k8s deployment controller源码分析
- 2021 年 10 月 10 日
- 筆記
- kube-controller-manager分析, kubernetes源码解析
deployment controller简介
deployment controller是kube-controller-manager组件中众多控制器中的一个,是 deployment 资源对象的控制器,其通过对deployment、replicaset、pod三种资源的监听,当三种资源发生变化时会触发 deployment controller 对相应的deployment资源进行调谐操作,从而完成deployment的扩缩容、暂停恢复、更新、回滚、状态status更新、所属的旧replicaset清理等操作。
deployment controller架构图
deployment controller的大致组成和处理流程如下图,deployment controller对pod、replicaset和deployment对象注册了event handler,当有事件时,会watch到然后将对应的deployment对象放入到queue中,然后syncDeployment方法为deployment controller调谐deployment对象的核心处理逻辑所在,从queue中取出deployment对象,做调谐处理。
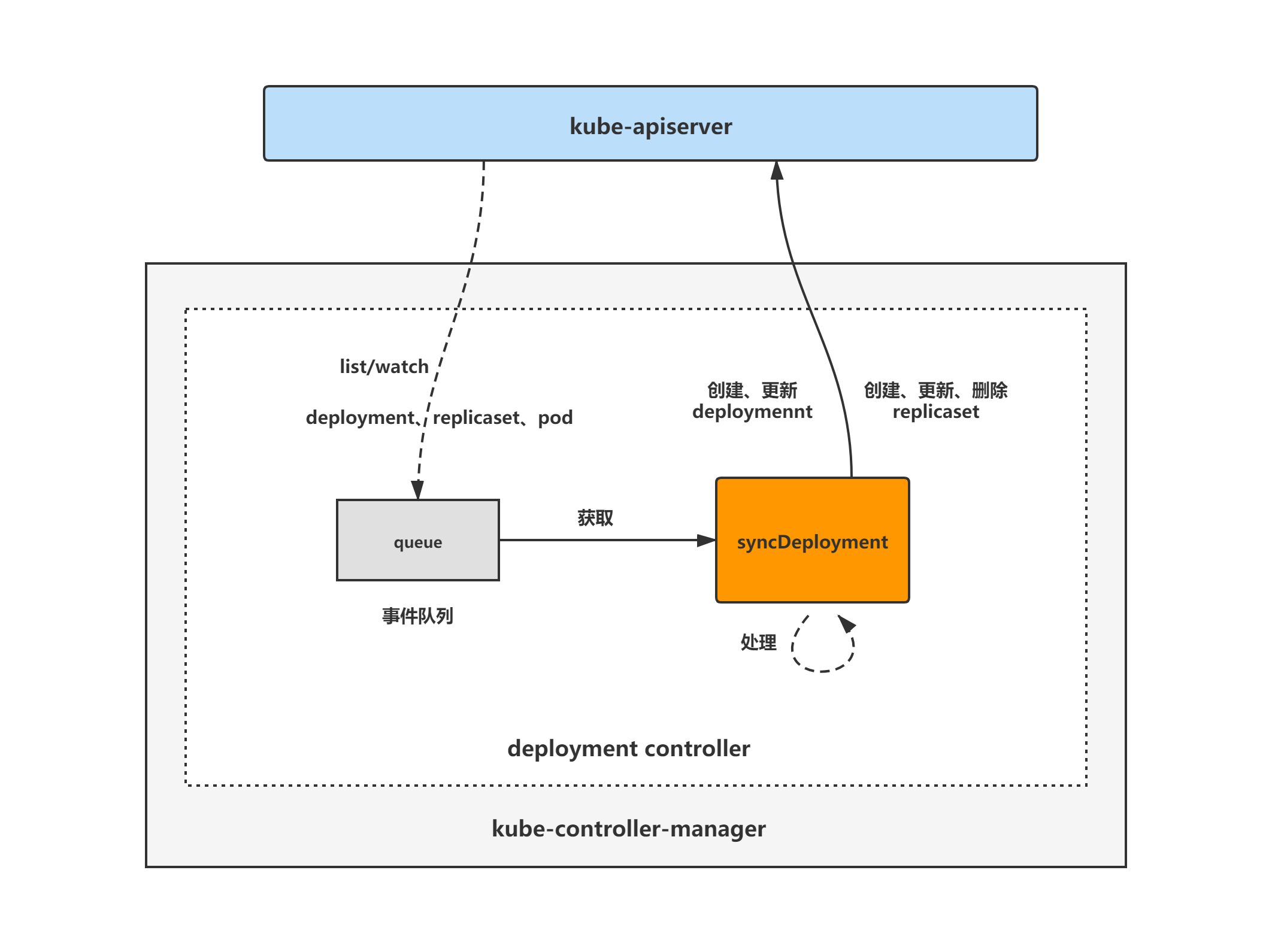
deployment controller分析将分为两大块进行,分别是:
(1)deployment controller初始化与启动分析;
(2)deployment controller处理逻辑分析。
1.deployment controller初始化与启动分析
基于tag v1.17.4
//github.com/kubernetes/kubernetes/releases/tag/v1.17.4
直接看到startDeploymentController函数,作为deployment controller初始化与启动分析的入口。
startDeploymentController
startDeploymentController主要逻辑:
(1)调用deployment.NewDeploymentController新建并初始化DeploymentController;
(2)拉起一个goroutine,跑DeploymentController的Run方法。
// cmd/kube-controller-manager/app/apps.go
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
1.1 deployment.NewDeploymentController
从deployment.NewDeploymentController函数代码中可以看到,deployment controller注册了deployment、replicaset与pod对象的EventHandler,也即对这几个对象的event进行监听,把event放入事件队列并做处理。并且将dc.syncDeployment方法赋值给dc.syncHandler,也即注册为核心处理方法,在dc.Run方法中会调用该核心处理方法来调谐deployment对象(核心处理方法后面会进行详细分析)。
// pkg/controller/deployment/deployment_controller.go
// NewDeploymentController creates a new DeploymentController.
func NewDeploymentController(dInformer appsinformers.DeploymentInformer, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, client clientset.Interface) (*DeploymentController, error) {
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: client.CoreV1().Events("")})
if client != nil && client.CoreV1().RESTClient().GetRateLimiter() != nil {
if err := ratelimiter.RegisterMetricAndTrackRateLimiterUsage("deployment_controller", client.CoreV1().RESTClient().GetRateLimiter()); err != nil {
return nil, err
}
}
dc := &DeploymentController{
client: client,
eventRecorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "deployment-controller"}),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
dc.rsControl = controller.RealRSControl{
KubeClient: client,
Recorder: dc.eventRecorder,
}
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
dc.syncHandler = dc.syncDeployment
dc.enqueueDeployment = dc.enqueue
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
dc.dListerSynced = dInformer.Informer().HasSynced
dc.rsListerSynced = rsInformer.Informer().HasSynced
dc.podListerSynced = podInformer.Informer().HasSynced
return dc, nil
}
1.2 dc.Run
主要看到for循环处,根据workers的值(来源于kcm启动参数concurrent-deployment-syncs配置),启动相应数量的goroutine,跑dc.worker方法,主要是调用前面讲到的deployment controller核心处理方法dc.syncDeployment。
// pkg/controller/deployment/deployment_controller.go
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
if !cache.WaitForNamedCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
<-stopCh
}
1.2.1 dc.worker
从queue队列中取出事件key,并调用dc.syncHandle即dc.syncDeployment做调谐处理。queue队列里的事件来源前面讲过,是deployment controller注册的deployment、replicaset与pod对象的EventHandler,它们的变化event会被监听到然后放入queue中。
// pkg/controller/deployment/deployment_controller.go
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}
2.deployment controller核心处理逻辑分析
进行核心处理逻辑分析前,先来了解几个关键概念。
几个关键概念
进行代码分析前,先来看几个关键的概念。
(1)最新的replicaset对象
怎样的replicaset对象是最新的呢?replicaset对象的pod template与deployment的一致,则代表该replicaset是最新的。
(2)旧的replicaset对象
怎样的replicaset对象是旧的呢?除去最新的replicaset对象,其余的都是旧的replicaset。
(3)ready状态的pod
pod对象的.status.conditions中,type为Ready的condition中,其status属性值为True,则代表该pod属于ready状态。
apiVersion: v1
kind: Pod
...
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2021-08-04T08:47:03Z"
status: "True"
type: Ready
...
而type为Ready的condition中,其status属性值会pod的各个容器都ready之后,将其值设置为True。
pod里的容器何时ready?kubelet会根据容器配置的readiness probe就绪探测策略,在探测成功后更新pod的status将该容器设置为ready,yaml示例如下。
apiVersion: v1
kind: Pod
...
status:
...
containerStatuses:
- containerID: xxx
image: xxx
imageID: xxx
lastState: {}
name: test
ready: true
...
(4)available状态的pod
pod处于ready状态且已经超过了minReadySeconds时间后,该pod即处于available状态。
syncDeployment
直接看到deployment controller核心处理方法syncDeployment。
主要逻辑:
(1)获取执行方法时的当前时间,并定义defer函数,用于计算该方法总执行时间,也即统计对一个 deployment 进行同步调谐操作的耗时;
(2)根据 deployment 对象的命名空间与名称,获取 deployment 对象;
(3)调用dc.getReplicaSetsForDeployment:对集群中与deployment对象相同命名空间下的所有replicaset对象做处理,若发现匹配但没有关联 deployment 的 replicaset 则通过设置 ownerReferences 字段与 deployment 关联,已关联但不匹配的则删除对应的 ownerReferences,最后获取返回集群中与 Deployment 关联匹配的 ReplicaSet对象列表;
(4)调用dc.getPodMapForDeployment:根据deployment对象的selector,获取当前 deployment 对象关联的 pod,根据 deployment 所属的 replicaset 对象的UID对 pod 进行分类并返回,返回值类型为map[types.UID][]*v1.Pod;
(5)如果 deployment 对象的 DeletionTimestamp 属性值不为空,则调用dc.syncStatusOnly,根据deployment 所属的 replicaset 对象,重新计算出 deployment 对象的status字段值并更新,调用完成后,直接return,不继续往下执行;
(6)调用dc.checkPausedConditions:检查 deployment 是否为pause状态,是则更新deployment对象的status字段值,为其添加pause相关的condition;
(7)判断deployment对象的.Spec.Paused属性值,为true时,则调用dc.sync做处理,调用完成后直接return;
(8)调用getRollbackTo检查deployment对象的annotations中是否有以下key:deprecated.deployment.rollback.to,如果有且值不为空,调用 dc.rollback 方法执行 回滚操作;
(9)调用dc.isScalingEvent:检查deployment对象是否处于 scaling 状态,是则调用dc.sync做扩缩容处理,调用完成后直接return;
(10)判断deployment对象的更新策略,当更新策略为Recreate时调用dc.rolloutRecreate做进一步处理,也即对deployment进行recreate更新处理;当更新策略为RollingUpdate时调用dc.rolloutRolling做进一步处理,也即对deployment进行滚动更新处理。
// pkg/controller/deployment/deployment_controller.go
// syncDeployment will sync the deployment with the given key.
// This function is not meant to be invoked concurrently with the same key.
func (dc *DeploymentController) syncDeployment(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d)
}
return nil
}
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef
// through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// List all Pods owned by this Deployment, grouped by their ReplicaSet.
// Current uses of the podMap are:
//
// * check if a Pod is labeled correctly with the pod-template-hash label.
// * check that no old Pods are running in the middle of Recreate Deployments.
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// Update deployment conditions with an Unknown condition when pausing/resuming
// a deployment. In this way, we can be sure that we won't timeout when a user
// resumes a Deployment with a set progressDeadlineSeconds.
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// rollback is not re-entrant in case the underlying replica sets are updated with a new
// revision so we should ensure that we won't proceed to update replica sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
2.1 dc.getReplicaSetsForDeployment
dc.getReplicaSetsForDeployment主要作用:获取集群中与 Deployment 相关的 ReplicaSet,若发现匹配但没有关联 deployment 的 replicaset 则通过设置 ownerReferences 字段与 deployment 关联,已关联但不匹配的则删除对应的 ownerReferences。
主要逻辑如下:
(1)获取deployment对象命名空间下的所有replicaset对象;
(2)调用cm.ClaimReplicaSets对replicaset做进一步处理,并最终返回与deployment匹配关联的replicaset对象列表。
// pkg/controller/deployment/deployment_controller.go
// getReplicaSetsForDeployment uses ControllerRefManager to reconcile
// ControllerRef by adopting and orphaning.
// It returns the list of ReplicaSets that this Deployment should manage.
func (dc *DeploymentController) getReplicaSetsForDeployment(d *apps.Deployment) ([]*apps.ReplicaSet, error) {
// List all ReplicaSets to find those we own but that no longer match our
// selector. They will be orphaned by ClaimReplicaSets().
rsList, err := dc.rsLister.ReplicaSets(d.Namespace).List(labels.Everything())
if err != nil {
return nil, err
}
deploymentSelector, err := metav1.LabelSelectorAsSelector(d.Spec.Selector)
if err != nil {
return nil, fmt.Errorf("deployment %s/%s has invalid label selector: %v", d.Namespace, d.Name, err)
}
// If any adoptions are attempted, we should first recheck for deletion with
// an uncached quorum read sometime after listing ReplicaSets (see #42639).
canAdoptFunc := controller.RecheckDeletionTimestamp(func() (metav1.Object, error) {
fresh, err := dc.client.AppsV1().Deployments(d.Namespace).Get(d.Name, metav1.GetOptions{})
if err != nil {
return nil, err
}
if fresh.UID != d.UID {
return nil, fmt.Errorf("original Deployment %v/%v is gone: got uid %v, wanted %v", d.Namespace, d.Name, fresh.UID, d.UID)
}
return fresh, nil
})
cm := controller.NewReplicaSetControllerRefManager(dc.rsControl, d, deploymentSelector, controllerKind, canAdoptFunc)
return cm.ClaimReplicaSets(rsList)
}
2.1.1 cm.ClaimReplicaSets
遍历与deployment对象相同命名空间下的所有replicaset对象,调用m.ClaimObject做处理,m.ClaimObject的作用主要是将匹配但没有关联 deployment 的 replicaset 则通过设置 ownerReferences 字段与 deployment 关联,已关联但不匹配的则删除对应的 ownerReferences。
// pkg/controller/controller_ref_manager.go
func (m *ReplicaSetControllerRefManager) ClaimReplicaSets(sets []*apps.ReplicaSet) ([]*apps.ReplicaSet, error) {
var claimed []*apps.ReplicaSet
var errlist []error
match := func(obj metav1.Object) bool {
return m.Selector.Matches(labels.Set(obj.GetLabels()))
}
adopt := func(obj metav1.Object) error {
return m.AdoptReplicaSet(obj.(*apps.ReplicaSet))
}
release := func(obj metav1.Object) error {
return m.ReleaseReplicaSet(obj.(*apps.ReplicaSet))
}
for _, rs := range sets {
ok, err := m.ClaimObject(rs, match, adopt, release)
if err != nil {
errlist = append(errlist, err)
continue
}
if ok {
claimed = append(claimed, rs)
}
}
return claimed, utilerrors.NewAggregate(errlist)
}
2.2 dc.getPodMapForDeployment
dc.getPodMapForDeployment:根据deployment对象的Selector,获取当前 deployment 对象关联的 pod,根据 deployment 所属的 replicaset 对象的UID对 pod 进行分类并返回,返回值类型为map[types.UID][]*v1.Pod。
// pkg/controller/deployment/deployment_controller.go
func (dc *DeploymentController) getPodMapForDeployment(d *apps.Deployment, rsList []*apps.ReplicaSet) (map[types.UID][]*v1.Pod, error) {
// Get all Pods that potentially belong to this Deployment.
selector, err := metav1.LabelSelectorAsSelector(d.Spec.Selector)
if err != nil {
return nil, err
}
pods, err := dc.podLister.Pods(d.Namespace).List(selector)
if err != nil {
return nil, err
}
// Group Pods by their controller (if it's in rsList).
podMap := make(map[types.UID][]*v1.Pod, len(rsList))
for _, rs := range rsList {
podMap[rs.UID] = []*v1.Pod{}
}
for _, pod := range pods {
// Do not ignore inactive Pods because Recreate Deployments need to verify that no
// Pods from older versions are running before spinning up new Pods.
controllerRef := metav1.GetControllerOf(pod)
if controllerRef == nil {
continue
}
// Only append if we care about this UID.
if _, ok := podMap[controllerRef.UID]; ok {
podMap[controllerRef.UID] = append(podMap[controllerRef.UID], pod)
}
}
return podMap, nil
}
2.3 dc.syncStatusOnly
如果 deployment 对象的 DeletionTimestamp 属性值不为空,则调用dc.syncStatusOnly,根据deployment 所属的 replicaset 对象,重新计算出 deployment 对象的status字段值并更新,调用完成后,直接return,不继续往下执行;
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) syncStatusOnly(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) syncDeploymentStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
if reflect.DeepEqual(d.Status, newStatus) {
return nil
}
newDeployment := d
newDeployment.Status = newStatus
_, err := dc.client.AppsV1().Deployments(newDeployment.Namespace).UpdateStatus(newDeployment)
return err
}
关于具体如何计算出deployment对象的status,可以查看calculateStatus函数,计算逻辑都在里面,这里不展开分析。
2.4 dc.rollback
先调用getRollbackTo检查deployment对象的annotations中是否有以下key:deprecated.deployment.rollback.to,如果有且值不为空,调用 dc.rollback 方法执行 rollback 操作;
// pkg/controller/deployment/rollback.go
func getRollbackTo(d *apps.Deployment) *extensions.RollbackConfig {
// Extract the annotation used for round-tripping the deprecated RollbackTo field.
revision := d.Annotations[apps.DeprecatedRollbackTo]
if revision == "" {
return nil
}
revision64, err := strconv.ParseInt(revision, 10, 64)
if err != nil {
// If it's invalid, ignore it.
return nil
}
return &extensions.RollbackConfig{
Revision: revision64,
}
}
dc.rollback主要逻辑:
(1)获取deployment的所有关联匹配的replicaset对象列表;
(2)获取需要回滚的Revision;
(3)遍历上述获得的replicaset对象列表,比较Revision是否与需要回滚的Revision一致,一致则调用dc.rollbackToTemplate做回滚操作(主要是根据特定的Revision的replicaset对象,更改deployment对象的.Spec.Template);
(4)最后,不管有没有回滚成功,都将deployment对象的.spec.rollbackTo属性置为nil,然后更新deployment对象。
// pkg/controller/deployment/rollback.go
func (dc *DeploymentController) rollback(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, allOldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs := append(allOldRSs, newRS)
rollbackTo := getRollbackTo(d)
// If rollback revision is 0, rollback to the last revision
if rollbackTo.Revision == 0 {
if rollbackTo.Revision = deploymentutil.LastRevision(allRSs); rollbackTo.Revision == 0 {
// If we still can't find the last revision, gives up rollback
dc.emitRollbackWarningEvent(d, deploymentutil.RollbackRevisionNotFound, "Unable to find last revision.")
// Gives up rollback
return dc.updateDeploymentAndClearRollbackTo(d)
}
}
for _, rs := range allRSs {
v, err := deploymentutil.Revision(rs)
if err != nil {
klog.V(4).Infof("Unable to extract revision from deployment's replica set %q: %v", rs.Name, err)
continue
}
if v == rollbackTo.Revision {
klog.V(4).Infof("Found replica set %q with desired revision %d", rs.Name, v)
// rollback by copying podTemplate.Spec from the replica set
// revision number will be incremented during the next getAllReplicaSetsAndSyncRevision call
// no-op if the spec matches current deployment's podTemplate.Spec
performedRollback, err := dc.rollbackToTemplate(d, rs)
if performedRollback && err == nil {
dc.emitRollbackNormalEvent(d, fmt.Sprintf("Rolled back deployment %q to revision %d", d.Name, rollbackTo.Revision))
}
return err
}
}
dc.emitRollbackWarningEvent(d, deploymentutil.RollbackRevisionNotFound, "Unable to find the revision to rollback to.")
// Gives up rollback
return dc.updateDeploymentAndClearRollbackTo(d)
}
2.5 dc.sync
下面来分析一下dc.sync方法,以下两种情况下,都会调用dc.sync,然后直接return:
(1)判断deployment的.Spec.Paused属性值是否为true,是则调用dc.sync做处理,调用完成后直接return;
(2)先调用dc.isScalingEvent,检查deployment对象是否处于 scaling 状态,是则调用dc.sync做处理,调用完成后直接return。
关于Paused字段
deployment的.Spec.Paused为true时代表该deployment处于暂停状态,false则代表处于正常状态。当deployment处于暂停状态时,deployment对象的PodTemplateSpec的任何修改都不会触发deployment的更新,当.Spec.Paused再次赋值为false时才会触发deployment更新。
dc.sync主要逻辑:
(1)调用dc.getAllReplicaSetsAndSyncRevision获取最新的replicaset对象以及旧的replicaset对象列表;
(2)调用dc.scale,判断是否需要进行扩缩容操作,需要则进行扩缩容操作;
(3)当deployment的.Spec.Paused为true且不需要做回滚操作时,调用dc.cleanupDeployment,根据deployment配置的保留历史版本数(.Spec.RevisionHistoryLimit)以及replicaset的创建时间,把最老的旧的replicaset给删除清理掉;
(4)调用dc.syncDeploymentStatus,计算并更新deployment对象的status字段。
// pkg/controller/deployment/sync.go
// sync is responsible for reconciling deployments on scaling events or when they
// are paused.
func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
if err := dc.scale(d, newRS, oldRSs); err != nil {
// If we get an error while trying to scale, the deployment will be requeued
// so we can abort this resync
return err
}
// Clean up the deployment when it's paused and no rollback is in flight.
if d.Spec.Paused && getRollbackTo(d) == nil {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
allRSs := append(oldRSs, newRS)
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
2.5.1 dc.scale
dc.scale主要作用是处理deployment的扩缩容操作,其主要逻辑如下:
(1)调用deploymentutil.FindActiveOrLatest,判断是否只有最新的replicaset对象的副本数不为0,是则找到最新的replicaset对象,并判断其副本数是否与deployment期望副本数一致,是则直接return,否则调用dc.scaleReplicaSetAndRecordEvent更新其副本数为deployment的期望副本数;
(2)当最新的replicaset对象的副本数与deployment期望副本数一致,且旧的replicaset对象中有副本数不为0的,则从旧的replicset对象列表中找出副本数不为0的replicaset,调用dc.scaleReplicaSetAndRecordEvent将其副本数缩容为0,然后return;
(3)当最新的replicaset对象的副本数与deployment期望副本数不一致,旧的replicaset对象中有副本数不为0的,且deployment的更新策略为滚动更新,说明deployment可能正在滚动更新,则按一定的比例对新旧replicaset进行扩缩容操作,保证滚动更新的稳定性,具体逻辑可以自己分析下,这里不展开分析。
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) scale(deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet) error {
// If there is only one active replica set then we should scale that up to the full count of the
// deployment. If there is no active replica set, then we should scale up the newest replica set.
if activeOrLatest := deploymentutil.FindActiveOrLatest(newRS, oldRSs); activeOrLatest != nil {
if *(activeOrLatest.Spec.Replicas) == *(deployment.Spec.Replicas) {
return nil
}
_, _, err := dc.scaleReplicaSetAndRecordEvent(activeOrLatest, *(deployment.Spec.Replicas), deployment)
return err
}
// If the new replica set is saturated, old replica sets should be fully scaled down.
// This case handles replica set adoption during a saturated new replica set.
if deploymentutil.IsSaturated(deployment, newRS) {
for _, old := range controller.FilterActiveReplicaSets(oldRSs) {
if _, _, err := dc.scaleReplicaSetAndRecordEvent(old, 0, deployment); err != nil {
return err
}
}
return nil
}
// There are old replica sets with pods and the new replica set is not saturated.
// We need to proportionally scale all replica sets (new and old) in case of a
// rolling deployment.
if deploymentutil.IsRollingUpdate(deployment) {
allRSs := controller.FilterActiveReplicaSets(append(oldRSs, newRS))
allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
allowedSize := int32(0)
if *(deployment.Spec.Replicas) > 0 {
allowedSize = *(deployment.Spec.Replicas) + deploymentutil.MaxSurge(*deployment)
}
// Number of additional replicas that can be either added or removed from the total
// replicas count. These replicas should be distributed proportionally to the active
// replica sets.
deploymentReplicasToAdd := allowedSize - allRSsReplicas
// The additional replicas should be distributed proportionally amongst the active
// replica sets from the larger to the smaller in size replica set. Scaling direction
// drives what happens in case we are trying to scale replica sets of the same size.
// In such a case when scaling up, we should scale up newer replica sets first, and
// when scaling down, we should scale down older replica sets first.
var scalingOperation string
switch {
case deploymentReplicasToAdd > 0:
sort.Sort(controller.ReplicaSetsBySizeNewer(allRSs))
scalingOperation = "up"
case deploymentReplicasToAdd < 0:
sort.Sort(controller.ReplicaSetsBySizeOlder(allRSs))
scalingOperation = "down"
}
// Iterate over all active replica sets and estimate proportions for each of them.
// The absolute value of deploymentReplicasAdded should never exceed the absolute
// value of deploymentReplicasToAdd.
deploymentReplicasAdded := int32(0)
nameToSize := make(map[string]int32)
for i := range allRSs {
rs := allRSs[i]
// Estimate proportions if we have replicas to add, otherwise simply populate
// nameToSize with the current sizes for each replica set.
if deploymentReplicasToAdd != 0 {
proportion := deploymentutil.GetProportion(rs, *deployment, deploymentReplicasToAdd, deploymentReplicasAdded)
nameToSize[rs.Name] = *(rs.Spec.Replicas) + proportion
deploymentReplicasAdded += proportion
} else {
nameToSize[rs.Name] = *(rs.Spec.Replicas)
}
}
// Update all replica sets
for i := range allRSs {
rs := allRSs[i]
// Add/remove any leftovers to the largest replica set.
if i == 0 && deploymentReplicasToAdd != 0 {
leftover := deploymentReplicasToAdd - deploymentReplicasAdded
nameToSize[rs.Name] = nameToSize[rs.Name] + leftover
if nameToSize[rs.Name] < 0 {
nameToSize[rs.Name] = 0
}
}
// TODO: Use transactions when we have them.
if _, _, err := dc.scaleReplicaSet(rs, nameToSize[rs.Name], deployment, scalingOperation); err != nil {
// Return as soon as we fail, the deployment is requeued
return err
}
}
}
return nil
}
2.5.2 dc.cleanupDeployment
当deployment的所有pod都是updated的和available的,而且没有旧的pod在running,则调用dc.cleanupDeployment,根据deployment配置的保留历史版本数(.Spec.RevisionHistoryLimit)以及replicaset的创建时间,把最老的旧的replicaset给删除清理掉。
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) cleanupDeployment(oldRSs []*apps.ReplicaSet, deployment *apps.Deployment) error {
if !deploymentutil.HasRevisionHistoryLimit(deployment) {
return nil
}
// Avoid deleting replica set with deletion timestamp set
aliveFilter := func(rs *apps.ReplicaSet) bool {
return rs != nil && rs.ObjectMeta.DeletionTimestamp == nil
}
cleanableRSes := controller.FilterReplicaSets(oldRSs, aliveFilter)
diff := int32(len(cleanableRSes)) - *deployment.Spec.RevisionHistoryLimit
if diff <= 0 {
return nil
}
sort.Sort(controller.ReplicaSetsByCreationTimestamp(cleanableRSes))
klog.V(4).Infof("Looking to cleanup old replica sets for deployment %q", deployment.Name)
for i := int32(0); i < diff; i++ {
rs := cleanableRSes[i]
// Avoid delete replica set with non-zero replica counts
if rs.Status.Replicas != 0 || *(rs.Spec.Replicas) != 0 || rs.Generation > rs.Status.ObservedGeneration || rs.DeletionTimestamp != nil {
continue
}
klog.V(4).Infof("Trying to cleanup replica set %q for deployment %q", rs.Name, deployment.Name)
if err := dc.client.AppsV1().ReplicaSets(rs.Namespace).Delete(rs.Name, nil); err != nil && !errors.IsNotFound(err) {
// Return error instead of aggregating and continuing DELETEs on the theory
// that we may be overloading the api server.
return err
}
}
return nil
}
2.6 dc.rolloutRecreate
判断deployment对象的更新策略.Spec.Strategy.Type,当更新策略为Recreate时调用dc.rolloutRecreate做进一步处理。
dc.rolloutRecreate主要逻辑:
(1)调用dc.getAllReplicaSetsAndSyncRevision,获取最新的replicaset对象以及旧的replicaset对象列表;
(2)调用dc.scaleDownOldReplicaSetsForRecreate,缩容旧的replicaSets,将它们的副本数更新为0,当有旧的replicasets需要缩容时,调用dc.syncRolloutStatus更新deployment状态后直接return;
(3)调用oldPodsRunning函数,判断是否有属于deployment的pod还在running(pod的pod.Status.Phase属性值为Failed或Succeeded时代表该pod不在running),还在running则调用dc.syncRolloutStatus更新deployment状态并直接return;
(4)当新的replicaset对象没有被创建时,调用dc.getAllReplicaSetsAndSyncRevision来创建新的replicaset对象(注意:新创建的replicaset的副本数为0);
(5)调用dc.scaleUpNewReplicaSetForRecreate,扩容刚新创建的replicaset,更新其副本数与deployment期望副本数一致(即deployment的.Spec.Replicas属性值);
(6)调用util.DeploymentComplete,检查deployment的所有pod是否都是updated的和available的,而且没有旧的pod在running,是则继续调用dc.cleanupDeployment,根据deployment配置的保留历史版本数(.Spec.RevisionHistoryLimit)以及replicaset的创建时间,把最老的旧的replicaset给删除清理掉。
(7)调用dc.syncRolloutStatus更新deployment状态。
// pkg/controller/deployment/recreate.go
// rolloutRecreate implements the logic for recreating a replica set.
func (dc *DeploymentController) rolloutRecreate(d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID][]*v1.Pod) error {
// Don't create a new RS if not already existed, so that we avoid scaling up before scaling down.
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
// scale down old replica sets.
scaledDown, err := dc.scaleDownOldReplicaSetsForRecreate(activeOldRSs, d)
if err != nil {
return err
}
if scaledDown {
// Update DeploymentStatus.
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// Do not process a deployment when it has old pods running.
if oldPodsRunning(newRS, oldRSs, podMap) {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// If we need to create a new RS, create it now.
if newRS == nil {
newRS, oldRSs, err = dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs = append(oldRSs, newRS)
}
// scale up new replica set.
if _, err := dc.scaleUpNewReplicaSetForRecreate(newRS, d); err != nil {
return err
}
if util.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
// Sync deployment status.
return dc.syncRolloutStatus(allRSs, newRS, d)
}
2.6.1 dc.getAllReplicaSetsAndSyncRevision
dc.getAllReplicaSetsAndSyncRevision会获取所有的旧的replicaset对象,以及最新的replicaset对象,然后返回。
关于最新的replicaset对象,怎样的replicaset对象是最新的呢?replicaset对象的pod template与deployment的一致,则代表该replicaset是最新的。
关于旧的replicaset对象,怎样的replicaset对象是旧的呢?除去最新的replicaset对象,其余的都是旧的replicaset。
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) getAllReplicaSetsAndSyncRevision(d *apps.Deployment, rsList []*apps.ReplicaSet, createIfNotExisted bool) (*apps.ReplicaSet, []*apps.ReplicaSet, error) {
_, allOldRSs := deploymentutil.FindOldReplicaSets(d, rsList)
// Get new replica set with the updated revision number
newRS, err := dc.getNewReplicaSet(d, rsList, allOldRSs, createIfNotExisted)
if err != nil {
return nil, nil, err
}
return newRS, allOldRSs, nil
}
2.6.2 dc.syncRolloutStatus
syncRolloutStatus方法主要作用是计算出deployment的新的status属性值并更新,具体的计算逻辑可以自己查看代码,这里不展开分析。
// pkg/controller/deployment/progress.go
func (dc *DeploymentController) syncRolloutStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
...
}
2.6.3 oldPodsRunning
遍历deployment下所有的pod,找到属于旧的replicaset对象的pod,判断pod的状态(即pod.Status.Phase的值)是否都是Failed或Succeeded,是则代表所有旧的pod都没在running了,返回false。
// pkg/controller/deployment/recreate.go
func oldPodsRunning(newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet, podMap map[types.UID][]*v1.Pod) bool {
if oldPods := util.GetActualReplicaCountForReplicaSets(oldRSs); oldPods > 0 {
return true
}
for rsUID, podList := range podMap {
// If the pods belong to the new ReplicaSet, ignore.
if newRS != nil && newRS.UID == rsUID {
continue
}
for _, pod := range podList {
switch pod.Status.Phase {
case v1.PodFailed, v1.PodSucceeded:
// Don't count pods in terminal state.
continue
case v1.PodUnknown:
// This happens in situation like when the node is temporarily disconnected from the cluster.
// If we can't be sure that the pod is not running, we have to count it.
return true
default:
// Pod is not in terminal phase.
return true
}
}
}
return false
}
2.6.4 dc.getAllReplicaSetsAndSyncRevision
dc.getAllReplicaSetsAndSyncRevision方法主要作用是获取最新的replicaset对象以及旧的replicaset对象列表,当传入的createIfNotExisted变量值为true且新的replicaset对象不存在时,调用dc.getNewReplicaSet时会新建replicaset对象(新建的replicaset对象副本数为0)。
// pkg/controller/deployment/sync.go
func (dc *DeploymentController) getAllReplicaSetsAndSyncRevision(d *apps.Deployment, rsList []*apps.ReplicaSet, createIfNotExisted bool) (*apps.ReplicaSet, []*apps.ReplicaSet, error) {
_, allOldRSs := deploymentutil.FindOldReplicaSets(d, rsList)
// Get new replica set with the updated revision number
newRS, err := dc.getNewReplicaSet(d, rsList, allOldRSs, createIfNotExisted)
if err != nil {
return nil, nil, err
}
return newRS, allOldRSs, nil
}
2.6.5 dc.scaleDownOldReplicaSetsForRecreate
遍历全部旧的replicaset,调用dc.scaleReplicaSetAndRecordEvent将其副本数缩容为0。
// pkg/controller/deployment/recreate.go
func (dc *DeploymentController) scaleDownOldReplicaSetsForRecreate(oldRSs []*apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
scaled := false
for i := range oldRSs {
rs := oldRSs[i]
// Scaling not required.
if *(rs.Spec.Replicas) == 0 {
continue
}
scaledRS, updatedRS, err := dc.scaleReplicaSetAndRecordEvent(rs, 0, deployment)
if err != nil {
return false, err
}
if scaledRS {
oldRSs[i] = updatedRS
scaled = true
}
}
return scaled, nil
}
2.6.6 dc.scaleUpNewReplicaSetForRecreate
调用dc.scaleReplicaSetAndRecordEvent,将最新的replicset对象的副本数更新为deployment期望的副本数。
// pkg/controller/deployment/recreate.go
func (dc *DeploymentController) scaleUpNewReplicaSetForRecreate(newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, *(deployment.Spec.Replicas), deployment)
return scaled, err
}
2.7 dc.rolloutRolling
判断deployment对象的更新策略.Spec.Strategy.Type,当更新策略为RollingUpdate时调用dc.rolloutRolling做进一步处理。
dc.rolloutRolling主要逻辑:
(1)调用dc.getAllReplicaSetsAndSyncRevision,获取最新的replicaset对象以及旧的replicaset对象列表,当新的replicaset对象不存在时,将创建一个新的replicaset对象(副本数为0);
(2)调用dc.reconcileNewReplicaSet,调谐新的replicaset对象,根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxSurge和现存pod数量进行计算,决定是否对新的replicaset对象进行扩容以及扩容的副本数;
(3)当新的replicaset对象副本数在调谐时被更新,则调用dc.syncRolloutStatus更新deployment状态后直接return;
(4)调用dc.reconcileOldReplicaSets,根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxUnavailable、现存的Available状态的pod数量、新replicaset对象下所属的available的pod数量,决定是否对旧的replicaset对象进行缩容以及缩容的副本数;
(5)当旧的replicaset对象副本数在调谐时被更新,则调用dc.syncRolloutStatus更新deployment状态后直接return;
(6)调用util.DeploymentComplete,检查deployment的所有pod是否都是updated的和available的,而且没有旧的pod在running,是则继续调用dc.cleanupDeployment,根据deployment配置的保留历史版本数(.Spec.RevisionHistoryLimit)以及replicaset的创建时间,把最老的旧的replicaset给删除清理掉。
(7)调用dc.syncRolloutStatus更新deployment状态。
// pkg/controller/deployment/rolling.go
// rolloutRolling implements the logic for rolling a new replica set.
func (dc *DeploymentController) rolloutRolling(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
// Scale up, if we can.
scaledUp, err := dc.reconcileNewReplicaSet(allRSs, newRS, d)
if err != nil {
return err
}
if scaledUp {
// Update DeploymentStatus
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// Scale down, if we can.
scaledDown, err := dc.reconcileOldReplicaSets(allRSs, controller.FilterActiveReplicaSets(oldRSs), newRS, d)
if err != nil {
return err
}
if scaledDown {
// Update DeploymentStatus
return dc.syncRolloutStatus(allRSs, newRS, d)
}
if deploymentutil.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
// Sync deployment status
return dc.syncRolloutStatus(allRSs, newRS, d)
}
2.7.1 dc.reconcileNewReplicaSet
dc.reconcileNewReplicaSet主要作用是调谐新的replicaset对象,根据deployment的滚动更新策略配置和现存pod数量进行计算,决定是否对新的replicaset对象进行扩容。
主要逻辑:
(1)当新的replicaset对象的副本数与deployment声明的副本数一致,则说明该replicaset对象无需再调谐,直接return;
(2)当新的replicaset对象的副本数比deployment声明的副本数要大,则调用dc.scaleReplicaSetAndRecordEvent,将replicaset对象的副本数缩容至与deployment声明的副本数一致,然后return;
(3)当新的replicaset对象的副本数比deployment声明的副本数要小,则调用deploymentutil.NewRSNewReplicas,根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxSurge的值计算出新replicaset对象该拥有的副本数量,并调用dc.scaleReplicaSetAndRecordEvent更新replicaset的副本数。
// pkg/controller/deployment/rolling.go
func (dc *DeploymentController) reconcileNewReplicaSet(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
if *(newRS.Spec.Replicas) == *(deployment.Spec.Replicas) {
// Scaling not required.
return false, nil
}
if *(newRS.Spec.Replicas) > *(deployment.Spec.Replicas) {
// Scale down.
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, *(deployment.Spec.Replicas), deployment)
return scaled, err
}
newReplicasCount, err := deploymentutil.NewRSNewReplicas(deployment, allRSs, newRS)
if err != nil {
return false, err
}
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, newReplicasCount, deployment)
return scaled, err
}
NewRSNewReplicas
当deployment配置了滚动更新策略时,NewRSNewReplicas函数将根据.Spec.Strategy.RollingUpdate.MaxSurge的配置,调用intstrutil.GetValueFromIntOrPercent计算出maxSurge(代表滚动更新时可超出deployment声明的副本数的最大值),最终根据maxSurge与现存pod数量计算出新的replicaset对象该拥有的副本数。
// pkg/controller/deployment/util/deployment_util.go
func NewRSNewReplicas(deployment *apps.Deployment, allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet) (int32, error) {
switch deployment.Spec.Strategy.Type {
case apps.RollingUpdateDeploymentStrategyType:
// Check if we can scale up.
maxSurge, err := intstrutil.GetValueFromIntOrPercent(deployment.Spec.Strategy.RollingUpdate.MaxSurge, int(*(deployment.Spec.Replicas)), true)
if err != nil {
return 0, err
}
// Find the total number of pods
currentPodCount := GetReplicaCountForReplicaSets(allRSs)
maxTotalPods := *(deployment.Spec.Replicas) + int32(maxSurge)
if currentPodCount >= maxTotalPods {
// Cannot scale up.
return *(newRS.Spec.Replicas), nil
}
// Scale up.
scaleUpCount := maxTotalPods - currentPodCount
// Do not exceed the number of desired replicas.
scaleUpCount = int32(integer.IntMin(int(scaleUpCount), int(*(deployment.Spec.Replicas)-*(newRS.Spec.Replicas))))
return *(newRS.Spec.Replicas) + scaleUpCount, nil
case apps.RecreateDeploymentStrategyType:
return *(deployment.Spec.Replicas), nil
default:
return 0, fmt.Errorf("deployment type %v isn't supported", deployment.Spec.Strategy.Type)
}
}
intstrutil.GetValueFromIntOrPercent
maxSurge的计算也不复杂,当maxSurge为百分比时,因为函数入参roundUp为true,所以计算公式为:maxSurge = ⌈deployment.Spec.Strategy.RollingUpdate.MaxSurge * deployment.Spec.Replicas / 100⌉(结果向上取整) ;
当maxSurge不为百分比时,直接返回其值。
// staging/src/k8s.io/apimachinery/pkg/util/intstr/intstr.go
func GetValueFromIntOrPercent(intOrPercent *IntOrString, total int, roundUp bool) (int, error) {
if intOrPercent == nil {
return 0, errors.New("nil value for IntOrString")
}
value, isPercent, err := getIntOrPercentValue(intOrPercent)
if err != nil {
return 0, fmt.Errorf("invalid value for IntOrString: %v", err)
}
if isPercent {
if roundUp {
value = int(math.Ceil(float64(value) * (float64(total)) / 100))
} else {
value = int(math.Floor(float64(value) * (float64(total)) / 100))
}
}
return value, nil
}
2.7.2 dc.reconcileOldReplicaSets
dc.reconcileNewReplicaSet主要作用是调谐旧的replicaset对象,根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxUnavailable和现存的Available状态的pod数量进行计算,决定是否对旧的replicaset对象进行缩容。
主要逻辑:
(1)获取旧的replicaset对象的副本数总数,如果是0,则代表旧的replicaset对象已经无法缩容,调谐完毕,直接return;
(2)调用deploymentutil.MaxUnavailable,计算获取maxUnavailable的值,即最大不可用pod数量(这里注意一点,当deployment滚动更新策略中MaxUnavailable与MaxSurge的配置值都为0时,此处计算MaxUnavailable的值时会返回1,因为这两者均为0时,无法进行滚动更新);
(3)根据MaxUnavailable的值、deployment的期望副本数、新replicaset对象的期望副本数、新replicaset对象的处于Available状态的副本数,计算出maxScaledDown即最大可缩容副本数,当maxScaledDown小于等于0,则代表目前暂不能对旧的replicaset对象进行缩容,直接return;
(4)调用dc.cleanupUnhealthyReplicas,按照replicaset的创建时间排序,先清理缩容Unhealthy的副本(如not-ready的、unscheduled的、pending的pod),具体逻辑暂不展开分析;
(5)调用dc.scaleDownOldReplicaSetsForRollingUpdate,根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxUnavailable计算出旧的replicaset对象该拥有的副本数量,调用dc.scaleReplicaSetAndRecordEvent缩容旧的replicaset对象(所以这里也可以看到,dc.cleanupUnhealthyReplicas与dc.scaleDownOldReplicaSetsForRollingUpdate均有可能会对旧的replicaset进行缩容操作);
(6)如果缩容的副本数大于0,则返回true,否则返回false。
// pkg/controller/deployment/rolling.go
func (dc *DeploymentController) reconcileOldReplicaSets(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) {
oldPodsCount := deploymentutil.GetReplicaCountForReplicaSets(oldRSs)
if oldPodsCount == 0 {
// Can't scale down further
return false, nil
}
allPodsCount := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
klog.V(4).Infof("New replica set %s/%s has %d available pods.", newRS.Namespace, newRS.Name, newRS.Status.AvailableReplicas)
maxUnavailable := deploymentutil.MaxUnavailable(*deployment)
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
newRSUnavailablePodCount := *(newRS.Spec.Replicas) - newRS.Status.AvailableReplicas
maxScaledDown := allPodsCount - minAvailable - newRSUnavailablePodCount
if maxScaledDown <= 0 {
return false, nil
}
// Clean up unhealthy replicas first, otherwise unhealthy replicas will block deployment
// and cause timeout. See //github.com/kubernetes/kubernetes/issues/16737
oldRSs, cleanupCount, err := dc.cleanupUnhealthyReplicas(oldRSs, deployment, maxScaledDown)
if err != nil {
return false, nil
}
klog.V(4).Infof("Cleaned up unhealthy replicas from old RSes by %d", cleanupCount)
// Scale down old replica sets, need check maxUnavailable to ensure we can scale down
allRSs = append(oldRSs, newRS)
scaledDownCount, err := dc.scaleDownOldReplicaSetsForRollingUpdate(allRSs, oldRSs, deployment)
if err != nil {
return false, nil
}
klog.V(4).Infof("Scaled down old RSes of deployment %s by %d", deployment.Name, scaledDownCount)
totalScaledDown := cleanupCount + scaledDownCount
return totalScaledDown > 0, nil
}
dc.scaleDownOldReplicaSetsForRollingUpdate
dc.scaleDownOldReplicaSetsForRollingUpdate主要逻辑是缩容旧的replicaset对象,主要逻辑如下:
(1)根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxUnavailable和现存的Available状态的pod数量,计算出totalScaleDownCount,即目前需要缩容的副本数;
(2)对旧的replicaset对象按照创建时间先后排序;
(3)遍历旧的replicaset对象,根据需要缩容的副本总数,缩容replicaset。
// pkg/controller/deployment/rolling.go
func (dc *DeploymentController) scaleDownOldReplicaSetsForRollingUpdate(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, deployment *apps.Deployment) (int32, error) {
maxUnavailable := deploymentutil.MaxUnavailable(*deployment)
// Check if we can scale down.
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
// Find the number of available pods.
availablePodCount := deploymentutil.GetAvailableReplicaCountForReplicaSets(allRSs)
if availablePodCount <= minAvailable {
// Cannot scale down.
return 0, nil
}
klog.V(4).Infof("Found %d available pods in deployment %s, scaling down old RSes", availablePodCount, deployment.Name)
sort.Sort(controller.ReplicaSetsByCreationTimestamp(oldRSs))
totalScaledDown := int32(0)
totalScaleDownCount := availablePodCount - minAvailable
for _, targetRS := range oldRSs {
if totalScaledDown >= totalScaleDownCount {
// No further scaling required.
break
}
if *(targetRS.Spec.Replicas) == 0 {
// cannot scale down this ReplicaSet.
continue
}
// Scale down.
scaleDownCount := int32(integer.IntMin(int(*(targetRS.Spec.Replicas)), int(totalScaleDownCount-totalScaledDown)))
newReplicasCount := *(targetRS.Spec.Replicas) - scaleDownCount
if newReplicasCount > *(targetRS.Spec.Replicas) {
return 0, fmt.Errorf("when scaling down old RS, got invalid request to scale down %s/%s %d -> %d", targetRS.Namespace, targetRS.Name, *(targetRS.Spec.Replicas), newReplicasCount)
}
_, _, err := dc.scaleReplicaSetAndRecordEvent(targetRS, newReplicasCount, deployment)
if err != nil {
return totalScaledDown, err
}
totalScaledDown += scaleDownCount
}
return totalScaledDown, nil
}
总结
deployment controller是kube-controller-manager组件中众多控制器中的一个,是 deployment 资源对象的控制器,其通过对deployment、replicaset、pod三种资源的监听,当三种资源发生变化时会触发 deployment controller 对相应的deployment资源进行调谐操作,从而完成deployment的扩缩容、暂停恢复、更新、回滚、状态status更新、所属的旧replicaset清理等操作。
其中deployment的扩缩容、暂停恢复、更新、回滚、状态status更新、所属的旧replicaset清理等操作都在deployment controller的核心处理方法syncDeployment里进行处理调用。
关于deployment更新这一块,deployment controller会根据deployment对象配置的更新策略Recreate或RollingUpdate,会调用rolloutRecreate或rolloutRolling方法来对deployment对象进行更新操作。
且经过以上的代码分析,可以看出,deployment controller并不负责deployment对象的删除,除按历史版本限制数需要清理删除多余的replicaset对象以外,deployment controller也不负责replicset对象的删除(实际上,除按历史版本限制数deployment controller需要清理删除多余的replicaset对象以外,其他的replicaset对象的删除由garbagecollector controller完成)。
deployment controller架构
deployment controller的大致组成和处理流程如下图,deployment controller对pod、replicaset和deployment对象注册了event handler,当有事件时,会watch到然后将对应的deployment对象放入到queue中,然后syncDeployment方法为deployment controller调谐deployment对象的核心处理逻辑所在,从queue中取出deployment对象,做调谐处理。
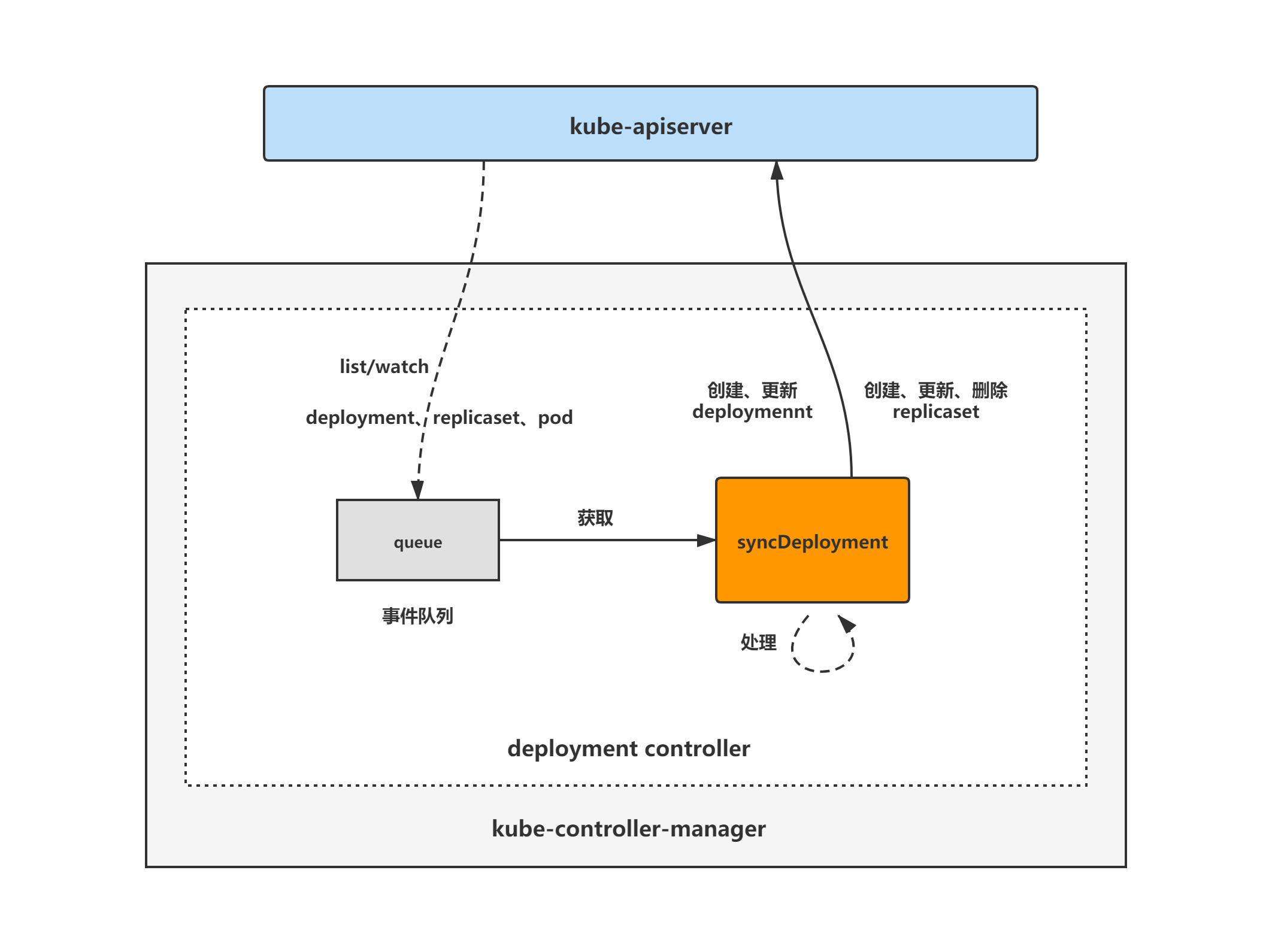
deployment controller核心处理逻辑
deployment controller的核心处理逻辑在syncDeployment方法中,下图即syncDeployment方法的处理流程。

deployment controller创建replicaset流程
无论deployment配置了ReCreate还是RollingUpdate的更新策略,在dc.rolloutRecreate或dc.rolloutRolling的处理逻辑里,都会判断最新的replicaset对象是否存在,不存在则会创建。
在创建了deployment对象后,deployment controller会收到deployment的新增event,然后会做调谐处理,在第一次进入dc.rolloutRecreate或dc.rolloutRolling的处理逻辑时,deployment所属的replicaset对象为空,所以会触发创建一个新的replicaset对象出来。
deployment ReCreate更新流程
(1)先缩容旧的replicaset,将其副本数缩容为0;
(2)等待旧的replicaset的pod全部都处于not running状态(pod的pod.Status.Phase属性值为Failed或Succeeded时代表该pod处于not running状态);
(3)接着创建新的replicaset对象(注意:新创建的replicaset的实例副本数为0);
(4)随后扩容刚新创建的replicaset,更新其副本数与deployment期望副本数一致;
(5)最后等待,直至deployment的所有pod都属于最新的replicaset对象、pod数量与deployment期望副本数一致、且所有pod都处于Available状态,则deployment更新完成。
deployment RollingUpdate更新流程
(1)根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxSurge和现存pod数量进行计算,决定是否对新的replicaset对象进行扩容以及扩容的副本数;
(2)根据deployment的滚动更新策略配置.Spec.Strategy.RollingUpdate.MaxUnavailable、现存的Available状态的pod数量、新replicaset对象下所属的available的pod数量,决定是否对旧的replicaset对象进行缩容以及缩容的副本数;
(3)循环以上步骤,直至deployment的所有pod都属于最新的replicaset对象、pod数量与deployment期望副本数一致、且所有pod都处于Available状态,则deployment滚动更新完成。
deployment滚动更新速率控制解读
先来看到deployment滚动更新配置的两个关键参数:
(1).Spec.Strategy.RollingUpdate.MaxUnavailable:指定更新过程中不可用的 Pod 的个数上限。该值可以是绝对数字(例如5),也可以是deployment期望副本数的百分比(例如10%),运算公式:期望副本数乘以百分比值并向下取整。 如果maxSurge为0,则此值不能为0。MaxUnavailable默认值为 25%。该值越小,越能保证服务稳定,deployment更新越平滑。
(2).Spec.Strategy.RollingUpdate.MaxSurge:指定可以创建的超出期望 Pod 个数的 Pod 数量。此值可以是绝对数(例如5),也可以是deployment期望副本数的百分比(例如10%),运算公式:期望副本数乘以百分比值并向上取整。 如果 MaxUnavailable 为0,则此值不能为0。 MaxSurge默认值为 25%。该值越大,deployment更新速度越快。
速记:配置百分比时,maxSurge向上取整,maxUnavailable向下取整
注意:MaxUnavailable与MaxSurge不能均配置为0,但可能在运算之后这两个值均为0,这种情况下,为了保证滚动更新能正常进行,deployment controller会在滚动更新时将MaxUnavailable的值置为1去进行滚动更新。
例如,当deployment期望副本数为2、MaxSurge值为0、MaxUnavailable为1%时(MaxUnavailable为百分比,根据运算公式运算并向下取整后,取值为0,这时MaxSurge与MaxUnavailable均为0,所以在deployment滚动更新时,会将MaxUnavailable置为1去做滚动更新操作),触发滚动更新后,会立即将旧 replicaSet 副本数缩容到1,并扩容新的replicaset副本数为1。待新 Pod Available后,可以继续缩容旧有的 replicaSet副本数为0,然后扩容新的replicaset副本数为2。滚动更新期间确保Available可用的 Pods 总数在任何时候都至少为1个。
例如,当deployment期望副本数为2、MaxSurge值为1%、MaxUnavailable为0时(MaxSurge根据运算公式运算并向上取整,取值为1),触发滚动更新后,会立即扩容新的replicaset副本数为1,待新pod Available后,再缩容旧replicaset副本数为1,然后再扩容扩容新的replicaset副本数为2,待新pod Available后,再缩容旧replicaset副本数为0。滚动更新期间确保Available可用的 Pods 总数在任何时候都至少为2个。
更多示例如下:
// 2 desired, max unavailable 1%, surge 0% - should scale old(-1), then new(+1), then old(-1), then new(+1)
// 1 desired, max unavailable 1%, surge 0% - should scale old(-1), then new(+1)
// 2 desired, max unavailable 25%, surge 1% - should scale new(+1), then old(-1), then new(+1), then old(-1)
// 1 desired, max unavailable 25%, surge 1% - should scale new(+1), then old(-1)
// 2 desired, max unavailable 0%, surge 1% - should scale new(+1), then old(-1), then new(+1), then old(-1)
// 1 desired, max unavailable 0%, surge 1% - should scale new(+1), then old(-1)


