正在修改文件/读写缓冲区;
-
这个信号量应当对生产者和消费者其同样的效用;同时在生产者消费者进程加入:
P(mutex);//将要使用缓冲区, 1->0; V(mutex);//将要释放使用权, 0->1
-

提到了实验五,可以开始做了,linux0.11没有提供信号量,需要在内核中实现信号量的系统调用
2. 信号量临界区保护
上一部分讲到 通过对信号量的访问和修改,可以实现进程的同步、有序推进,但是我们还需要对信号量进行保护。
2.1 为什么保护信号量?
上述逻辑看上去已经非常完美,哪里还有问题呢?
-
正如 学习笔记4中多进程图像实现过程需要解决的问题中的举例2,我们的信号量必须要 !正确!
如果信号量的含义不对,那么对于进程同步的指挥只会一团糟。
-
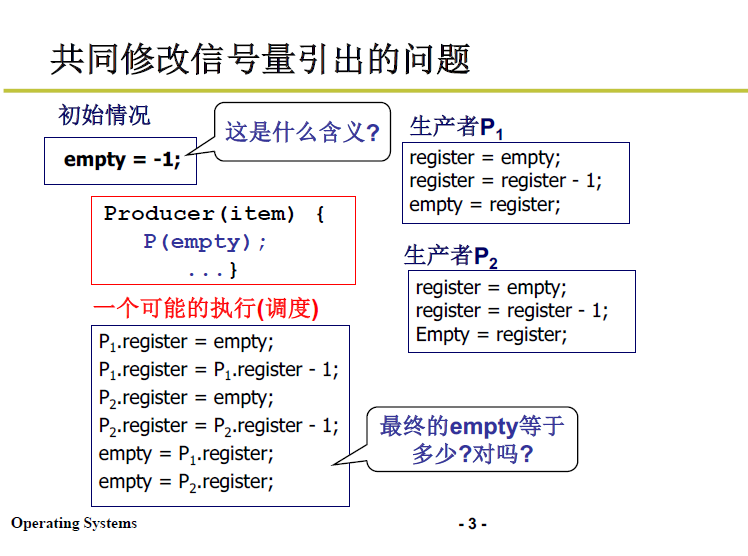
重复一下 笔记4 中提到的那个信号量可能出错的例子:
-
由于进程任务正执行时时间片用完等因素,操作系统进行了本不应该进行的 reschedule,使得多进程图像出现了错误的执行序列:
-
如下图所示;操作系统每两行进行一次切换的话:
-
empty初始值为 -1,P1执行,P1.register=-2;
-
而在第二行结束切出,P2执行,P2.register 在-1 的基础上-1 == -2;而本应该累加为 -3
这就出现了错误
-
-
这就是一种竞争条件,这种调度会让共享数据(empty)发生错误:
-
类似的,内核中的共享数据,如果不做保护,在多进程时间片轮转的调度策略下,就会出现人无法控制与预料的错误;
-
这不是一种编程错误,而是共享数据没有保护带来的语义错误。
如下图,左侧第 i 次执行会发生错误,第 j 次执行则正确。

-


2.2 解决竞争条件的直观想法
那就是给信号量上锁:
- 当进程访问信号量并准备修改信号量时,上锁阻止其他进程访问。
- 当该进程修改完信号量切换出去后,方可解锁,让其他进程进行同样操作。
这种 只能一次做完,不能做一半停下来的工作,OS中就称为 原子操作,突出一个不可分割。

2.3 临界区
!临界区! 是指:一次只允许一个进程进入的某进程的那一段代码。比如读写、修改信号量的那段代码一定是临界区。

如何标记临界区、实现临界区的预期效果呢?
- 在计算机中就是用代码来实现(进入区和退出区)
- 下面会介绍三个方法;
2.4 临界区保护原则
临界区保护的原则:
-
基本原则:互斥进入;
如果一个进程在临界区中执行,则其他进程不能进入;
-
有空让进:临界区空闲的时候,应尽快选择出一个进程进入临界区(不能所有人卡着门口,结果一个人都进不去)
-
有限等待:进程发出请求进入临界区的等待时间必须是有限的,不能出现饥饿问题(不能总是让别人进,我也要尽快进去)

2.5 临界区保护方法
2.5.1 轮换法
像值日一样,轮到进程A(turn==0),进程A就进入临界区,轮不到则使用 while(turn!=0);自旋空转;当进程A 退出临界区,则 turn=1,轮到下一个进程使用。
下面分析一下这种方法:
- 满足互斥进入,一次只能进入一个进程;
- 不满足有空让进,如果P0退出临界区,P1不进入临界区,则turn还是1,P0再度想进入临界区,就会被拒绝。但此时临界区使用者为空。
- 轮换法也不一定满足 有限等待,如果P0完成一次临界区操作后,P1在剩余区死循环,那么P0就永远进不去临界区了,产生了饥饿

2.5.2 标记法
轮换法的弊病主要在于 有空不让进,就像值日,如果看见有垃圾,但不是自己没有值日的权限,就只能视而不见。
如何改进?还有一种直观的想法。
-
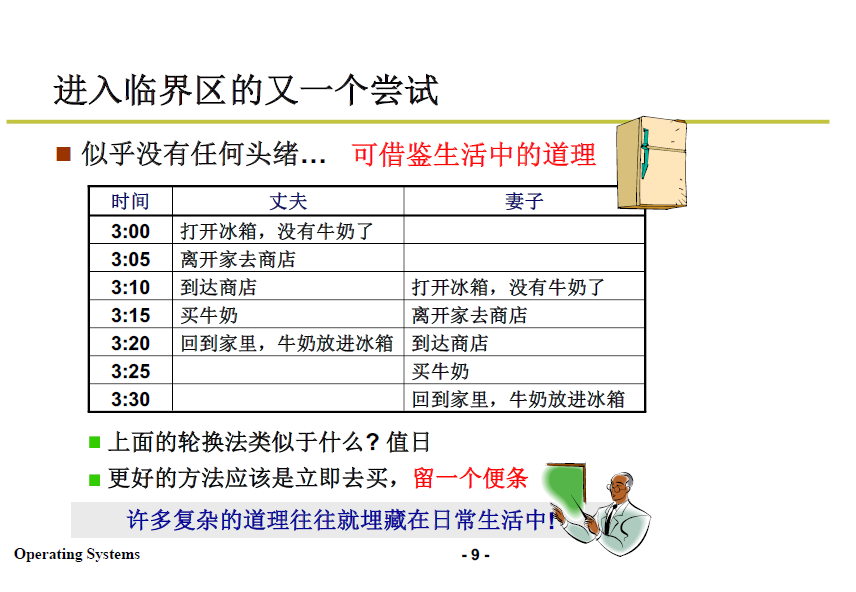
下图的例子是生活中夫妻买牛奶的情境,如果采用轮换法,如果轮换时间是10分钟,夫妻二人都会像下图一样去买牛奶,导致买多。
-
标记法就是类似于留一个便条,3:00时丈夫发现没有牛奶决定去买时,就留下便条,让妻子知道自己去买了。

标记法是如何运作的?
-
看看代码:
-
P0 要进临界区,就先标记自己,
flag[0]=true,然后判断 P1 的标记,如果 P1 已经标记,就等待;同理其他进程也是,进临界区之前先标记自己为true,然后等待别的进程的标记变为false
-
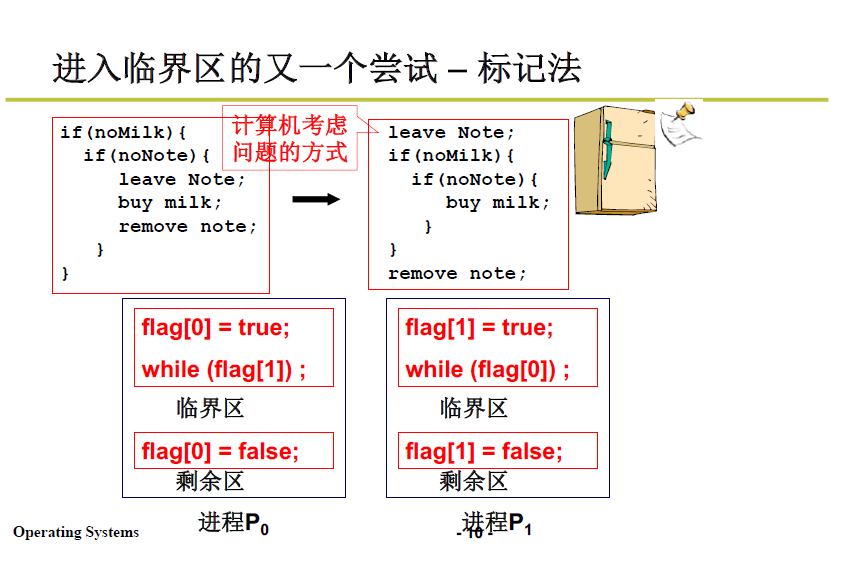

下面分析这种方法:
-
互斥性:满足,两个进程不可能同时进入临界区。
-
有空让进:也不满足,如果进程P0执行第一句, flag[0]=true,接着P1 进行第一句 flag[1]=true,再切换回P0执行while时进入自旋空转了。同理 切回 P1的while也发生自旋空转。谁也进不去临界区。
相当于在某段时间内夫妻二人都看到了没有奶,都留下了便条,又都看见彼此的便条(可能某人标记完回头看了一眼便条,发现对方留了便条),所以都没有去买。

-
有限等待:这样也不满足有限等待。
-
所以实际上,我们应当让夫妻二人有一人更勤劳–非对称标记。也就是在一个进程中做更多的考虑:
举个例子,让丈夫做更多的考虑:
当妻子看到有便条,则不必再考虑买奶;当丈夫看到有便条,等待一段时间后再查看是否有奶,如果还是没有,则更勤劳地去买奶。如下图所示:


2.5.3 Peterson算法
标记和轮转的结合。
其实轮转(值日)就是非对称标记的,在负责的时间内考虑更多的事情。尝试上面两个基本考虑结合起来。
-
依然打标记
flag[0]=true; flag[1]=true; -
加上值日/轮转,给进程P0的 turn 初值赋1;P1的 turn 初值赋0;
视频弹幕的主要问题是:不理解左右两个turn是一个变量,这么写并不冲突,只是在防止上文两者卡死的情况出现
-
达到的效果是:
- 对于进程P0,如果P1标记了,并且轮到了P1(
turn=1),则P0自旋空转,让P1进入临界区; - 当P1退出临界区,turn = 0;那么P0就可以结束while空转,进入临界区。
- 对于进程P0,如果P1标记了,并且轮到了P1(

下面分析这种方法:
- 互斥性:满足。可用反证法假设两个进程都进入,turn=0=1,不可能。
- 有空让进:满足。有空,假设进程P1不在临界区,即flag[1]=false,那么P0就不会在while处空转,直接进入临界区。
- 有限等待:满足。这是因为turn只能取0/1,两者不会同时停在while。
如下图右边所示,使用这样的处理(红色):
- 进入临界区时,置位
flag[i]=true, turn=j,如果 j 进程的flag==true,则空转, - 否则进入临界区执行修改信号量的操作;
- 退出临界区时将
flag[i]=false;
就不会使 empty 出现语义错误。这个算法是正确的。

2.5.4 方法A:多进程,面包店算法
多进程情况下,采用面包店算法;是 Peterson算法的扩展与改进。
-
标记:
-
每个进程进入时取一个非零序号
进入时获得的非零序号是当前最大的序号 +1,保证有序。
-
进程离开时置序号位为0,
不为0的序号就算为打上标记
-
-
轮转:在多个进程都有标记(非零)时,序号最小的进入
这保证了非对称性,总有一个优先。
-
具体代码实现如下图:
-
进入时,除了取号(最大值+1),还需要设计一个 choosing 数组,来确保每次挑选序号的进程只有一个。如果有人正在选号:
while(choosing[j]);则等待。 -
退出时将 标记/序号 置为0 :
num[i]=0;

下面分析一下这个算法:
- 互斥性:满足。因为由于取号的限制,最小的只有一个。
- 有空让进:如果没有进程在临界区,最小序号进程一定进入。
- 有限等待:离开临界区的进程再次进入一定排在最后,所以等待有限时间即可被执行。
但是这种算法还是太麻烦,并且不断取号,序号会有溢出风险,我们还需要设置机制来避免溢出。
2.5.5 方法B:硬件指令
上面的算法是在软件层次上做的,比较复杂,下面两种方法都是在硬件上实现的。
-
临界区:只允许一个进程进入;换言之是此时阻止其他进程被调度。
-
进程调度依靠的是中断,硬件层面关了中断,就不会有别的进程插入了,也就不会有指令交错的问题
-
cli 命令就是关闭中断的指令;
-
sti 命令 打开中断
- schedule() 是主动的程序调度,不使用中断,而检查程序时间片是否用完了进行的调度涉及时钟中断,所以这里的关中断是防止发生不受控制的时钟中断,从而引起程序调度
- 更细致版本:
cli()与sli()修改的是 IF 中断标志位,其位于 EFLAGS 寄存器中,schedule()切换到下一进程后马上会执行iret,此时会将内核栈中的EFLAGS 弹栈,再次开启中断
但是这种方法在多CPU、多核的情况下效果不好:
- 中断的原理:CPU上有一个中断寄存器INTR,如果置为1(比如时钟中断来临时),则代表需要中断,引起调度;
- 而多核CPU上,我们只能控制当前CPU的INTR,不能管理别的CPU的中断与否。
实验五信号量的实现可以使用这种方案,工大的模拟器模拟出来的计算机是单CPU的。

2.5.6 方法C:硬件原子指令法
再来思考一件事情:为了使得只有一个进程进入临界区工作,我们要对于信号量、临界区上锁,什么是锁呢?
-
可以考虑用一个信号量/一个整数来描述锁的状态,就像上文1.5中的 mutex
-
但是这种想法显然不成熟,因为我们使用了信号量来保护信号量
-
这就意味着不可行吗?不妨考虑一下前面提到的原子性。
-
如果把修改 mutex 的指令做成 原子指令
即中途不可能打断,要么执行,要么不执行,
那么执行时也就自动上锁.
-
用硬件原子指令修改一个整型变量,根据这个变量,再来判断应不应当进入临界区
-
下图是一种代码实现:
通过 TestAndSet 原子性操作,实现
while(TestAndSet(&lock));的一次执行,不会被打断。这里弹幕的问题主要是不理解 X 和 lock 是公用的一块内存,因为传递的参数是地址。

2.6 总结
一句话:用临界区保护信号量,用信号量实现进程同步。
3. 信号量代码实现
信号量原理复杂,但代码实现较为精简。
信号量的用途:
- 用户程序可以使用信号量实现同步
- OS内部也要使用大量信号量代码来完成进程同步
3.1 生产者-消费者
下面还是以 生产者-消费者 为例,
-
在内核中使用系统调用,申请一个信号量
-
多个进程都可见,所以信号量应当在内核中。
-
sem.c 源码如下图左下角;它规定了信号量的相关内容,比如下面代码中定义了20个信号量,一个name数组存放其名字,然后是它们的 value 和 PCB 队列。
sys_sem_open 系统调用 完成的工作就是:在上面name[]表中找到对应名字(如 empty) 的信号量,如果已经有这个信号量,那么直接返回即可,没有则创建并设初值;
-
申请的信号量,各进程都可见,据此决定如何进行工作。
-
-
fd 是文件,这里假设生产者向文件中依次输出 1~5 这 5 个数,每个数占 4 个字节,每次写之前,都要调用
sem_wait(sd),来判断空余状态;
-
sem_wait()根据传入的 sd 找到对应的 value,如果value-- < 0,说明没有空余位置,应当阻塞自己,将自己放入等待队列;注意:这里后–; 是先执行判断再减1 即前提是if为true才会减value。
放入等待队列后 进行 schedule,切换下一个进程就绪.
这里的不完整代码就是实验五需要完成的内容之一。
-
本部分假定与LInux 0.11 适配,使用 单CPU,可以使用2.5.5 中的硬件指令关中断的方法。
-
在临界区前后加入 cli() 和 sti() 保护信号量。

3.2 借鉴 Linux 0.11
Linux 0.11 的内核中没有上述信号量的设计,如何实现进程间同步呢?
例子:用户程序发出read系统调用,在内核中最终调用bread,到磁盘上读磁盘块;
具体细节会在后面讲文件系统的时候讲;
-
首先获得一个空闲的内存bh用于缓冲数据,bh的数据类型是 buffer_head;采用DMA将磁盘块内容逐步读进来。
-
ll_rw_block(READ, bh),启动磁盘读; -
wait_on_buffer(bh),在缓冲区bh上等待,即启动磁盘读之后睡眠,等待磁盘读完由相关中断唤醒。 -
bh中有类似信号量的数据:
bh->b_lock; 各个进程根据这个lock决定如何工作;同样需要对其进行保护,添加 cli() 和 sti().
读取磁盘时,
lock_buffer()中的 b_lock=1,表示已经锁上了;那么当前进程sleep_on(&bh->b_wait);当读完后通过中断会解锁。
这里的机制跟前面信号量机制不同的是:
- 这里用的是 while(1) (而不是if)
- 为什么是while 看下面:
while(信号量) 的工作机制:
-
我们需要从 sleep_on 这里看起,看看进程如何 “睡”、如何唤醒(唤醒时就能看出 while 的机制)
-
如下图右侧代码所示:
-
struct task_struct *tmp; tmp=*p; *p=current;这是很隐蔽的队列,就是把当前进程放入阻塞队列
-
将自己的状态改为阻塞状态,调用 schedule 切换进程;后面被唤醒,再调度切换回来时,会从这里恢复执行
-
f (tmp) temp->state=0;当前进程被唤醒了,那么队列中的下一个进程也被唤醒;

上文所说的隐秘队列到底长什么样子呢?
-
sleep_on 的函数参数应当是一个队列,所以按照以前的知识,我们应当传入队首的指针,而这里**p是队首指针的指针。
-
tmp 是局部变量,使其指向 task_struct.
-
再将 *p 指向 current,移向了当前(正要入队)的 task_struct;按照数据结构的知识,这里是新来的放到了队首。
-
按照数据结构的头插法,task_struct 应该有一个 next 指针,让当前进程的 task_struct->next 指向 tmp,队列链接就完成了
-
但是设计者考虑了内核的特性,这里的tmp局部变量,已经保存在了内核栈中
-
tmp 局部变量的作用,就是用于指向队列中下一个进程的 task_struct,作用相当于 next 指针,如下图中的虚线所示
解释为什么 tmp 可以作为 next 指针:
- 局部变量tmp是放在栈中,代码在内核态执行,tmp是放在内核栈。
- 当前进程的内核栈在当前进程中能找到,切换时内核栈会跟着切换,所以切换后可以找到当前进程的内核栈,当前进程的内核栈中可以找到当前进程的tmp
- 而当前进程的tmp指向了下一个进程的PCB,下一个进程的PCB中可以找到下一个进程的内核栈,下一个进程的内核栈中可以找到也可以找到下一个进程的tmp,下一个进程的tmp指向再下一个进程的PCB,以此循环

如何将放入 sleep_on 的进程唤醒呢?
- 执行磁盘中断时,会执行
end_request(1) end_request(1)会执行 unlock_buffer();- unlock_buffer() 会将 lock 置为0,并wake_up;
- wake_up 在队列不空的情况下(
p&&*p)将队首的PCB的state置为0,即为就绪态,此时唤醒了队首进程
进程A被唤醒,应当从哪里执行?
-
很显然,从进入睡眠前停止的地方进行。
-
回看上面 sleep_on 的代码,state设为阻塞态,schedule到其他进程切换
-
所以唤醒后继续执行 :
if(tmp){ tmp -> state = 0; }这两行代码唤醒了队首进程的下一个进程B;同样这个进程B会执行相同的两行代码唤醒B的下一个进程C。依次递推,将阻塞队列中的全部进程唤醒。
- 注意这里的“唤醒”,只是它们能够被调度,并不意味着已经被调度。
- 接下来会用调度算法去找优先级最高的下一个进程X,调度执行。
- 该进程X执行后进入临界区,会把lock 锁上(=1);这时其他进程依次while,把自己休眠掉。
到这里其实就解释了 3.2 最开始 lock_buffer 中,为什么使用的是 while 循环,因为这里会把阻塞队列中的所有进程唤醒,而接下来只有一个进程能够进入临界区并上锁,剩下的进程需要再次sleep
而 if 只唤醒阻塞队列中第一个。
为什么要将所有进程都唤醒?我们前面介绍的 if 方案只需要唤醒一个。
-
if 方案中 排在前面的进程一定先执行,但是后来的进程优先级可能更高;
-
在阻塞队列中,你不能确定剩下的进程的优先级是否更高,所以干脆全部唤醒,让 schedule() 来决定到底切换给谁
-
回看前面的while循环:
lock_buffer(buffer_head *bh){ cli(); while(bh->b_lock){ sleep_on(&bh->b_wait); } bh -> b_lock = 1; sti(); }可见这里的while循环是对所有唤醒的进程进行判断的过程,让高优先级的进入,其他的经过循环判断后睡眠。

3.3 对比
while(lock) 和前面 if(signal) 有什么异同?
- 前者不需要负数,不需要记要记录阻塞队列中有多少进程在等待。因为它每次都把所有都唤醒,通过 while 判断将不能进入临界区的进程休眠。
- 前者唤醒阻塞队列中全部进程,按照优先级调度;
- 后者唤醒阻塞队列中的第一个,按照(也只能按照)先后顺序调度;后者的想法很直观,但是缺点明显。
推荐用 if 这个直观想法实现实验五,再用 while 实现。
4. 死锁处理
这部分是关于进程的最后一部分。死锁也是多进程图像可能会发生的问题。
4.1 死锁来源
再回到 生产者-消费者 这个例子;回到 1.5 Part.
-
如果调换一下信号量的使用顺序,如下图,就会产生死锁:
因为是用户程序,用户完全可以这样调换(默认用户不知情);即先申请mutex后申请empty。
-
运行一下:
-
生产者 A 进程(左)运行mutex ,原为1,赋值为0;
-
A进程运行 empty,0,表示缓冲区满了,执行完后变为-1,阻塞;
-
消费者 B进程 执行,mutex 0变为-1,阻塞;
-
而 A 进程锁在 empty,必须 B进程 执行V(empty)方可解锁;而 V(empty) 依赖于 P(mutex);
-
B 的 P(mutex) 依赖于 A 的 V(mutex),而后者已经卡住了。

-

死锁:多个进程由于互相等待对方持有的资源而造成谁都无法执行的情况
设想再来一个进程C,想要申请 mutex,也会死锁,与之关联的进程可能也会死锁。这样就像感染一样,牵连到的进程越来越多。电脑变得很慢,卡死。
4.2 死锁的成因
关于死锁,有一个很形象的图,下图右侧,A的前进被B阻碍,B的前进被C阻碍,C的前进被D阻碍,D的前进被A阻碍…

具体成因归纳:
- 有一些资源(如信号量)互斥使用,占用后别人无法使用;
- 进程X占用了这种资源,不释放,又去申请其他资源;
- 恰巧申请的资源正被进程N占用,进程X会等待;
- 如果进程N正好 要申请 X 占用的互斥资源,则进入死锁。
再简要一点,死锁的必要条件:

4.3 死锁处理方法
联系生活,处理一个问题也就如下几个方面:

死锁忽略:死锁还是一个小概率事件,假如个人PC机死机了,则可以重启来解决;但另外一些比较重要的场景,例如卫星上的操作系统,银行的操作系统就肯定不能死锁忽略了。
死锁忽略就不在下面处理方法详细探讨的范畴内了
4.3.1 死锁预防
死锁预防的基本想法是在进程执行前,破坏死锁出现的必要条件,有两种考虑:
-
在进程执行前,一次性申请所有需要的资源,这就不会出现占有资源的同时还要申请其他资源。(破坏请求和保持条件)
-
缺点:
-
需要预知未来,编程困难;
比如有一些资源是通过if来决定是否申请的,这种方法需要编译时列出全部需要资源,全部申请。
-
申请全部资源意味着一些分配到的资源很长时间后才会被使用,资源利用率低;
-
-
-
顺序资源分配,首先给系统中的资源编号,规定每个进程必须按编号递增的顺序请求资源,同类资源(即编号相同的资源)一次申请完。(破坏循环等待条件)
这个不太好理解:
一个进程只有已占有小编号的资源时,才有资格申请更大编号的资源。按此规则,已持有大编号资源的进程不可能逆向地回来申请小编号的资源,从而就不会产生循环等待的现象。
- 缺点:需要对进程排序,还是浪费资源


4.3.2 死锁避免
死锁避免的考虑是判断进程的此次请求是否会引起死锁。而判断算法就是 银行家算法。
银行家算法:寻找是否存在可完成的执行序列/安全序列 P0.P1.P2…Pn

算法过程:
- 上图表格的三纵列依次表示:分配到的资源、需要的资源以及系统中还有的资源。
- 根据 2-3-0 的资源剩余量,只能决定给P1使用,P1执行完毕释放资源为 5-3-2
- 继续同理判断…
- 答案是AD;
银行家算法的实现,其实就跟上面的过程相差不大,时间复杂度 T(n)=O(mn2)


银行家算法只是求出了安全序列,如何为死锁避免服务呢?
-
分支预测。
将申请假设为分配策略,然后用银行家算法判断是否存在安全序列。如果没有,则拒绝申请。

- 算法分析:系统中的进程和资源都相当多,并且每次申请都要这么做,计算量很大。
4.3.3 死锁检测+恢复
既然避免死锁的代价太大,而出现死锁的概率又很低,联想计组的加速大概率事件思想,我们可以在发现死锁后再处理死锁;这样消耗的代价很低。
- 定时检测或者是系统发现资源利用率低时 检测,执行一遍银行家算法
- 找到死锁的进程序列,从里面挑一个进程回滚。
- 如何回滚?
- 尝试,回滚到一定程度再用银行家算法测试;
- 选择哪个进程回滚?
- 挑选哪个进程回滚都不是很合适。因为有些进程可能已经运行了很长时间,甚至接近结束。
- 如何实现回滚?
- 有许多机制。比如设立一种机制让系统记录进程的历史信息,设置还原点。
这里具体还可以参见:死锁的处理策略—预防死锁、避免死锁、检测和解除死锁-面包板社区 (eet-china.com)的死锁检测和解除部分。

4.4 总结
PC的通用操作系统上还是采用死锁忽略这个朴素方法的。因为可见4.3.1~4.3.3 的三种方法 消耗都不小,而死锁忽略的代价很小。